前言:基于人大的《数据科学概论》第十二章。主要内容为Hadoop简介、Hadoop分布式文件系统、MapReduce工作原理、Hadoop生态系统、Hadoop2.0、Hadoop2.0在交互式查询引擎、Hadoop平台上的列存储。
文章目录
一、Hadoop简介
简说:Apache Hadoop是存储和处理大数据的开源软件框架。它在普通服务器组成的大规模集群上,对大数据进行分布式处理。
Hadoop软件框架,包含如下主要模块:
- Hadoop Common,这个模块包含了其他模块需要的库函数和实用函数。
- Hadoop Distributed File System(HDFS),这是在由普通服务器组成的集群上运行的分布式文件系统,支持大数据的存储,通过多个节点的并行I/O,提供极高的吞吐能力。
- Hadoop MapReduce,是一种支持大数据处理的编程模型。
- Hadoop YARN,这是Hadoop2.0的基础模块,它本质上是一个资源管理和任务调度软件框架。它把集群的计算资源管理起来,为调度和执行用户程序提供资源的支持。

二、Hadoop分布式文件系统
Hadoop分布式文件系统(Hadoop Distributed File System,简称HDFS),是一个分布式的、高度可扩展的文件系统,它是模仿GFS(Google File System)的开源软件实现。
- 一个HDFS集群,一般由一个NameNode和若干个DataNode组成(主从架构),分别负责元信息的管理(每个文件的数据块所在的DataNode的对应关系)和数据块的管理。
- HDFS支持TB级甚至PB级大小文件的存储,它把文件划分成数据块(Block,大小64MB),分布到多台机器进行存储。
- 为了保证系统的可靠性,HDFS把数据块在多个节点上进行复制。一般复制3份,多副本存放于本机、同机架、另外一个机架。

2.1HDFS特点
- 高度扩展性
- 高度容错性
2.2文件写入的过程
- 客户端程序调用HDFS的create()方法
- HDFS想NameNode发起一个远程过程调用,由其在其文件系统的命名空间里,创建一个新文件。这时,该文件还没有任何数据块。
- 当客户端开始写入数据,DFSOutputStream把数据分解成数据包,并且写入一个内部队列,称为数据队列。
- 第二个DataNode保存这个数据包,并且转发给第三个(最后一个)DataNode。
- DFSOutputStream同时维护一个数据包的内部队列,用于等待接收DataNode的应答信息,称为ACk Queue。
- 当客户端程序完成数据写入,它调用数据流的close()方法。
- 客户端把所有剩余的数据包发送到DataNode流水线上,并且等待应答信息,最后联系NameNode,告诉它文件结束。

2.3文件的读取过程
- 客户端程序通过调用FileSystem对象的open()方法,打开文件,获得Distributed FileSystem类的一个实例。
- DistributedFileSystem 通过RPC调用NameNode,获得文件开始若干数据块的位置信息(Locations of Blocks)。对于每个数据块来讲,NameNode会返回拥有这个数据块的副本的所有DataNode的地址。
- 客户端程序从输入流上调用函数read()。由于DFSInputStream已经保存了文件开始若干数据块所在的DataNode的地址,DFSInputStream连接到最近的(Closest)DataNode,读取文件的第一个数据块。
- 数据从DataNode源源不断传送回客户端程序,而客户端程序则不断地调用数据流的read()方法。
- 当到达数据块的末尾的时候,DFSInputStream将关闭到DataNode的连接,然后寻找下一个数据块的最优的DataNode,以便进行后续数据块的读取。DataNode的选择对客户端程序来讲是透明的,客户端程序只是从一个连续的数据流进行读取。
- 客户端按照顺序读取各个数据块。当客户端不断读取数据流的时候,在数据块的边界,DFSInputStream不断创建到保存其它数据块的DataNode的连接。DFSInputStream同时向NameNode询问和提取,下一批数据块的DataNode的位置信息。
- 当客户端完成文件的读取,它调用FSDataInputStream实例的close()方法。

2.4Secondary NameNode介绍
- NameNode集中存储了HDFS的元信息
- 由于NameNode如此重要,所以我们需要采取措施,保证NameNode能够从失败中恢复。
- NameNode维护的两个本地磁盘文件:命名空间镜像文件和编辑日志文件。
- Secondary NameNode保存了NameNode的Fslmage文件和EditLog文件的副本。每隔一段时间(缺省为一个小时),它从NameNode拷贝元信息的映像文件,并且把映像文件和日志文件进行合并,然后把映像文件复制回NameNode,以便NameNode获得更新的元信息映像文件。
- 假设NameNode发生宕机状况,我们可以启动其他的机器,从Secondary NameNode获得元信息映像文件和日志文件,可以恢复出发生宕机之前的最新的元信息,于是我们可以把这台机器当做新的NameNode来使用
三、MapReduce工作原理
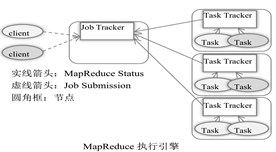
3.1MapReduce执行引擎
MapReduce执行引擎运行在分布式文件系统HDFS之上,它包括JobTracker和TaskTracker两个主要的组成部分,分别运行在NameNode和DataNode上。
- 用户提交的数据处理请求,称为一个作业(Job)
- 由JobTracker分解为数据处理运行任务(Task),分发给集群里的相关节点上的TaskTracker运行。
- 在HDFS里,JobTracsk通过HDFS NameNode,知道哪些节点包含将要处理的各个数据块,也就是它了解数据块的存放位置。如果任务不能发送到数据块所在的节点,那么系统优先把任务推送到同一机架里的其他节点,该节点保留了数据块的另外一个副本。
- 如果TaskTracker失败或者运行超时,它负责的任务被重新调度到其他的TaskTracker上的网络流量。
- 在TaskTracker运行过程中,它向JobTracker每隔几分钟发送一个心跳信号,以便报告它的存活状态。
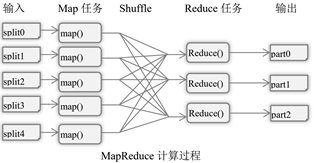
3.2MapReduce计算模型
在MapReduce计算模型中,数据以键值对(<key,value>)进行建模。MapReduce并行编程模型把计算过程分解为两个主要阶段,即Map阶段和Reduce阶段。
- 首先,保存在HDFS里的文件即数据源,已经进行分块。这些数据块交给多个Map任务去执行,Map任务执行Map函数,根据特定规则对数据处理,写入本地磁盘。
- Map阶段完成后,进入Reduce阶段,Reduce任务执行Reduce函数,具有同样Key值的中间结果,从多个Map任务所在的节点,被收集到一起进行约减处理,输出结果写入本地硬盘(分布式文件系统)。程序的最终输出结果,可以通过合并所有Reduce任务的输出得到。
- Map函数处理Key/Value对,产生一系列的中间Key/Value对。Reduce函数用来合并所有具有相同Key值的中间键值对,计算最终结果。
一个栗子----单词统计
- Map函数的功能是,对文件块出现的每个单词输出<单词,1>的键值对。
- 而Reduce函数,则把各个Map函数输出的结果,按照单词进行分类,统计其出现的次数。

3.3Hadoop1.0的应用
- 除了简单的SQL汇总以外,研发人员已经把OLAP、数据挖掘、机器学习、信息检索、多媒体处理、科学数据处理、图数据处理等复杂的数据处理和分析算法,移植到Hadoop平台上。
- Hadoop不仅仅是一个处理非结构化数据的工具,当数据按照一定格式进行组织以后,Hadoop平台也可以处理费结构化数据。
- Hadoop平台,及Hadoop上的各种工具构成了一个生态系统,完成各种大数据集的处理。
四、Hadoop生态系统
在分布式文件系统HDFS和MapReduce计算模型之上,若干工具一起构成了整个Hadoop生态系统。
Hive是Hadoop平台上的数据仓库,用于对数据进行离线分析HBase是Google Big Table在Hadoop平台上的开源实现。一般用于数据服务应用场合。Pig实现了数据查询脚本语言Pig Latin。Flume是一个可扩展的、高度可靠的、高可用的分布式海量日志收集系统,一般用于把众多服务器上的大量日志,聚合到某一个数据中心。Sqoop是SQL to Hadoop的缩写,主要用于在关系数据库或者其他结构化数据源和Hadoop之间交换数据。Mahout是Hadoop平台上的机器学习软件包,它的主要目标是实现高度可扩展的机器学习算法,以便帮助开发人员在大数据上运行机器学习软件。Oozie是一个工作流调度器- Zookeeper是对Google的Chubby系统的开源实现,Chubby是一个分布式的锁服务。
- Scribe是Facebook开发的开源的分布式日志搜集系统。

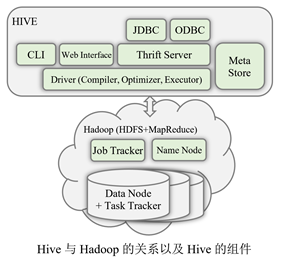
1、Hive原理
Hive是基于Hadoop的一个数据仓库系统。它将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能。Hive把Hive Query Language(HQL,类似于SQL的查询语言),所编写的语句,转换为MapReduce作业(Job),然后在Hadoop平台上运行。
(1)Hive的特点
- 使用Hadoop的HDFS分布式文件系统存储数据库数据
- 使用MapReduce计算模型实现查询处理
- Hive的设计目的是对海量数据进行分析处理
- 基于Hadoop平台,Hive具有很强大的扩展能力,可以很容易地对存储能力和计算能力进行扩展。
- Hive在数据加载的时候,无需进行模式检查,在读取数据的时候,再对数据以一定的模式进行解释,称为“读时模式”。
(2)Hive组件
- Hive的服务端组件包括:
- Driver
- 元信息管理器MetaStore
- Thrift Server服务器
- Hive的客户端组件包括:
- 命令行接口CLI
- Thrift客户端
- WEb GUI图形用户界面
Hive支持的数据类型,包括整形、浮点型、双精度浮点型以及字符串等。Hive还支持更加复杂的数据类型,包括映射、列表和结构。这些复杂类型可以通过嵌套,表达更加复杂的类型。
Hive的数据模型包括几个主要的管理层次,分别是数据库、表格、分区、桶等
五、Hadoop2.0版(YARN)
5.1Hadoop1.0的优势和局限
Hadoop的优势是他的可扩展性。在实际应用中,Hadoop已经被部署到超大规模的集群上,对于传统的RDBMS来讲,是无法想象的。
对于Hadoop1.0来讲,主要的局限包括:
- 它仅仅支持一种计算模型,即MapReduce。
- 由于MapReduce作业在Map阶段和Reduce阶段执行过程中,需要把中间结果存盘。通过磁盘进行数据交换,效率低下,影响了查询的执行效率。
- Hadoop1.0的任务调度方法,远未达到优化资源利用率的效果。也就是没有考虑整个集群的状况。
5.2YARN原理
Hadoop YARN 是Hadoop 2.0的最重要的组成部分
- YARN把资源管理(Resource Management)和作业调度/监控(Job Scheduling/Monitoring)模块分开
- 由于引入了YARN,在Hadoop2.0中,系统可以支持更多的计算模型,包括流数据处理、图数据处理、批处理、交互式处理等。

Hadoop 2.0的主要组件及其关系
- 在新的架构里,包含ResourceManager和NodeManager两个重要的组件。
- ResourceManager运行在Master节点上,NodeManager运行在Slave节点上,一起负责分布式应用程序的调度和运行。


5.3YARN的优势
- 扩展性
- 更高的集群使用效率
- 兼容Hadoop1.0
- 支持更多的应用负载类型
- 灵活性
六、Hadoop2.0上的交互式查询引擎Hive on Tez
6.1Tez的提出
6.2把数据处理逻辑建模构成一个DAG连接起来的任务
6.3Tez(DAG)相对于MapReduce(Jobs)的优势
七、Hadoop平台上的列存储技术
7.1列存储的优势
在分析型应用中,列存储技术具有若干明显的优势
- 读取数据的时候,可以把投影下推,只需要读取查询需要额的列,可以大大减少每次查询的I/O数据量,甚至可以支持谓词下推,跳过不满足条件的行。
- 由于每一列中的数据类型相同,可以使用针对性的编码和压缩方法对数据进行压缩,大大降低数据存储空间。
- 由于每一列的数据类型相同,可以使用更加适合CPU Pipeline的编码方式,减小CPU的缓存失效(Cache Miss)
7.2 RCFile
RCFile(Record Columnar File Format)文件格式,第一次在Hadoop中引入列存储格式,Hive数据仓库因此提高了数据分析的性能。
为了把表格中的数据保存到文件中,RCFile首先横向分割表格,然后纵向分割表格。对表格的横向分割,把表格划分成多个行组(Row Group),行组的大小可以由用户进行指定。在每个Row Group内部,RCFile按照列存储的一般做法,把各个列数据分开,分别连续保存。
7.3 ORC File(Optimized Row Columnar File)存储格式
ORC File是对RCFile做出优化的一种存储格式。和RCFile想比,ORC文件格式具有若干优势:
- ORC File支持更加丰富的数据类型
- ORC File是一个自描述的、和类型感知的列存储文件格式。它为流式读取操作,进行了优化,同时支持快速查找少数的数据行
- ORC File引入了轻量级的索引,以及基本的统计信息,于是在查询的处理过程中,可以忽略大量不符合查询条件的记录。
- 通过谓词下推(Predicate Pushdown),查询处理器使用这些索引,确定哪些Stripe(将介绍)需要读取,并且利用Row Index(将介绍),进一步限定扫描的范围到最小由10000行构成的记录集合
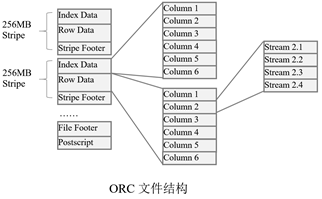
ORC File文件结构
- 每个Stripe包括索引数据(Index Data)、行数据(Row Data)、及一个Stripe Footer。
- 在File Footer里面,包含了该ORC File文件中所有Stripe的元信息,即每个Stripe的位置、每个Stripe中有多少行、以及每列的数据类型等。它里面还包含了列级别的一些聚集结果,比如记录数(Count)、最小值(Min)、最大值(Max)、总和(Sum)等。
- 有一个称为Postscript的结构。它用来存储压缩参数、及Footer的长度(被压缩过的Footer的大小)。
7.4Parquet文件格式
Parquet也是Hadoop平台上的一种列存储格式
它兼容各种数据处理框架、对象模型,支持各种查询引擎(Hive、Impala、Presto等),与编程语言无关。
(1)Parquet数据模型
嵌套的数据模型和树结构


一个数据模式的树结构有几个叶子节点,实际的存储中就会有多少列。于是,上述实例中的AddressBook数据模式,在存储上,共有四个列。
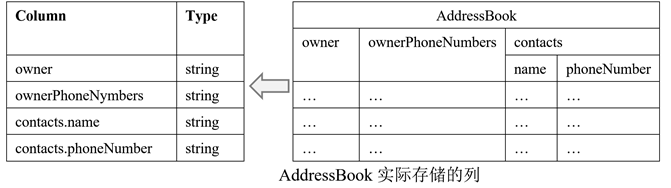
(2)Parquet文件结构
- HDFS文件(File):一个HDFS文件,包括数据和元数据。数据存储在多个Block中。
- HDFS数据块(Block):它是HDFS上最小的存储单位。
- 行组(Row Group):按照行,将数据(表格)物理上划分为多个单元。每一个行组,包含一定的行数。
- 列块(Column Chunk):在一个行组中,每一列保存在一个列快中。一个列快由多个页组成。
- 页(Page):每一个列块,划分为多个页,页是压缩和编码的单元。在同一个列块内的不同页,可以使用不同的编码方式。
(3)面向列存储的数据压缩算法和查询处理
-
数据压缩:由于列式存储同一列的数据类型是一致的,可以使用不同的压缩算法
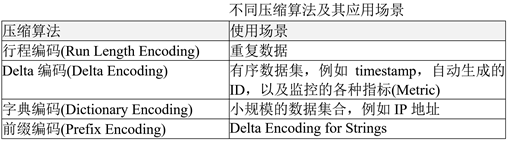
-
谓词下推:在数据库系统中,最常用的查询优化手段之一是谓词下推。通过将一些过滤条件尽可能地尽快执行,可以减少查询计划后续需要处理的数据量,从而提升性能。 -
映射下推:对于列存储来讲,映射下推是其最突出的优势。在获取表中的数据的时候,只需要扫描查询中需要的列。由于避免了不必要的数据列的提取,查询的效率得到提高。
7.5列存储的性能
Hadoop生态圈涌现出一系列列存储格式,包括RC File、ORC、Parquet等,他们来带了下面的优点:
- 更高额的压缩比,由于相同类型的数据连续存放,可以针对不同类型的列,使用高效的编码个压缩方式。
- 更小的I/O操作,由于映射下推和谓词下推技术的使用,可以减少大部分不必要的数据扫描,由此带来更好的查询性能。
- 使用不同存储格式
候,只需要扫描查询中需要的列。由于避免了不必要的数据列的提取,查询的效率得到提高。
7.5列存储的性能
Hadoop生态圈涌现出一系列列存储格式,包括RC File、ORC、Parquet等,他们来带了下面的优点:
- 更高额的压缩比,由于相同类型的数据连续存放,可以针对不同类型的列,使用高效的编码个压缩方式。
- 更小的I/O操作,由于映射下推和谓词下推技术的使用,可以减少大部分不必要的数据扫描,由此带来更好的查询性能。
- 使用不同存储格式
- 查询性能提高了