最近做了一个工作就是对属性进行分类,然后用了不同的分类器,其中就用到了SVM,再次做一个总结。
1、什么是SVM?
对于这个点已经介绍的非常多了,不管是西瓜书还是各种博客,就是我们需要找到一个超平面,用这个超平面把数据划分成两个类别,最开始的SVM就是在二分类的问题上应用,在之后被扩展到多类别的分类。对于SVM的推导公式不是很复杂,在此就不进行推导,大概清楚最基本的原理然后就进行应用就可以了。
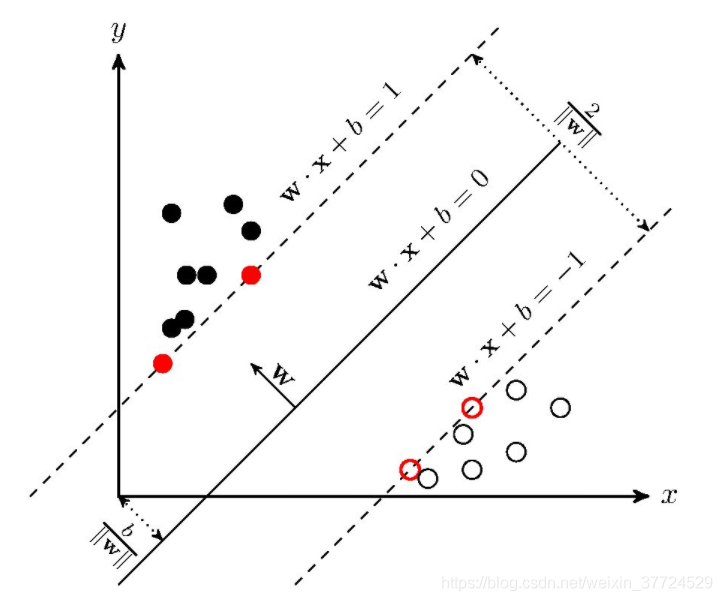
如下图所示,我们就是要找到中间这条线,使得||w||的值尽可能小,是正负样本离超平面的距离越大越好,分类的效果就越好。所有的优化都是围绕||w||开展的。
2、SVM的分类
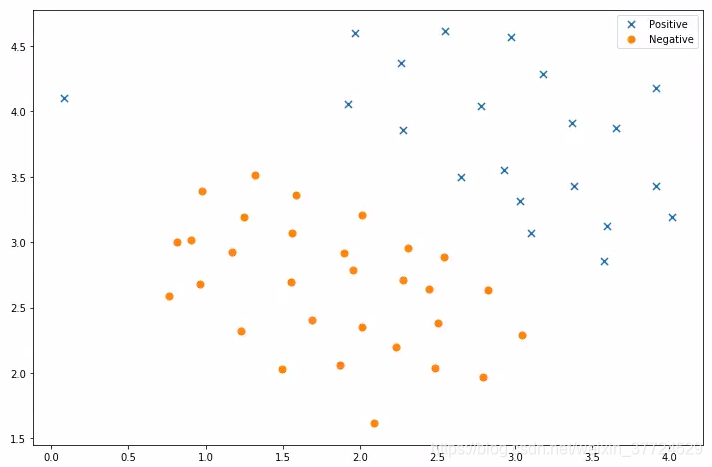
对于线性的数据集而且是二分类的,我们可以直接使用SVM进行分类,就可以到得到一个超平面将这两个样本分离开,如图所示。我们大概是可以找到一个超平面将这个两个类别分离开。
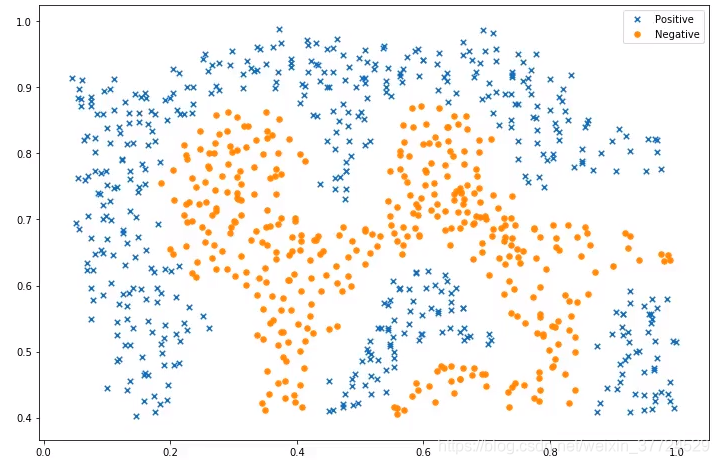
如果我们遇到的数据集是线性不可分的,那就不太容易了,因此我们需要用到一个核函数,这个函数的作用就是将平面的数据都映射到高维空间去,比如把二维的数据映射到三维的立体空间中去,我们可以想象这样一个按类,如果桌子上有两个颜色的豆子,分布是非线性的,有可能红色的豆子包围着黑色的豆子,这样导致线性不可分,那么我们可以用手敲桌子然后让豆子都弹起来,这样把它映射到了三维的空间,我们就可以找到一个超平面然后进行分类了。
在这个过程中我们需要用到核函数,核函数主要就是把数据映射到高维,常用的核函数有如下:
- 线性核
- 多项式核
- 高斯核
- 拉普拉斯核
- Sigmoid核
3、SVM进行属性分类
目前SVM进行多分类主要是两种类型:OVR&OVO
假如现在又A B C这三个类别,然后我们需要进行多分类,然后针对不同的类别我们需要详细阐述
OVR
- 将A分类正样本,BC那个类分为负样本
- 将B分类正样本,AC那个类分为负样本
- 将C分类正样本,AB那个分类为负样本
- 先右测试数据D,分别丢到3个分类器中,然后看那个分类器的得分高,那么就把数据判别为哪个类别
OVO
- 将AB分为一组正负样本
- 将AC分为一组正负样本
- 将BC分为一组正负样本
- 现有测试数据D,分别丢到3个分类器中,统计哪个类别出现的次数最多,那就把数据判别为哪个类别
一般情况,使用OVR还是比较多的,默认也就是OVR。如果有n个类别,那么使用OVO训练的分类器就是,因此一般情况下使用OVR这种分类。
SVM都已经有写好的库函数,我们只需要进行调用就行了,这个SVM库集中在sklearn中,我们可以从sklearn导入.
如果我们进行二分类那就使用svm.LinearSVC(),当然SVM中还有SVR(支持向量回归)
svm = svm.SVC()
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma=‘auto’, kernel=‘rbf’,
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)大概说一下几个比较重要的参数,或者是在训练中我们需要注意是超参数。
- C越大说明分类的越准确,但是有可能出现过拟合;C越小,噪声点越多,泛化能力越强容易欠拟合
- decision_function_shape='ovr',如果进行多分类是需要声明的,不声明默认就是ovr
- degree 多项式的维度
- gamma 就是高斯函数中的
- kernel 就是核函数默认是rbf也就是高斯函数
- max_iter 最大的迭代次数
- propobaility是否采用概率估计,默认是否
- tol 误差控制在0.001的时候就停止训练,max_iter默认是-1,就用tol来控制什么时候停止训练
- verbose允许冗余输出
C和gamma都是典型的超参,我们可以通过列举组合法最终判定模型最优的时候超参的设置
4、代码
背景:训练集有6500条,测试集有4500条。每一个属性对应的类别都是不一样的,属性的维度是64维,分类为20类,因此就需要用使用SVM进行多分类。
from sklearn.datasets import make_blobs
from sklearn import svm
import numpy as np
import torch
import numpy
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms, utils
class attDataset(Dataset):
def __init__(self,path):
super(attDataset,self).__init__()
atts=[]
with open(path,'r',encoding='utf-8') as f:
f = f.readlines()
for row in f:
row = row.split()
att = row[:-1]
att = [int(i) for i in att]
label = int(row[-1])
atts.append([att,label])
self.atts = atts
def __getitem__(self, index):
attribute,label = self.atts[index]
return attribute,label
#return torch.Tensor(attribute),torch.Tensor([label])
def __len__(self):
return len(self.atts)
path_train = r'./apascal/attribute_data/attribute_dataset.txt'
path_test = r'./apascal/attribute_data/attribute_dataset_test.txt'
train_features = []
train_label = []
test_features = []
test_label = []
train_set = attDataset(path=path_train)
test_set = attDataset(path=path_test)
for att,label in train_set:
train_features.append(att)
train_label.append(label)
for att,label in test_set:
test_features.append(att)
test_label.append(label)
train_features = numpy.array(train_features)
train_label = numpy.array(train_label)
test_features = numpy.array(test_features)
test_label = numpy.array(test_label)
clf = svm.SVC(C=5, gamma=0.05,max_iter=200)
clf.fit(train_features, train_label)
#Test on Training data
train_result = clf.predict(train_features)
precision = sum(train_result == train_label)/train_label.shape[0]
print('Training precision: ', precision)
#Test on test data
test_result = clf.predict(test_features)
precision = sum(test_result == test_label)/test_label.shape[0]
print('Test precision: ', precision)结果:
![]()
我没有进行调参,得到的结果还算不错,如果对超参进行调整可能准确率会更高一些吧。