pit1、在访问列表的时候,修改列表(可变对象都会存在类似的问题,这里就不一一验证了)
看一个例子,删除列表中3的倍数
def test(a):
for index, value in enumerate(a):
if value % 3 == 0:
del a[index]
b = [1, 2, 3, 4, 5, 6]
test(b)
print(b)
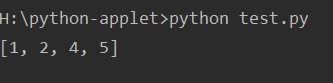
看结果好像没什么问题!!!
但是,我们就列表b变成:b = [1, 2, 3, 6, 5, 4]
再次运行的结果如下:
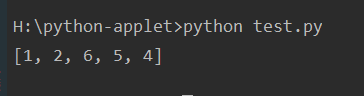
上面的例子中,6这个元素就没有被删除。如果在modify_lst函数中print idx, item就可以发现端倪:lst在变短,但idx是递增的,所以在上面出错的例子中,当3被删除之后,6变成了lst的第2个元素(从0开始)。在C++中,如果遍历容器的时候用迭代器删除元素,也会有同样的问题。
如何修改呢?使它适应所有情况呢?
修改方法1:
def test(a):
for index, value in reversed(list(enumerate(a))):
if value % 3 == 0:
a.pop(index)
return a
b = [1, 2, 3, 6, 5, 4]
print(test(b))
修改方法2:
def test(a):
for index, value in enumerate(a):
if value % 3 == 0:
a[index] = 'a'
result = list(set(a))
result.remove('a')
return result
b = [1, 2, 3, 6, 5, 4]
print(test(b))
pit2、可变对象作为默认参数
def test(a=[]):
a.append(1)
return a
print(test())
print(test())
运行结果如下:
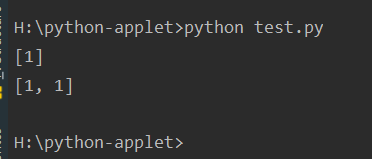
python中一切都是对象,函数也不列外,默认参数只是函数的一个属性。而默认参数在函数定义的时候已经求值了。
stackoverflow上有一个更适当的例子来说明默认参数是在定义的时候求值,而不是调用的时候
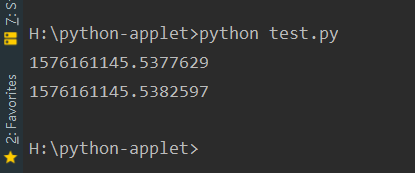
import time
def test(a=time.time()):
return a
print(test())
print(test())
运行结果如下:

如何解决?
def test(a=None):
if a is None:
a = time.time()
return a
print(test())
print(test())
再看一个例子:
def extend_list(value, my_list=[]):
my_list.append(value)
return my_list
list1 = extend_list(10)
list2 = extend_list(123, [])
list3 = extend_list('a')
print('list1 is: {}'.format(list1))
print('list2 is: {}'.format(list2))
print('list3 is: {}'.format(list3))
output:
list1 is: [10, ‘a’]
list2 is: [123]
list3 is: [10, ‘a’]
在实际上发生的事情是,一个新的列表只会在函数被定义的时候创建一次。并且在extend_list函数被调用的时候,如果没有指定my_list的参数,那么它们将会使用同一个列表(也就是定义的时候初始化的那个)。
pit3、注意小括号()
>>> a=(1)
>>> a
1
>>> type(a)
<class 'int'>
>>> b=(2,)
>>> b
(2,)
>>> type(b)
<class 'tuple'>
>>> a=('a')
>>> type(a)
<class 'str'>
>>>
>>>
可以看出我们要表示只有一个元素的元组时,后面必须加一个逗号,不然会被设别成其它类型
pit4、生成一个元素是列表的列表
这个有点像二维数组,当然生成一个元素是字典的列表也是可以的,更通俗的说,生成一个元素是可变对象的序列
很简单嘛:
>>> a= [[]] * 10
>>> a
[[], [], [], [], [], [], [], [], [], []]
>>> a[0].append(10)
>>> a[0]
[10]
看起来很不错,简单明了,but
>>> a[1]
[10]
>>> a
[[10], [10], [10], [10], [10], [10], [10], [10], [10], [10]]
我猜,这应该不是你预期的结果吧,究其原因,还是因为python中list是可变对象,上述的写法大家都指向的同一个可变对象,正确的姿势
>>> a = [[] for _ in xrange(10)]
>>> a[0].append(10)
>>> a
[[10], [], [], [], [], [], [], [], [], []]
pit5、闭包与lambda
举个例子
def create_multipliers():
return [lambda x: i * x for i in range(5)]
for multiplier in create_multipliers():
print(multiplier(2))
create_multipliers函数的返回值时一个列表,列表的每一个元素都是一个函数 -- 将输入参数x乘以一个倍数i的函数。预期的结果时0,2,4,6,8。
然而运行结果却是如下图,没错就是5个8,你没有看错:

这是为什么呢?
这个原因主要是Python闭包的后期绑定late binding造成的。这就意味着在闭包中变量的值是在内部函数被调用的时候才去寻找的。
所以造成的结果就是,在任何时候由multiplers()函数返回的函数集合被调用,变量i的值才会在那个时候去从它被调用时的作用域中查找。
在那时,不管在被返回的函数集合中的哪个函数被调用,for循环是已经完成的,而变量i已经被指定为了最终的值4。因此,被返回的函数集合中的每个函数中的i都是4,
所以在参数2被传递进入函数中,函数执行的操作其实是2*4,也就是8。
顺便说一点,就像The Hitchhiker’s Guide to Python指出的那样,人们存在一个误解,以为这种问题是由lambda函数造成的,其实不然,由lambda关键字创建的函数和由def关键字创建的函数是没什么不一样的。
修改方法1,创建一个闭包,通过使用默认参数立即绑定到它的参数上。:
def create_multipliers():
#return [lambda x: i * x for i in range(5)]
return [lambda x, i=i: i * x for i in range(5)]
for multiplier in create_multipliers():
print(multiplier(2))
修改方法2,利用元组:
def create_multipliers():
return (lambda x: i * x for i in range(5))
for multiplier in create_multipliers():
print(multiplier(2))
修改方法3,使用funtiontoos模块中的partial进行改写:
from functools import partial
from operator import mul
def multipliers():
return [partial(mul, i) for i in range(5)]
修改方法4,利用yield:
def multipliers():
for i in range(4):
yield lambda x: i * x
pit6,类变量的问题
class Parent(object):
x = 1
class ChildFirst(Parent):
pass
class ChildSecond(Parent):
pass
print(Parent.x, ChildFirst.x, ChildSecond.x)
ChildFirst.x = 2
print(Parent.x, ChildFirst.x, ChildSecond.x)
Parent.x = 3
print(Parent.x, ChildFirst.x, ChildSecond.x)
运行结果
1 1 1
1 2 1
3 2 3
WTF? 为什么最后一行输出不是3 2 1而是3 2 3? 为什么改变了Parent.x的值竟然也改变了ChildSecond.x的值。但是却没有改变ChildFirst.x的值?
这个问题的答案的关键是: 在Python中,类变量在内部是作为字典来处理的。
如果一个变量名没有在当前类的变量字典中找到,就会去搜索父类的变量字典,如果在一直延续到在顶层的祖先类的字典中也没有找到该变量。就会报出一个AttributeError的异常。
因此,在Parent中设置了类变量x=1,在该类和其任何子类的的变量引用中生效x=1.这就是为什么第一行输出1 1 1。
然后,如果某一个子类重写了这个变量,就像我们执行了ChildFirst.x=2,这个值会仅仅在这个子类中发生变化。这就是为什么第二行输出1 2 1。
最后,如果在父类Parent中改变。就会使得所有没有重写这个变量的子类中的该变量的值发生变化。就是最后一行输出3 2 3的原因。
references article1
references article2
references article3
references article4
references article5