Series,DataFrame
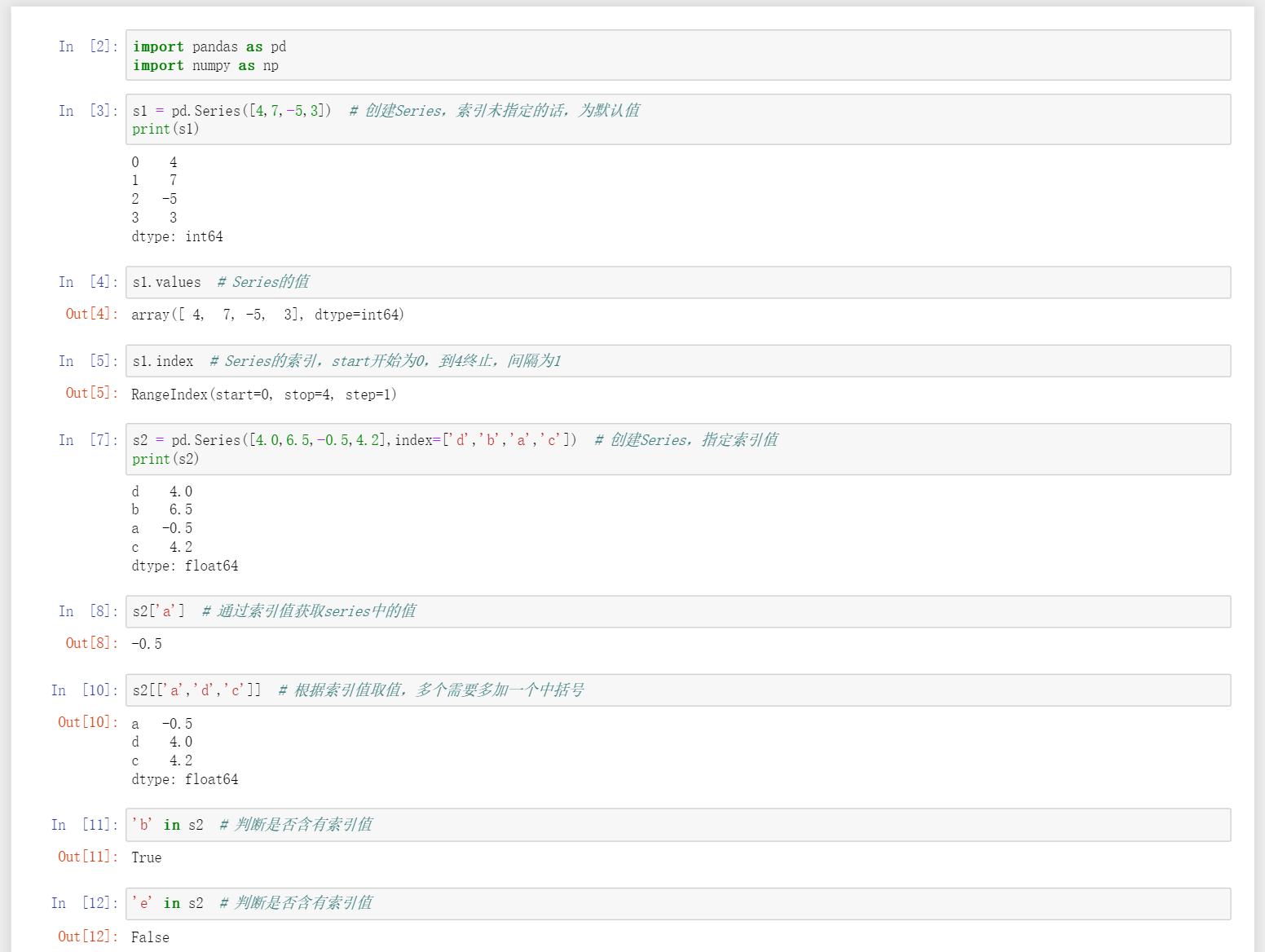
Series可以看成一个定长的有序字典
一下默认import pandas as pd
-
pd.Series([x,x,x,x])# 创建Series,索引未指定的话,为默认值 -
pd.Series([x,x,x,x],index=['a','b','c','d'])创建Series,指定索引值 -
Series.values查看Series的值和数据类型 -
Series.index查看Series的索引值start开始为0,到4终止,间隔为1 -
Series['a']获取指定的索引的值 -
Series[['a','b','c']]# 根据多个索引值取多个值,多个需要多加一个中括号 -
'a' in Series判断Series中是否含索引为a的值,有则返回True,无则返回False -
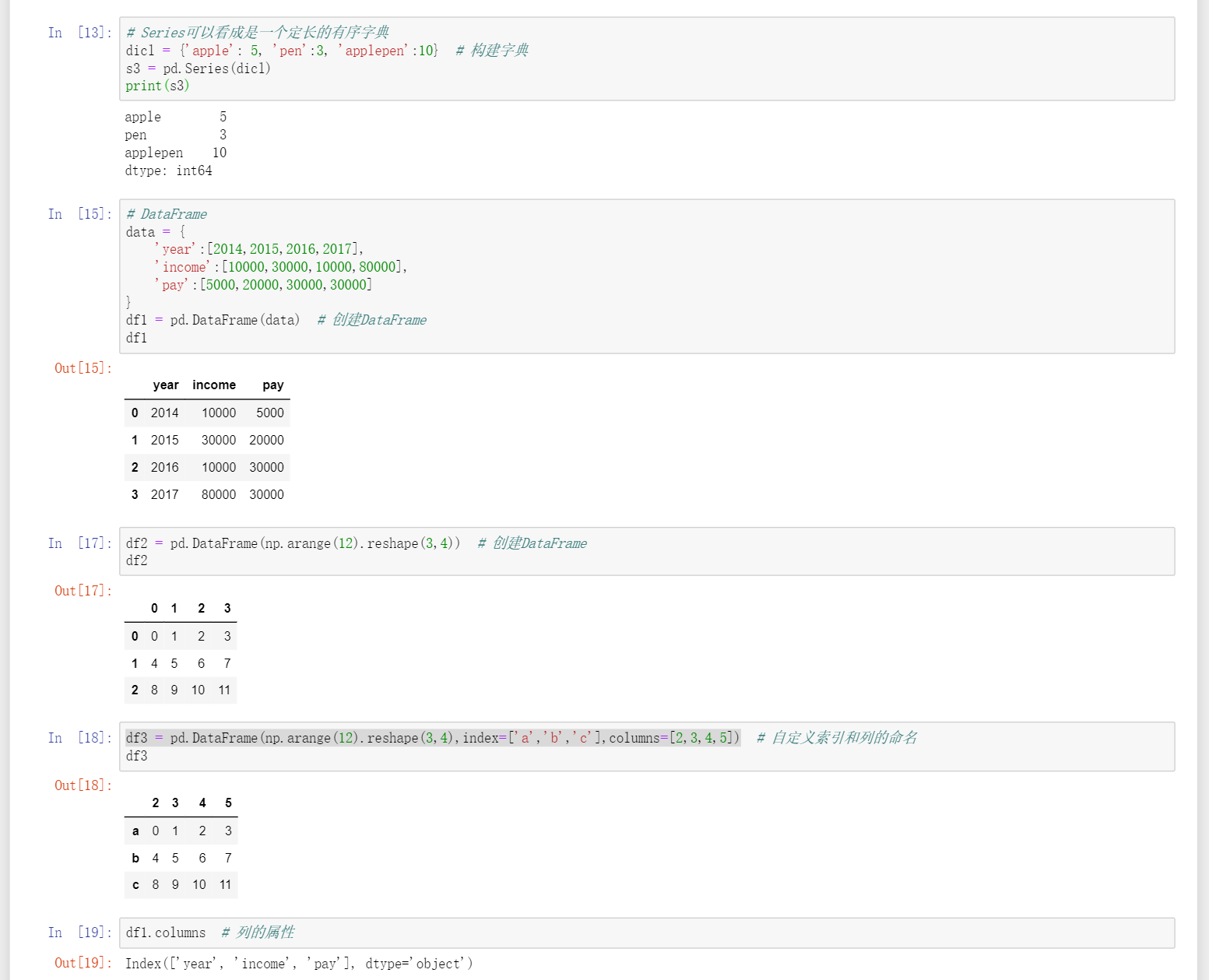
pd.Series(dictionary)dictionary为字典,可直接将字典传入Series中,key值转成index,value仍是value
DataFrame是可包含不同类型的列的二维标记(label)数据结构
-
pd.DataFrame(dictionary)DataFrame可直接转入python的字典,形成列表,key值为columns,value仍是value,未指定index默认从0开始索引 -
pd.DataFrame(np.arange(12),reshape(3,4))形成一个3行4列含有12个value的DataFrame,其中index和columns都是默认值 -
pd.DataFrame(np.arange(x),reshape(a,b),index=['a','b','c'],columns=['1','2','3'])创建DataFrame指定索引值 -
DataFrame.columns查看DataFrame中的列属性 -
DataFrame.index查看DataFrame中的行属性 -
DataFrame.value查看DataFrame中的值 -
DataFrame.describe()查看DataFrame中的各种属性,含有数量count,平均值mean,方差std,最小值min,最大值max等 -
DataFrame.TDataFrame转置 -
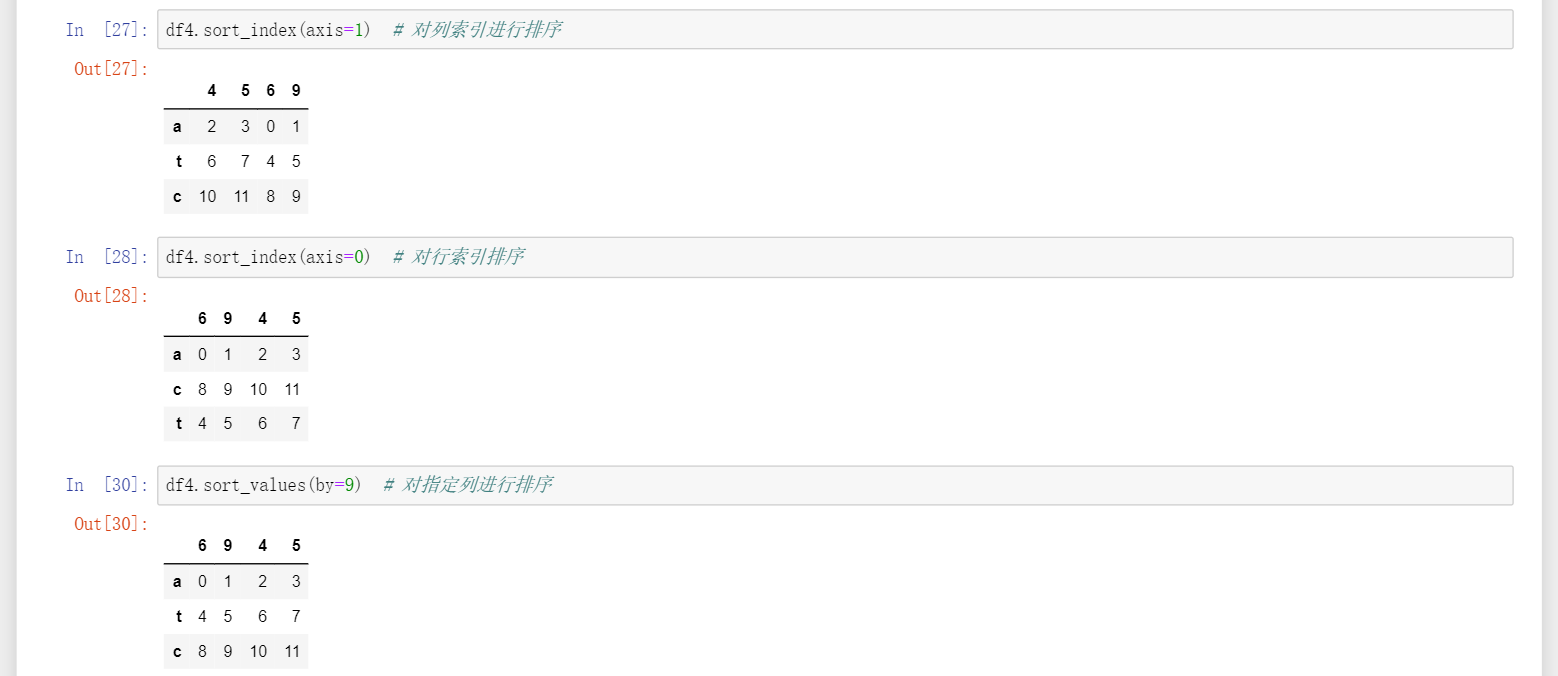
DataFrame.sort_index(axis=1/0)对索引排序,其中axis=0则对行索引排序,axis=1则对列索引排序 -
DataFrame.sort_value(by=x,ascending=True)对x列的value排序,ascending设置升序或是降序,多行排序要加[]

Pandas数据选择
-
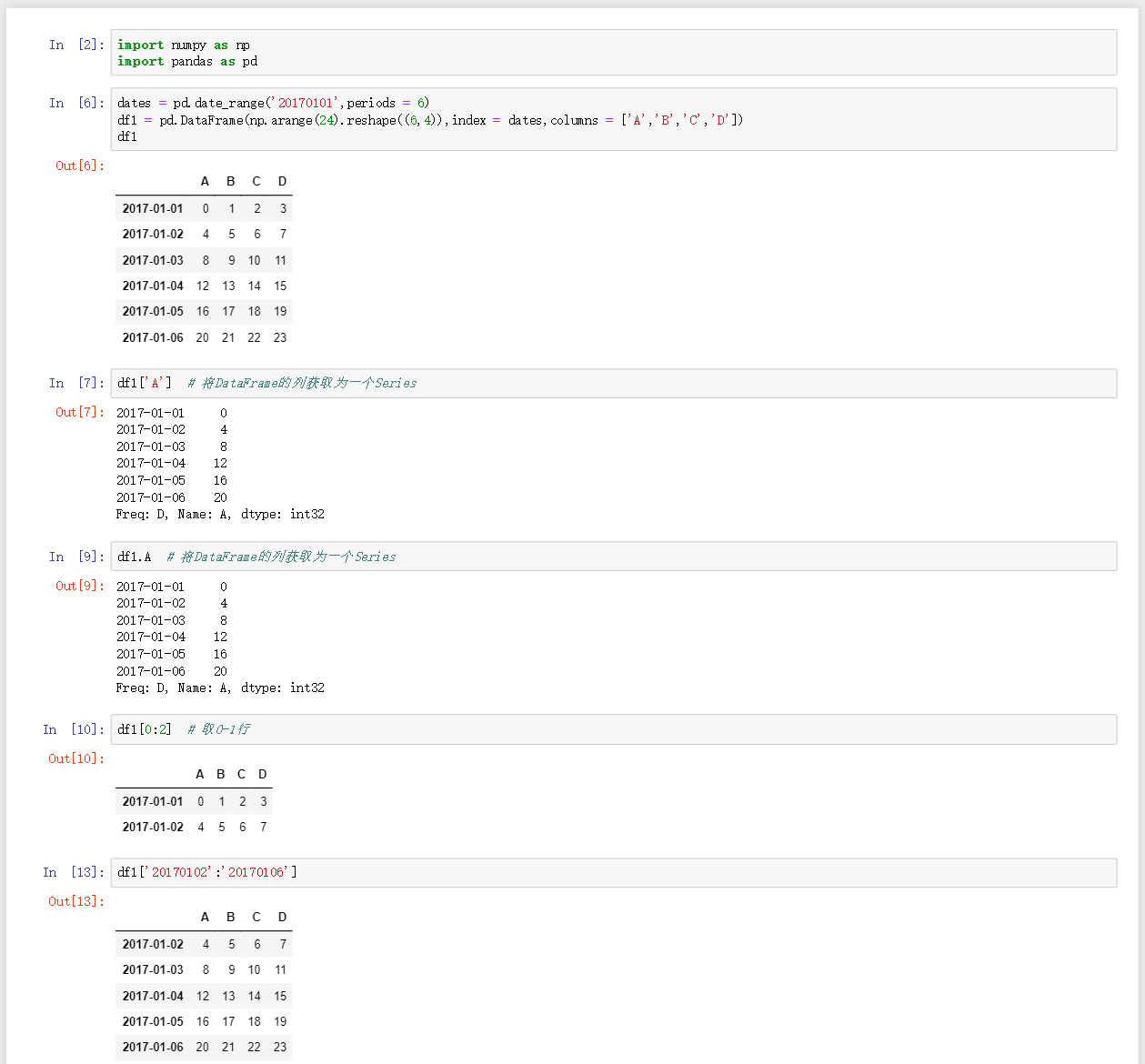
df.['a']获取索引值为a的列数据 -
df.a获取索引值为a的列数据,作用同上 -
df[0:2]获取0-1行的数据 -
df['a':'b']获取a行到b行的数据 -
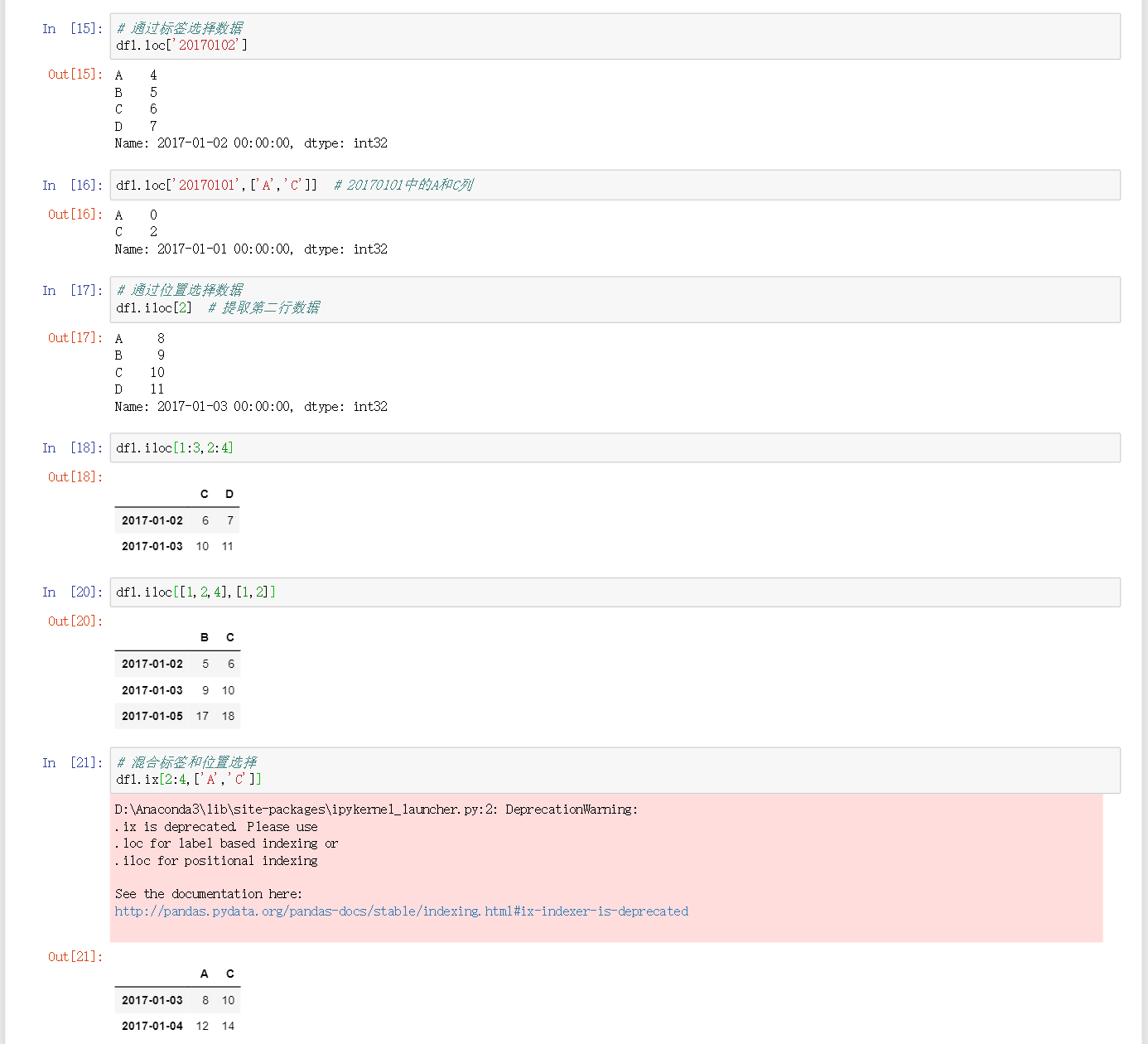
df.loc['a']通过标签获取数据,获取a行是数据 -
df.loc['a',['b','c']]获取a行中列为b、c的数据 -
df.iloc[2]提取第2行的数据 -
df.iloc[1:3,2:4]获取第索引值为1到2的行,2到3的列的数据 -
df.iloc[[1,2,4],[2,4]]获取索引值为1、2、4的行和索引值为2、4的列的数据 -
df.ix[2:4,['A','C']]获取索引值2到3行A和C列的数据 -
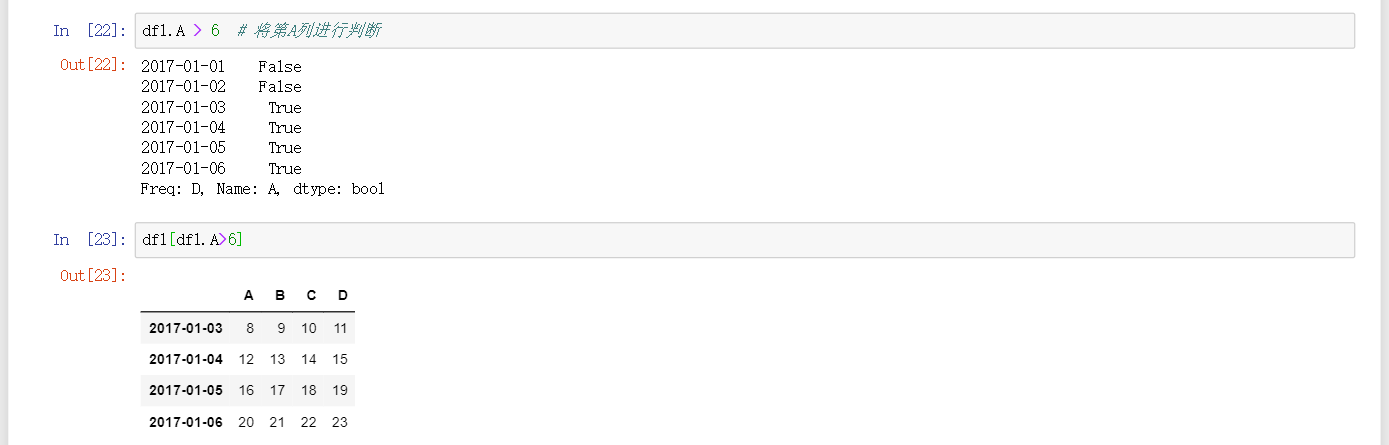
df.A > b判断索引值为A列中大于b的数据,返回true或false -
df[df>b]查看df中大于b的数字返回表格
Pandas赋值及操作
-
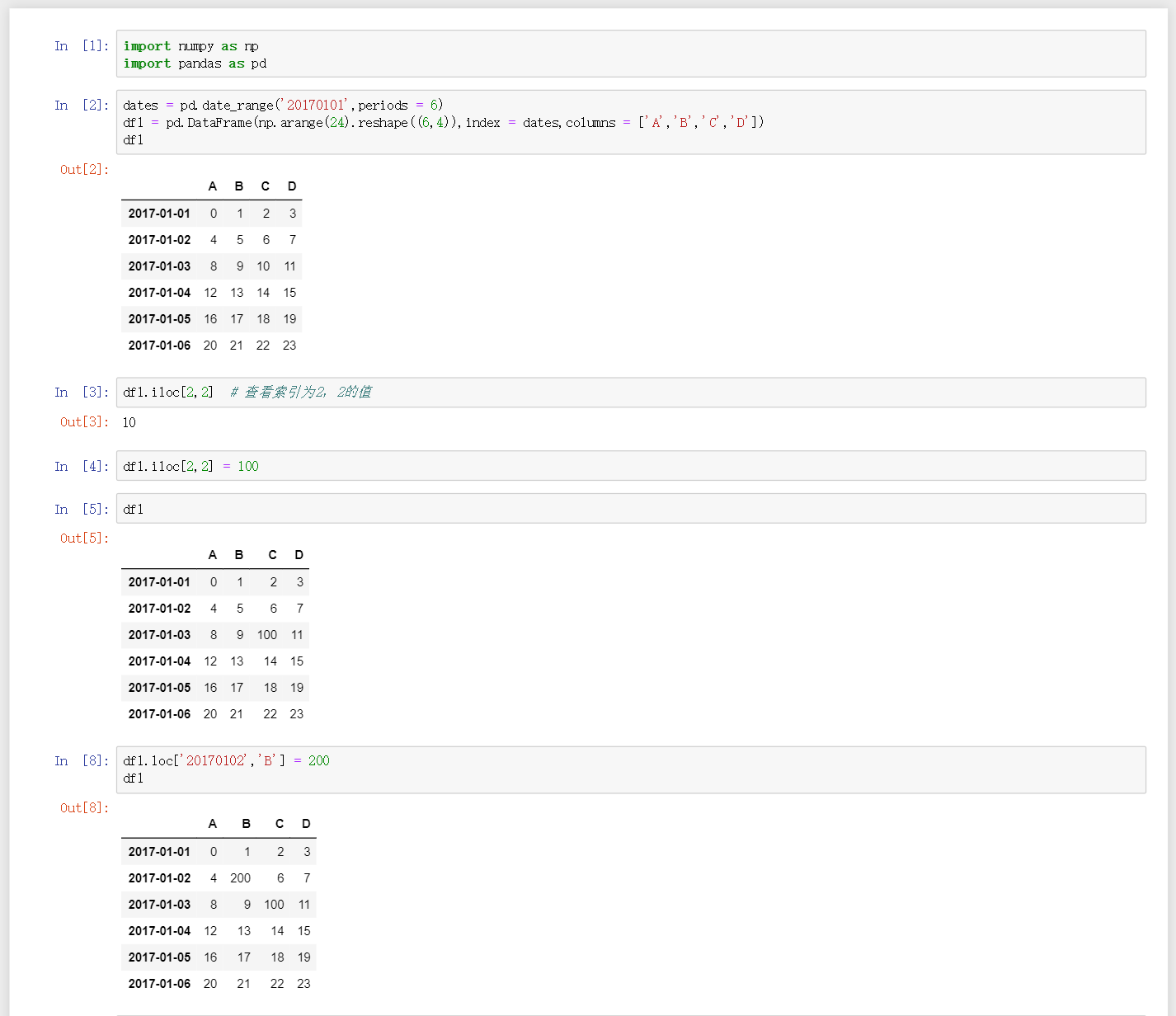
df.iloc[a,b]查看索引值为a,b的值 -
df.iloc[a,b] = c将所以这种为a,b中的值改为c -
df.loc['a','B'] = c将标签为a的行和标签为B的列的值改为c -
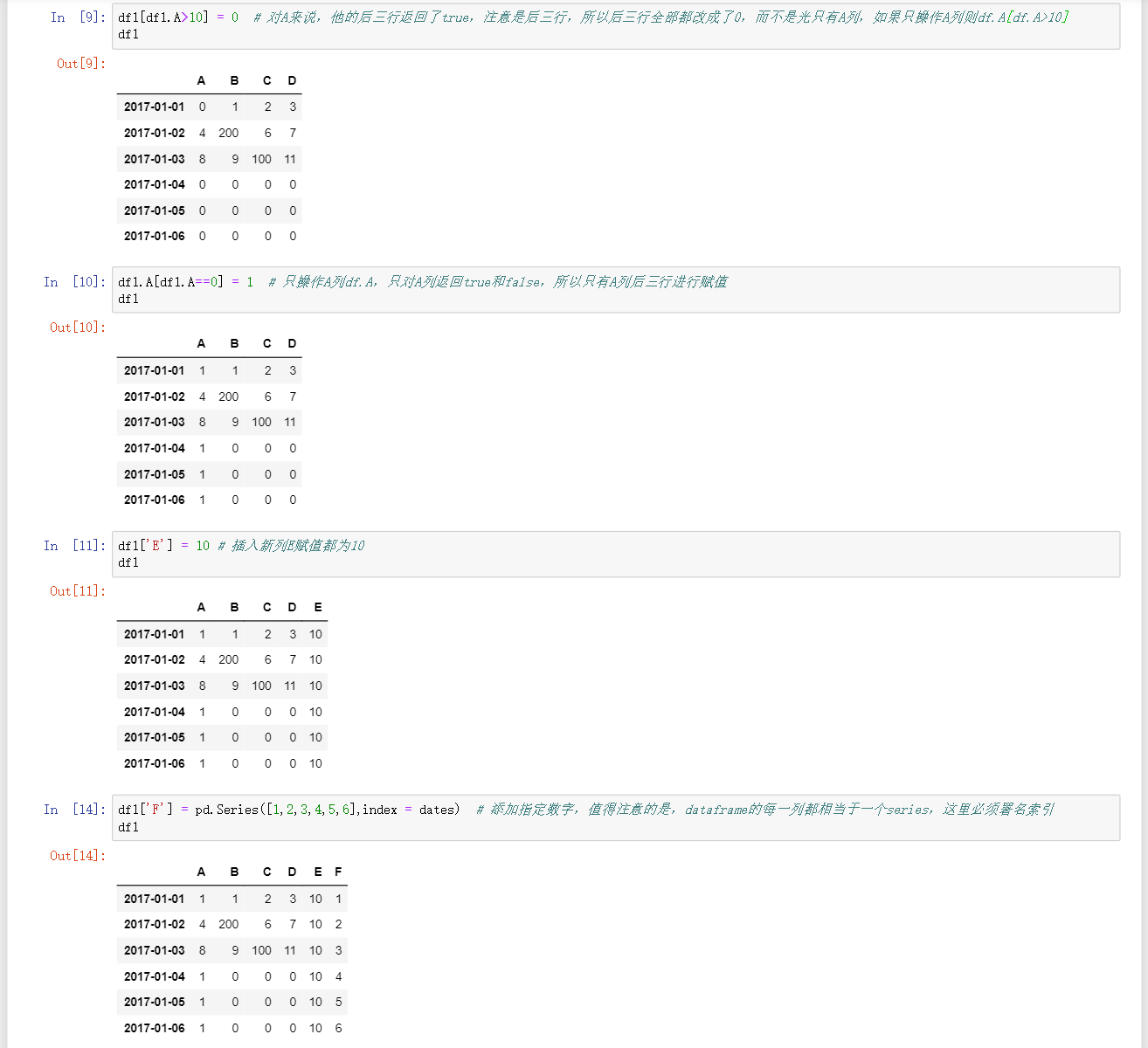
df[df.A>10] = c对A列来说,他的某行行返回了true,注意是某行,所以后某行全部都改成了0,而不是光只有A列,如果只操作A列则df.A[df.A>10] -
df.A[df.A == 0]只操作A列df.A,只对A列返回true和false,所以只有A列赋值 -
df['E'] = 10插入E列都为10 -
df['F'] = pd.Series([1,2,3,4,5], index = xx)添加指定数字,值得注意的是,dataframe的每一列都相当于一个series,这里必须署名索引 -
df.loc['20170107',['A','B','C']] = [a,b,c]添加行名为20170107的行,列标签为A、B、C的赋值a、b、c -
df = df.append(Series)将一个Series加到df后面 -
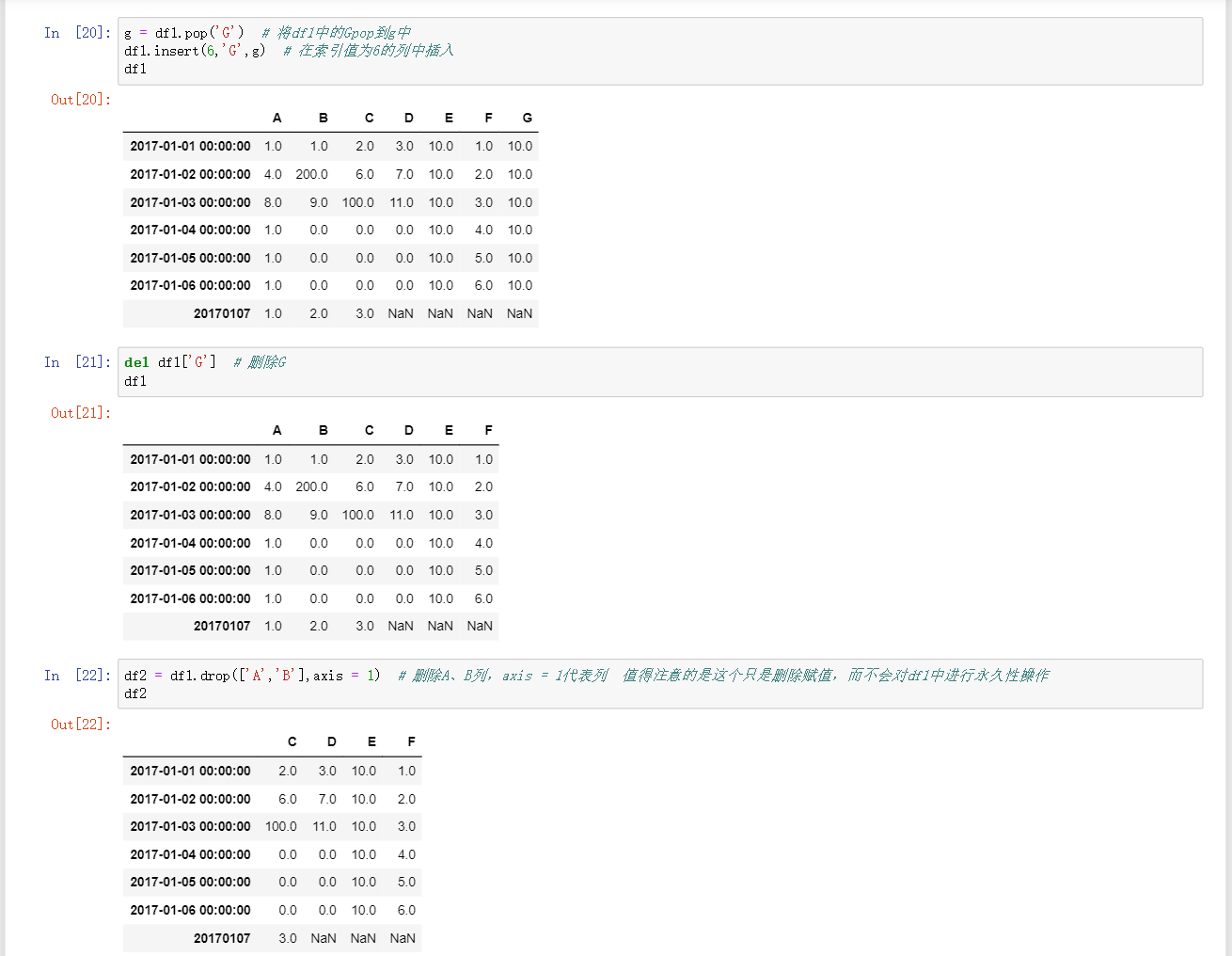
df.insert(1,'a',df['b'])在索引值为1的地方插入列a,数据为df中的b列 -
x = df.pop('a')将标签为a的数据pop到x中 -
del df.A删除A列 -
df = df.drop(['A','B'],axis = 1)删除A、B列,axis = 1代表列 值得注意的是这个只是删除赋值,而不会对df1中进行永久性操作 -
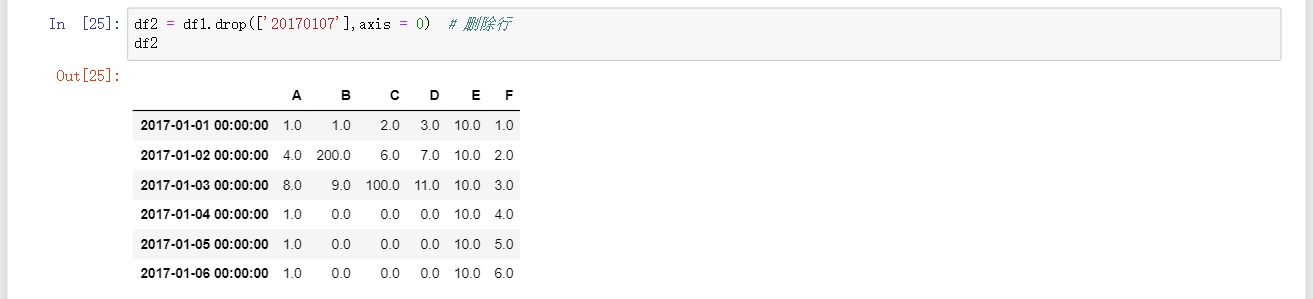
df = df.drop(['b'],axis = 0)删除行

Pandas丢失数据处理
-
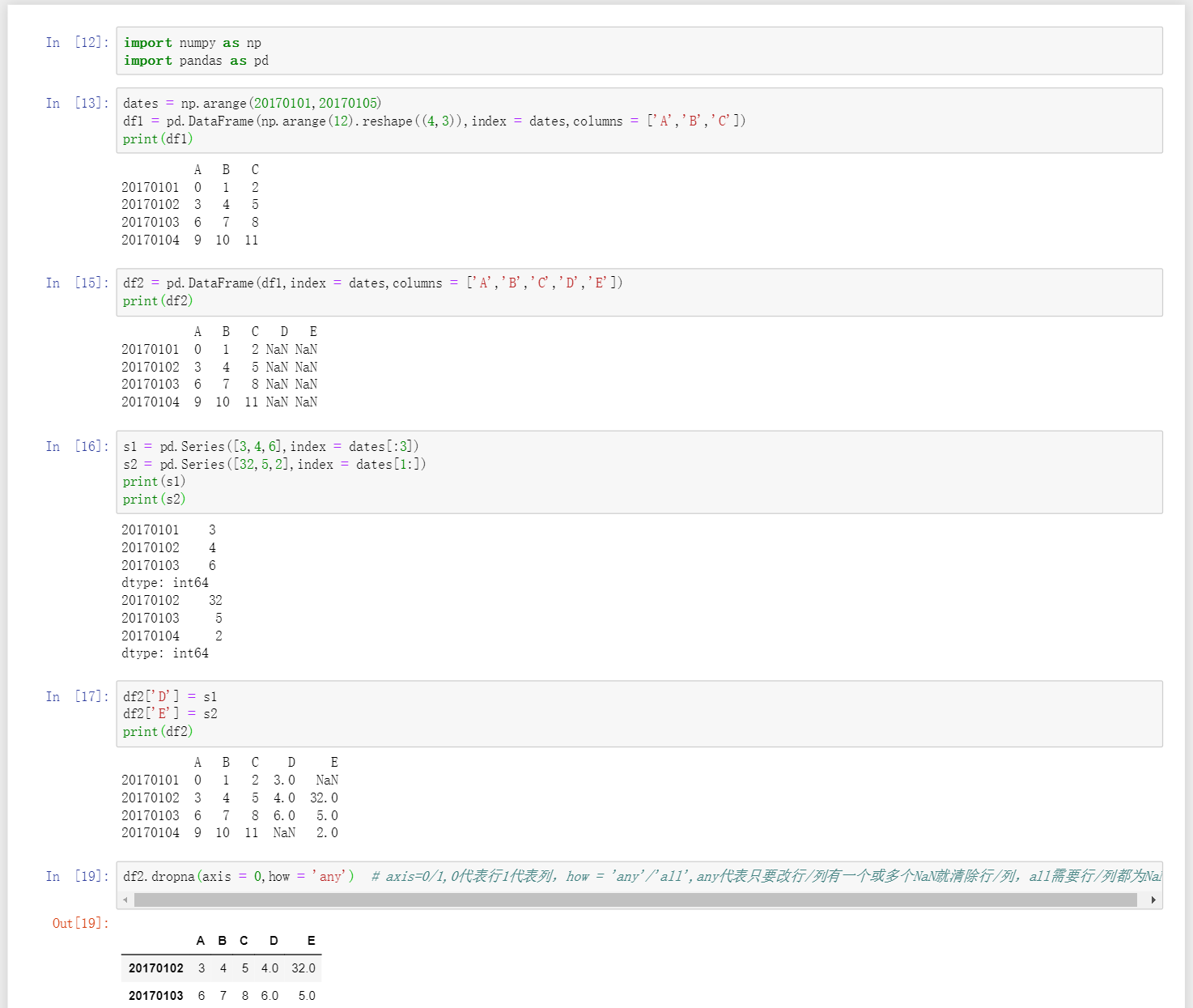
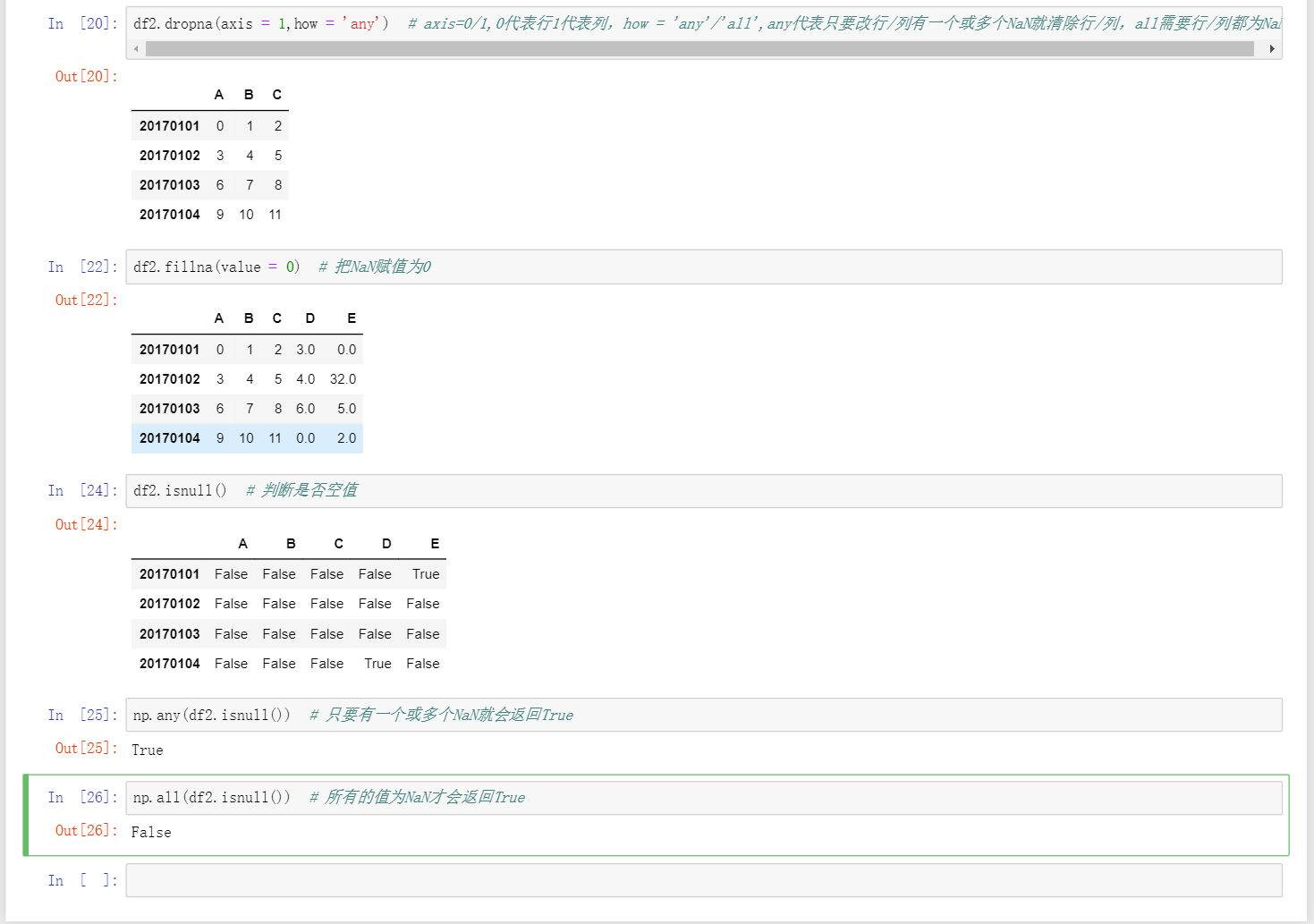
df.dropna(axis = 0/1, how = 'any'/'all')当how为any时,只要该行或列有一个或多个NaN时就会删除该行或列,当为all时,需要该行或列全部都为NaN时才会删除该行或列 -
df.fillna(value = a)将df中所有为NaN的数据都填如a -
df.isnull()判断数据表的空值,为空的位置返回True,不为空返回False -
np.any(df.isnull())判断该数据表中是否有空值,有空值直接返回true,没有空则返回false -
np.all(df.isnull())判断该数据表是否全部为空
Pandas读取及写入文件
-
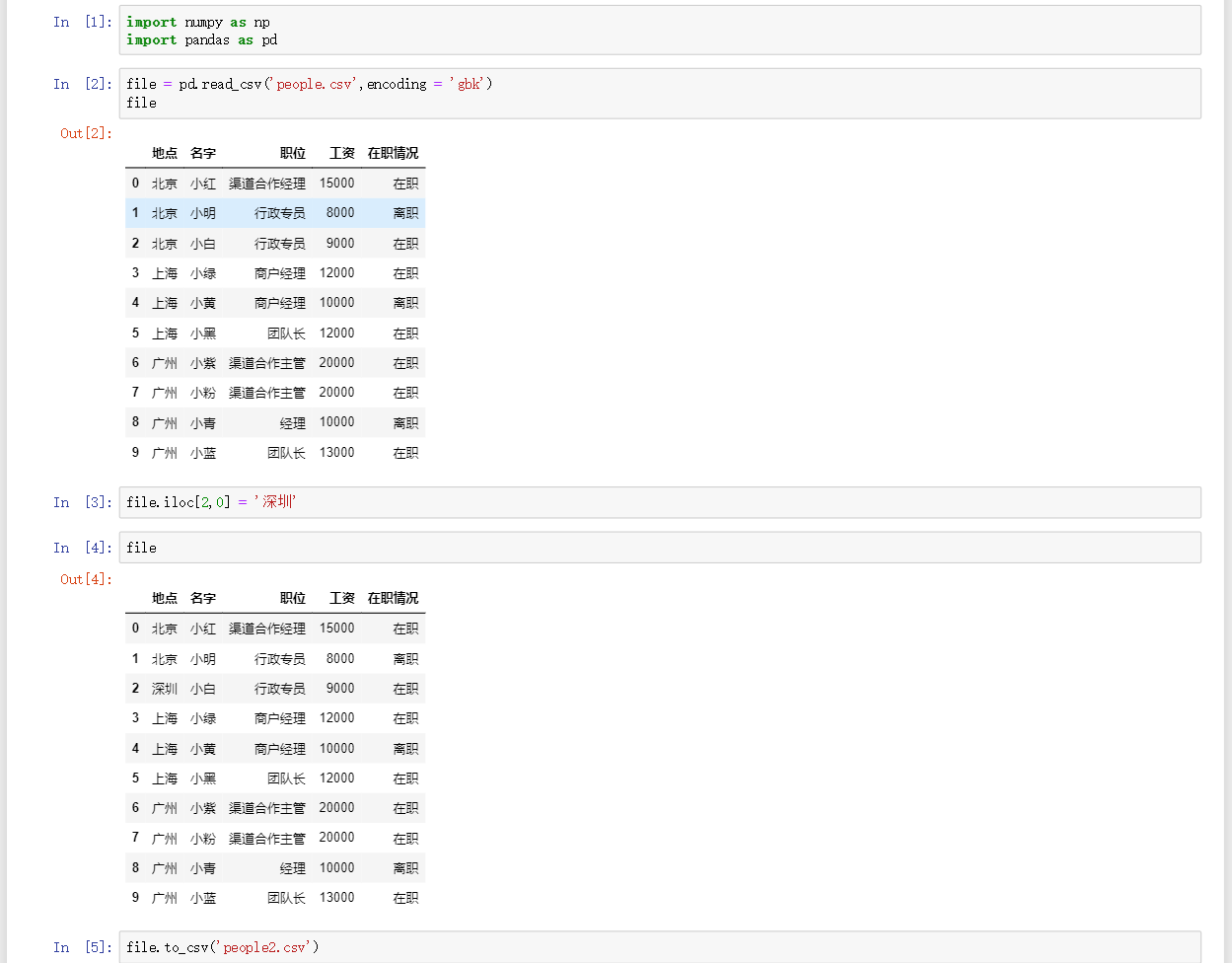
file = pd.read_文件格式('绝对路径/相对路径', encoding = 'gbk')读入文件 -
file.to_文件格式('file_name')重新保存文件
Pandas concat合并
-
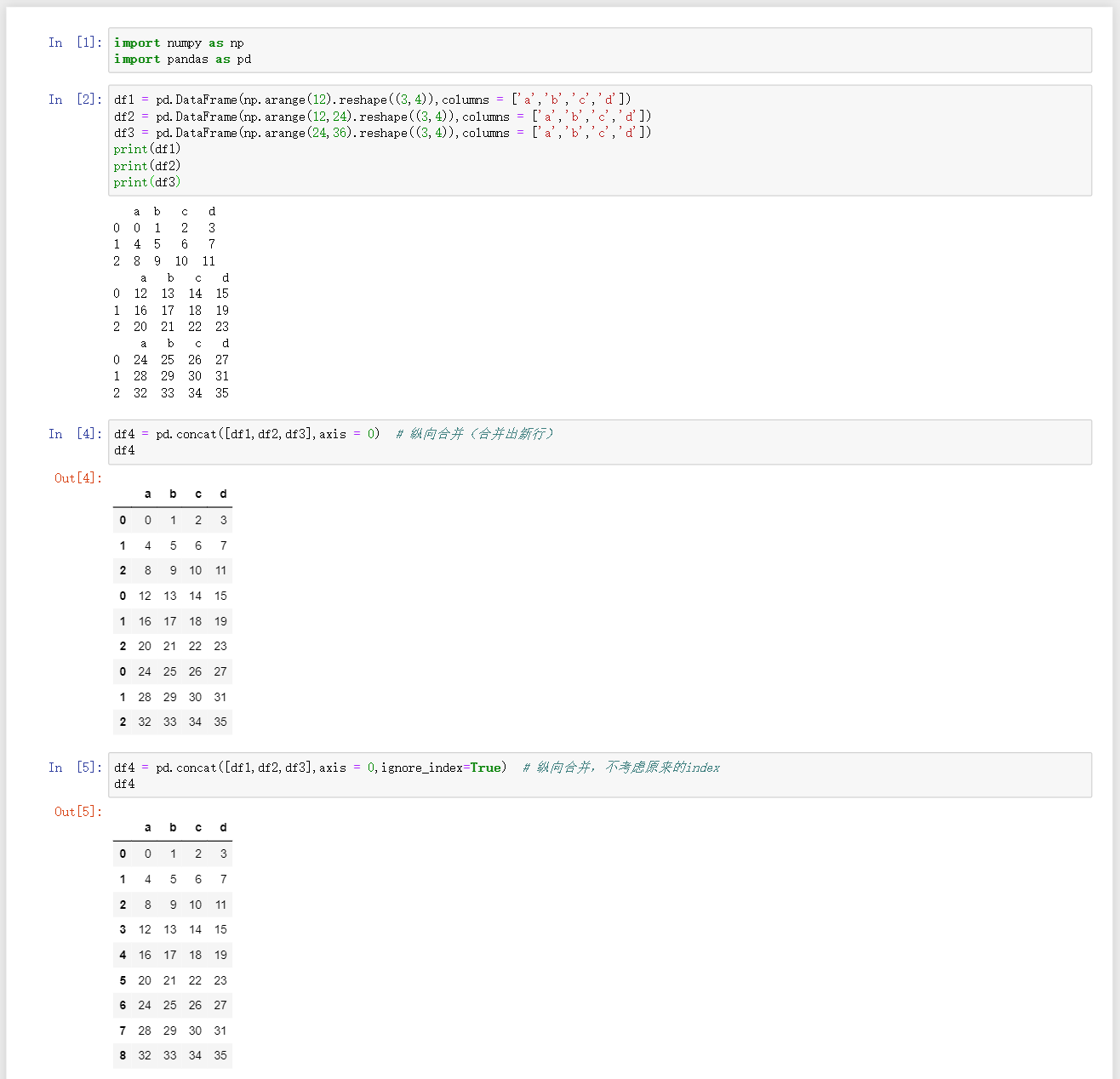
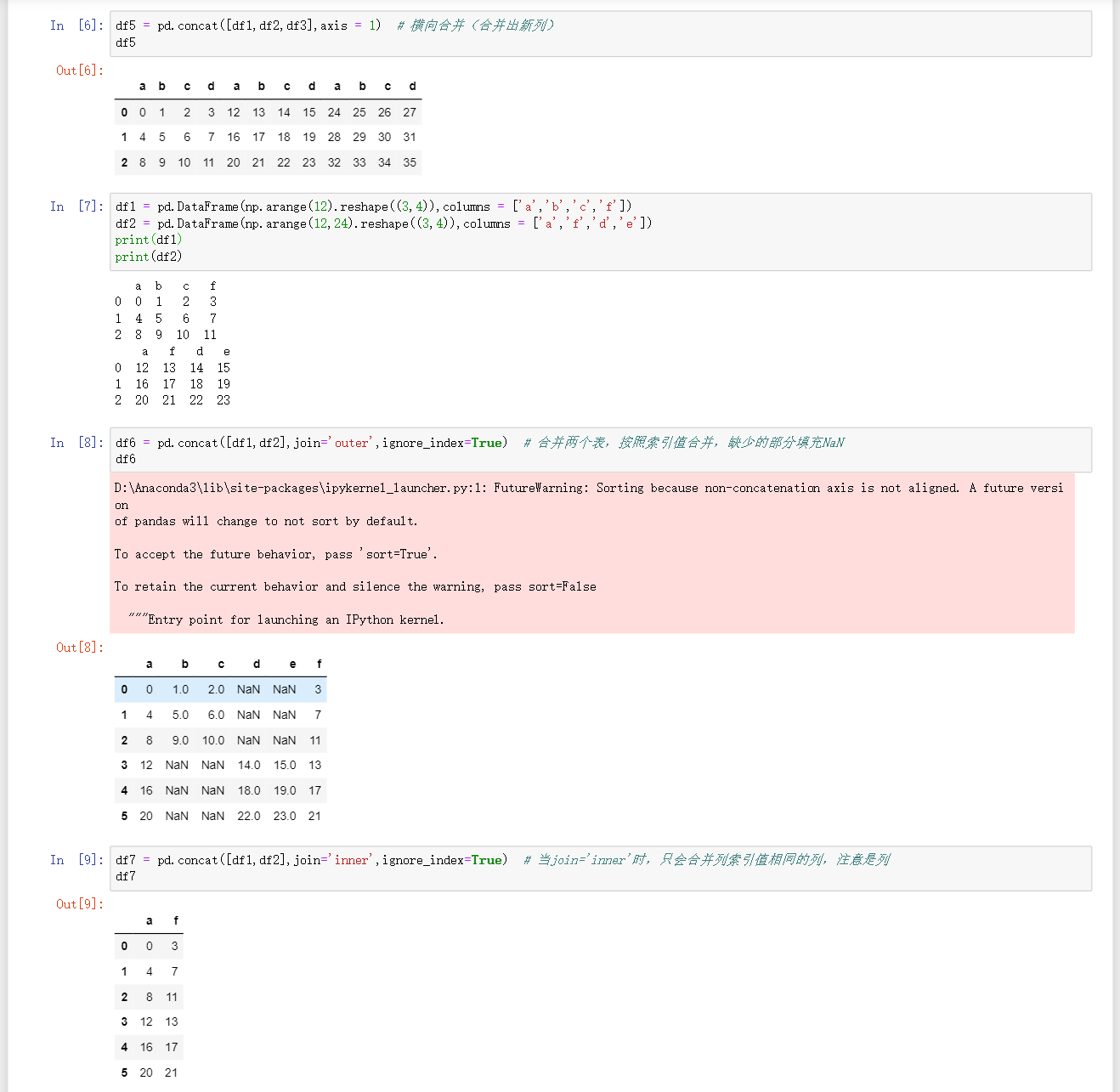
df = pd.concat([df1,df2,df3],axis=0/1)df1,df2,df3合并,axis=0是纵向合并,axis=1是横向合并,如何行列不同时,空白处会通过NaN填充 -
df = pd.concat([df1,df2,df3],axis=0/1,ignore_index=True)合并,考虑原来的index,重新生成默认index,ignore_index默认为false -
df = pd.concat([df1,df2],axis=0/1,join='outer'/'inner',ignore_index=True)当join='outer’合并两个表,缺少的部分填充NaN;join='inner’时只合并列索引相同的列,剩下的全部删除 -
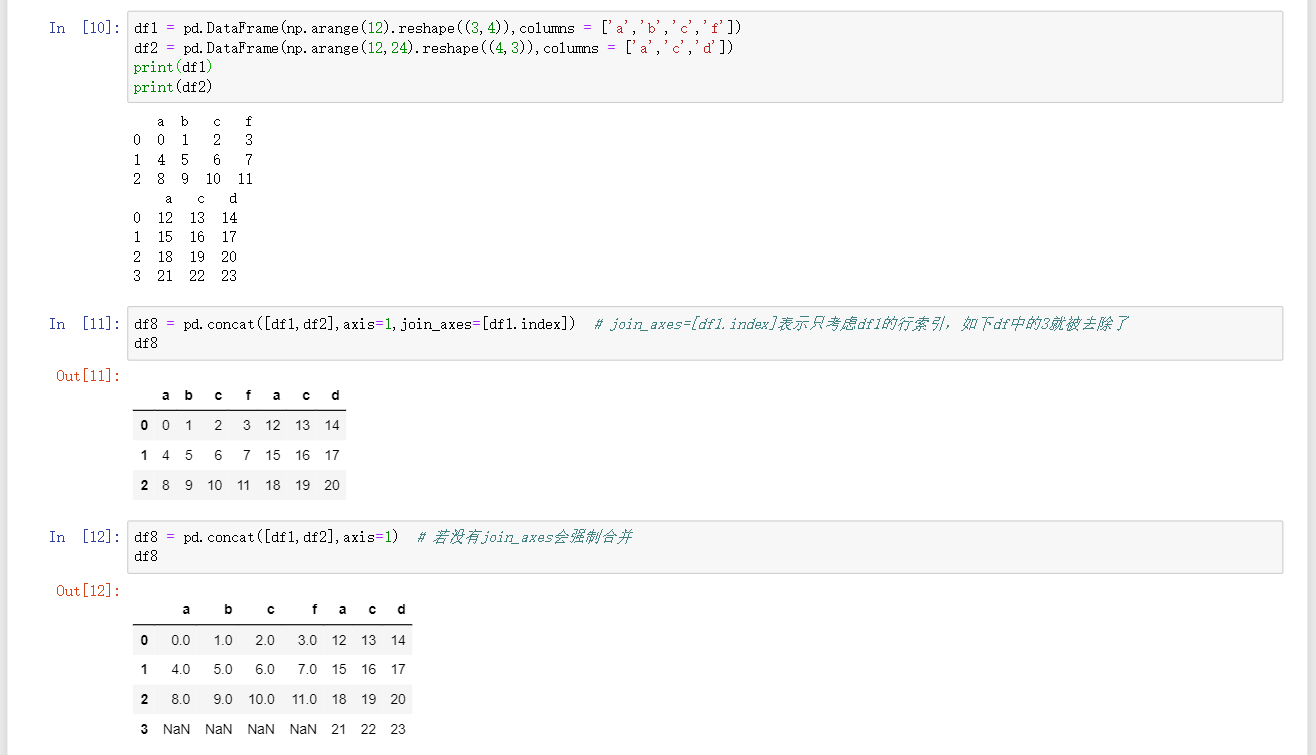
df = pd.concat([df1,df2],axis=0/1,join_axes=[df1.index])join_axes=[df1.index]表示只考虑df1的行索引,如果df2中的行索引比df1多那么就会被去除
Pandas merge合并
-
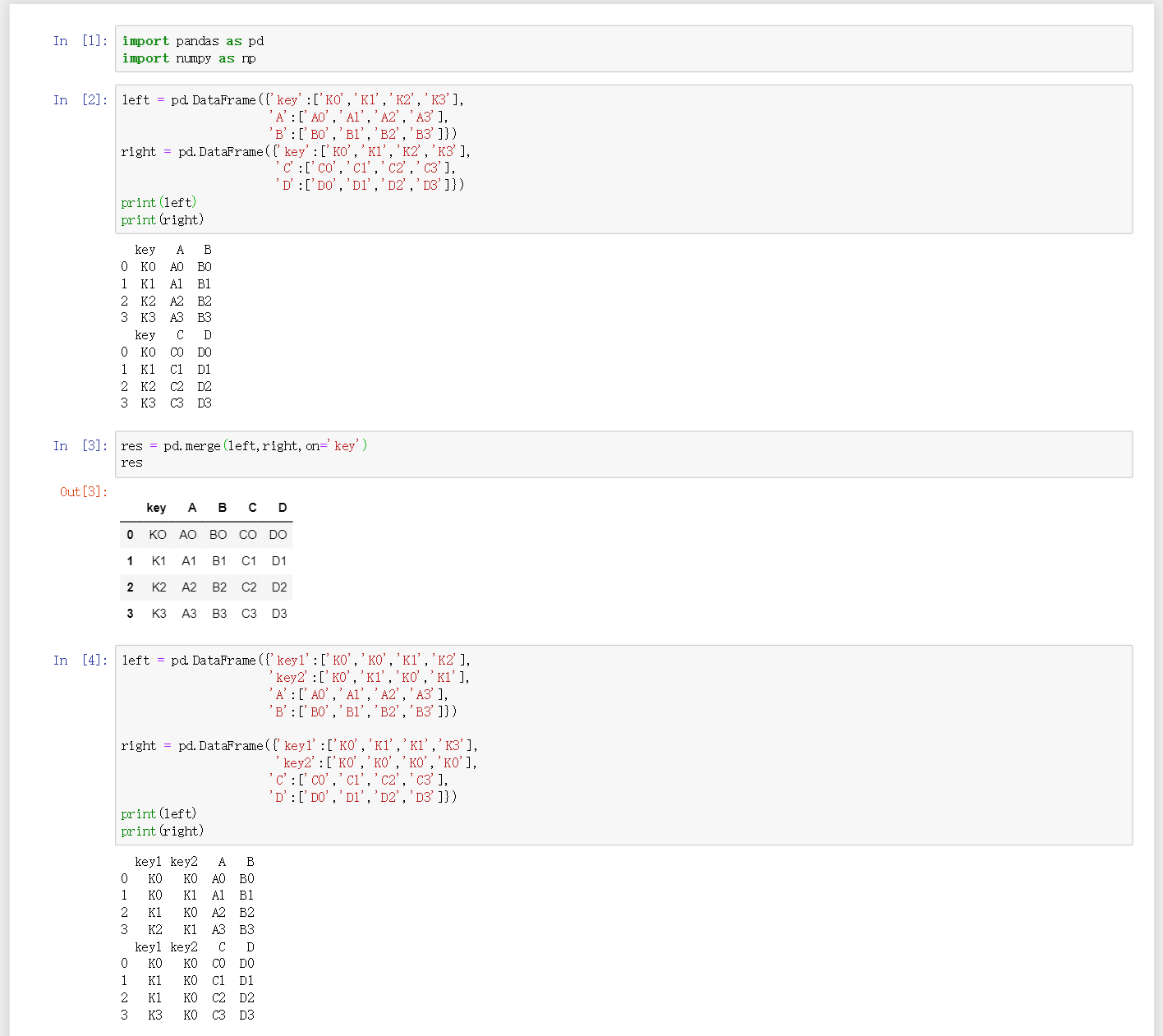
df = pd.merge(left,right,on='key')按照key值合并 -
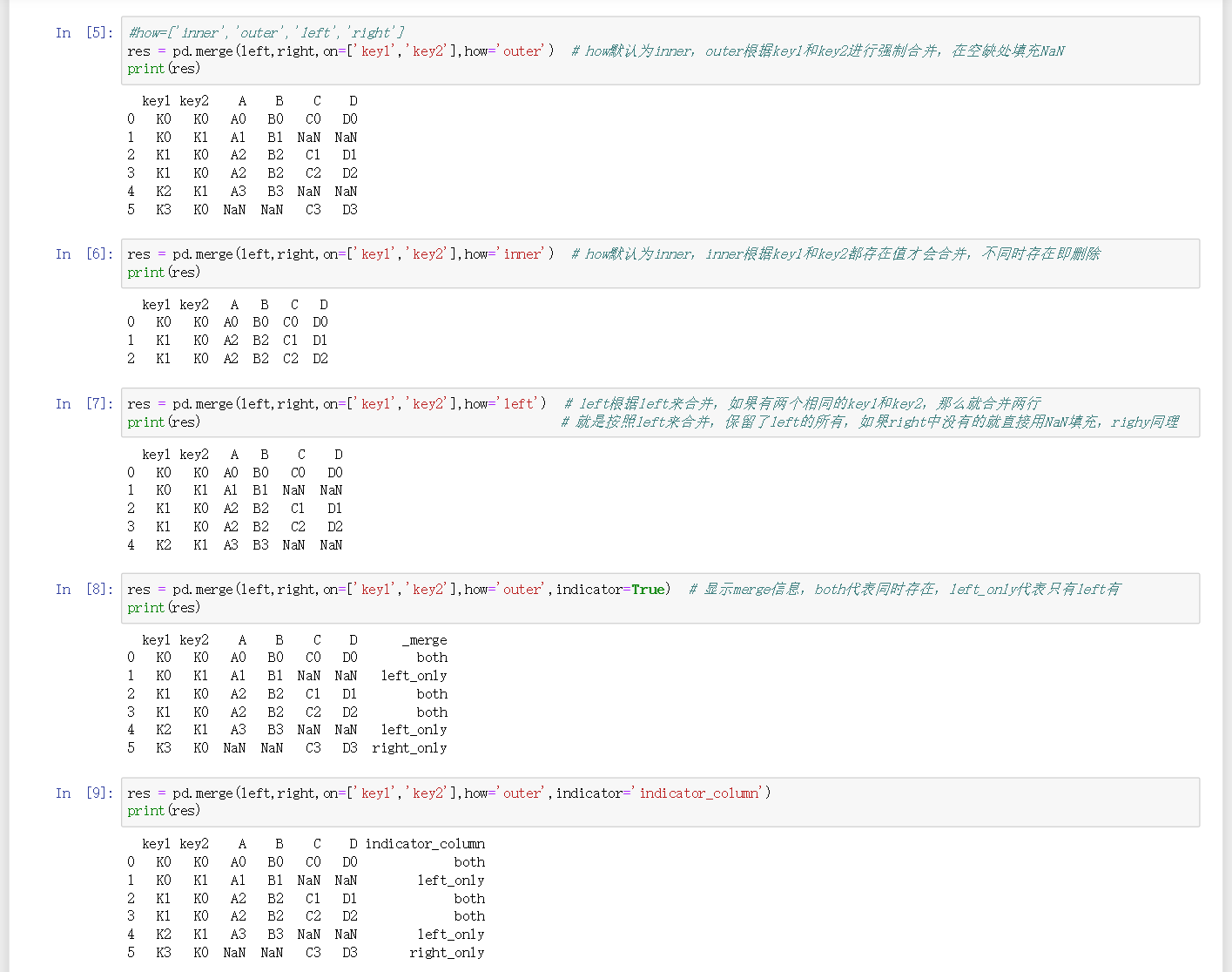
df = pd.merge(left,right,on=['key1','key2'],how='outer'/'inner'/'left'/'right')how默认为inner,outer根据key1和key2进行强制合并,在空缺处填充NaN;inner根据key1和key2都存在值才会合并,不同时存在即删除,;left根据left来合并,如果有两个相同的key1和key2,那么就合并两行,就是按照left来合并,保留了left的所有,如果right中没有的就直接用NaN填充,righy同理 -
df = pd.merge(left,right,on=['key1','key2'],how='outer',indicator=True/'name')显示merge信息,both代表同时存在,left_only代表只有left有 -
df = pd.merge(left,right,left_index=True,rihgt_index=True,on='outer')根据索引合并 -
df = pd.merge(boys,girls,on='key',suffixes=['_boy','_girl'],how='outer')suffixes为索引添加后缀

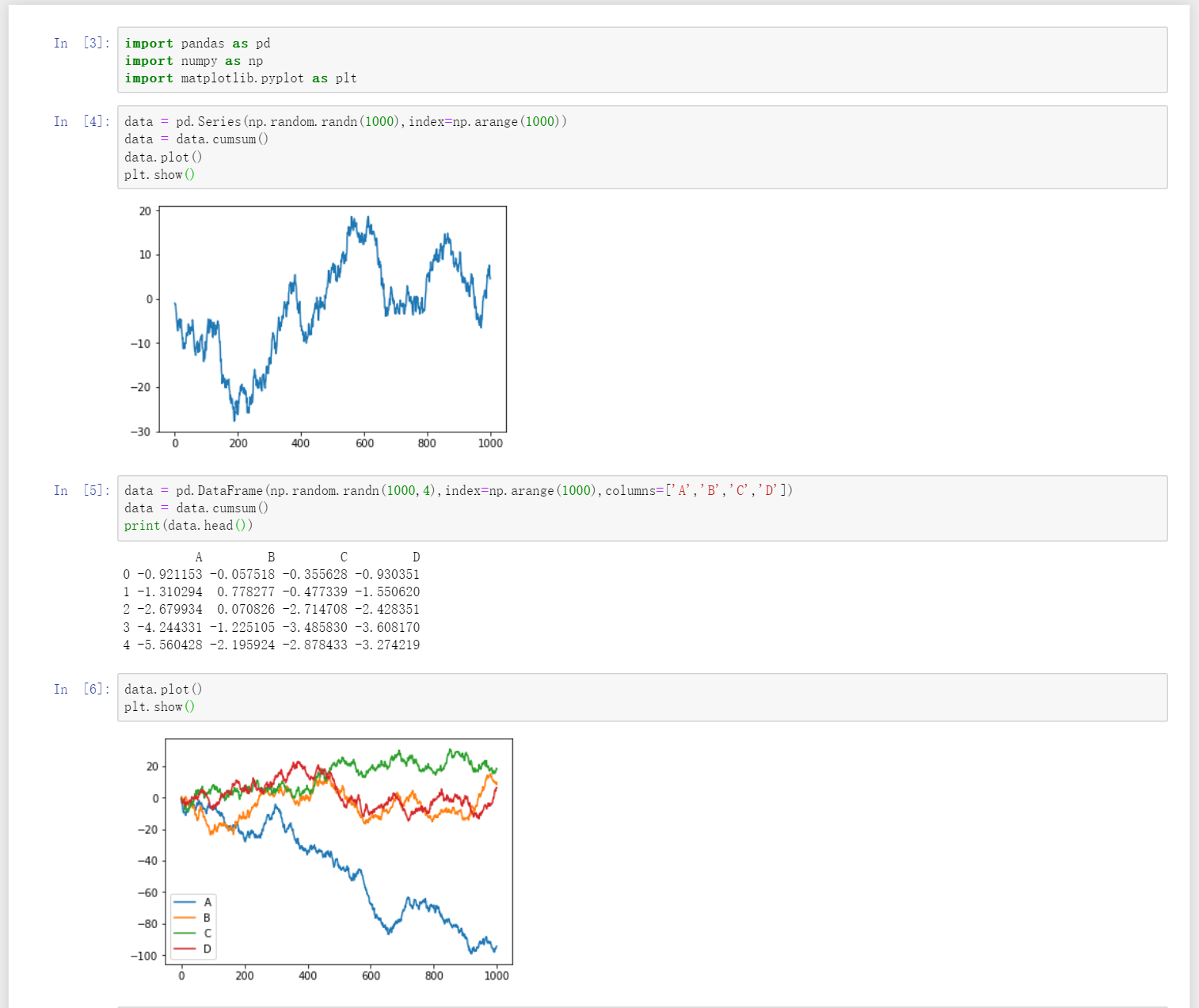
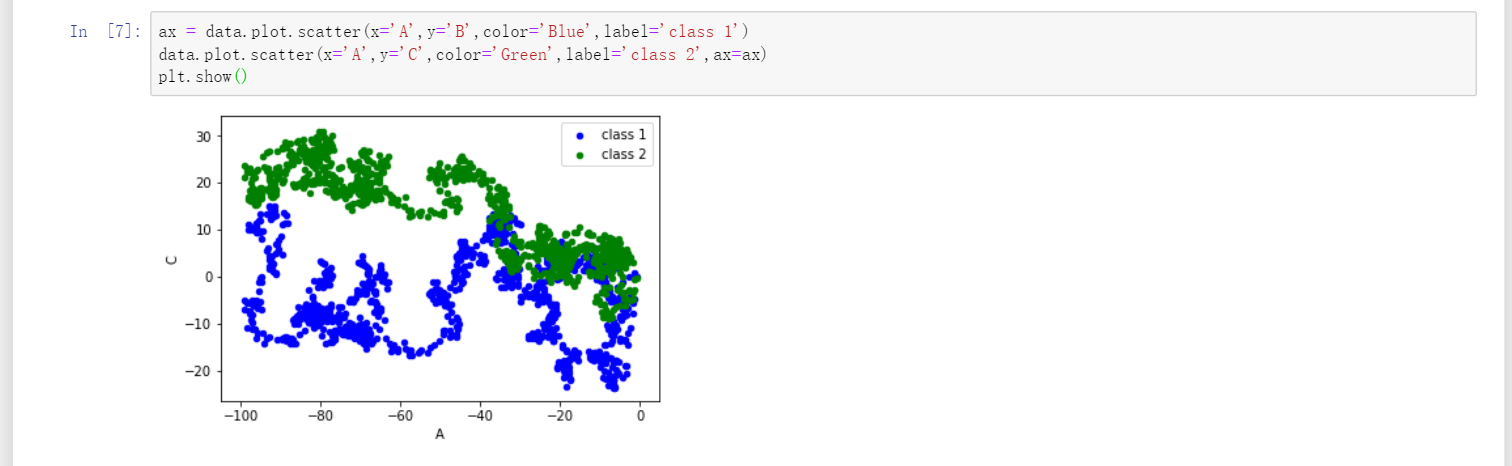
Pandas plot