【引言】
本文基于如下文章进行的实验,讲述聚簇因子对SQL索引的影响。
链接如下:
https://www.modb.pro/db/40283
当一张表上有索引,那么sql在执行的时候却不走索引的原因有很多很多,例如:
- 隐式转换
- 索引列上使用了函数
- 索引列选择度太差
- 条件列使用了is null或者is not null
- 条件列使用模糊查询并且前面带%
- 条件列使用了<>或者!=
- 表的统计信息与实际值相差很多
- 索引不满足当前的业务场景
- 索引列分布不均匀,且该列上存在直方图
- 查询条件没有使用索引的前导列
- 对索引列进行了运算
- 等值和范围索引不会被合并使用
13. 索引相关的参数设置
14. 索引的clustering factor值太大
今天学习最后两项是如何影响索引使用。
和索引的使用有关的参数大家应该都很熟悉:
optimizer_index_cost_adj:
优化器计算通过索引扫描访问表数据的cost开销,可以通过这个参数进行调整。参数可用值的范围为1到10000。默认值为100,超过100后越大则越会使索引扫描的COST开销越高(计算的),从而导致查询优化器更加倾向于使用全表扫描。相反,值越小于100,计算出来的索引扫描的开销就越低。
optimizer_index_caching:
用于在执行in-list遍历和嵌套循环连接时,优化器评估已经存在于buffer cache中的索引块的数量(以百分比的方式)。参数的取值范围是0到100,默认值为0,取值越大就越减少优化器在评估In-list和嵌套循环连接的索引扫描的开销COST。
SQL> show parameter optimizer_index
NAME TYPE VALUE
------------------------------------ --------------------------------- ------------------------------
optimizer_index_caching integer 0
optimizer_index_cost_adj integer 100
注意:
修改这两个参数后,所谓的COST都是oracle根据公式计算出来的,而不是说修改了参数之后,真实的消耗就低了或者高了。
索引范围扫描的成本计算公式如下:
cost = {(blevel+leaf_blocks * effective index selectivity)*(1-optimizer_index_caching/100)+
(cluster_factor * effective table selectivity)*(optimizer_index_cost_adj/100)
由于这两个参数在oracle 10gR2之后就建议保持默认值,从上面的成本计算公式也可以看出这两个参数是如何影响成本计算的,并且对于案例模拟也很简单,这里就不再模拟了。顺便说一句,其实除了这两个参数,还有一个参数在一定程度上也能决定索引的优先程度,它就是db_file_multiblock_read_count,这个也很好理解,这里也就不再模拟。
接下来我们来看看索引聚簇因子(clustering factor)对于索引的使用是如何影响的,在模拟之前我们先来看看什么是聚簇因子。
聚簇因子(clustering factor)和索引高度(blevel)、叶块数(leaf_blocks)等统计信息值一样用于计算cost的值,以决定当前sql语句是走索引还是走全表扫描等。
堆表中数据的存储方式为无序存储,
也就是任意的DML操作都可能使得当前数据块存在可用的空闲空间,出于节省空间的考虑,块上的可用空闲空间会被新插入的行填充,而不是按顺序填充到最后被使用的块上。以上的操作也就导致了数据块中数据的无序性,而创建索引的时候,会将指定的列按顺序插入索引块中。正是因为表上的数据是无序的,索引上的数据是有序的,这种差异性就可以用聚簇因子来表示。
为了更直观的描述什么是聚簇因子,以及聚簇因子是如何计算出来的,可以看下面这张图:
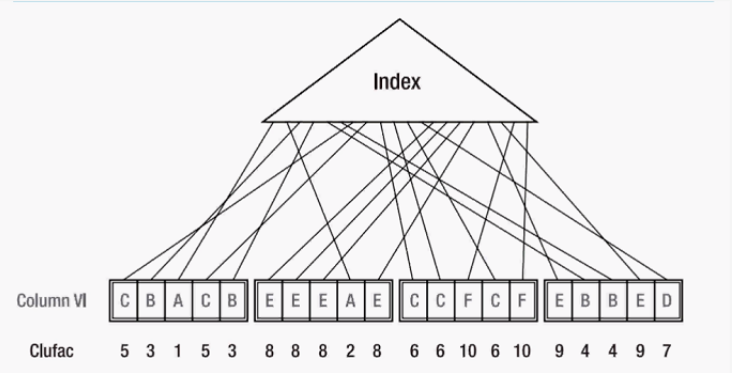
三角形代表着一个索引,下面对应四个数据块,依次读取索引中的每一个键值:
读第一个索引键值A,根据索引上存储的对应的rowid去数据块中找到A
第一个数据块中找到A,clustering factor记为1,第二个数据块中又有A,clustering factor记为2
读索引键值B,第一个数据块中存在两个B,则都记为3,第四个数据块中又存在两个B,则都记为4
读索引键值C,第一个数据块中存在两个C,则都记为5,第三个数据块中存在三个C,则都记为6
读索引键值D,第四个数据块中存在一个D,则记为7
读索引键值E,第二个数据块中存在4个E,则都记为8,第四个数据块中存在两个E,则记为9
读索引键值F,第三个数据块中存在两个F,则都记为10
至此所有的索引键值全部扫描完成,最终该索引的聚簇因子的值为10
如果总结一句话就是:执行或预估一次全索引扫描。检查索引块上每一个rowid的值,查看是否前一个rowid的值与后一个指向了相同的数据块,如果指向了不相同的数据块则clustering factor的值增加1。当索引块上的每一个rowid被检查完毕,即得到最终的clustering factor值。
由上面的分析可以看出clustering factor的值介于表中数据块的个数和表中数据行数之间,极端情况下,等于表中数据的行数。
通过实验演示一下clustering factor对索引选择的影响。
测试数据准备
create tablespace tbs0831 datafile '/u01/app/oracle/oradata/ces/tbs0831.dbf' size 10M autoextend off;
create user test0831 identified by test0831 default tablespace tbs0831;
grant dba to test0831;
conn test0831/test0831
create table tb0831 (id1 number ,id2 number);
begin
for i in 1..100
loop
for j in 1..100
loop
insert into tb0831 values(i,j);
end loop;
end loop;
end;
/
create index idx_1 on tb0831(id1);
create index idx_2 on tb0831(id2);
==--搜集统计信息,注意加cascade=>true,表示对索引也搜集统计信息==
exec dbms_stats.gather_table_stats(user,'TB0831',cascade=>true);
从上面插入数据的脚本可看出,id1的值存储的更加紧凑,id2的值存储的更加松散。
SQL> select INDEX_NAME,NUM_ROWS,DISTINCT_KEYS,CLUSTERING_FACTOR,BLEVEL,LEAF_BLOCKS from dba_indexes where table_name='TB0831';
INDEX_NAME NUM_ROWS DISTINCT_KEYS CLUSTERING_FACTOR BLEVEL LEAF_BLOCKS
------------------------------------------------------------------------------------------ ---------- ------------- ----------------- ---------- -----------
IDX_1 10000 100 22 1 20
IDX_2 10000 100 1600 1 20
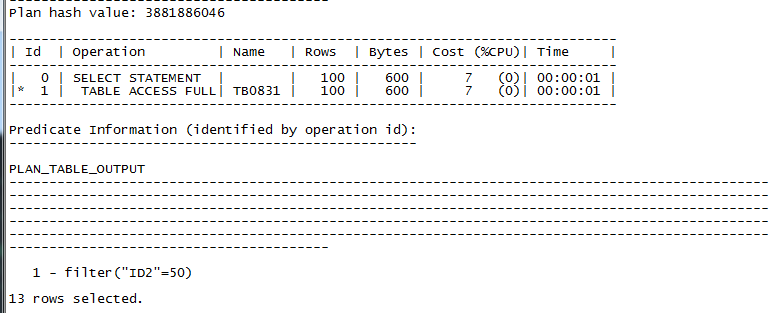
先执行如下sql:
explain plan for select * from tb0831 where id1=50;
select * from table(dbms_xplan.display);
将id1换成id2再执行下面的sql:
explain plan for select * from tb0831 where id2=50;
select * from table(dbms_xplan.display);
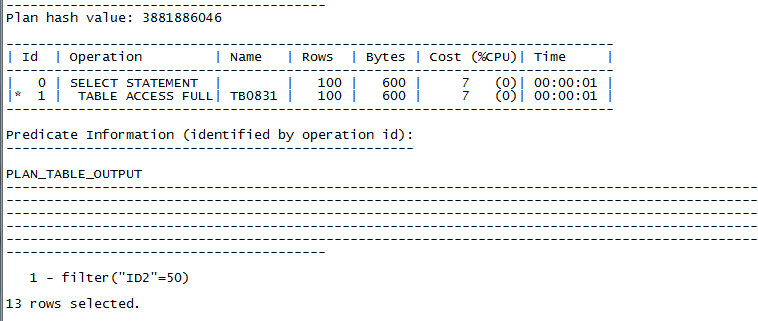
正是索引IDX_2的聚簇因子为1600,太大了,导致cbo在评估执行计划的时候,计算出全表扫描的cost要小于走索引idx_t02的cost。所以在有索引的情况下,cbo选择了走全表扫描。
如在一些场景下,ORACLE可能不会自动走索引,如果对业务清晰,可以尝试使用强制索引,测试查询语句的性能。
针对如下SQL进行index绑定:
select * from tb0831 where id2=50;
重写sql:
SQL> explain plan for select /*+index(TB0831,idx_2)*/ * from tb0831 where id2=50;
Explained.
SQL>
SQL>
SQL> select * from table(dbms_xplan.display);

上述案例,可看出聚簇因子值的大小对于是否走索引产生的影响。
如有一个索引他的聚簇因子很大,该如何优化呢?
-
重建索引并不能改变聚簇因子的大小,因为索引是有序的,而导致聚簇因子值大的根本原因在于表上存储的数据太无序,以至于和索引中存储的顺序相差甚远。一个可行的方案为定期表重构,将数据先临时存储在中间表中,truncate原始表,最后按照索引存储的顺序填充数据到原始表中。
-
尽可能的避免一个具有槽糕clustering factor值的索引,比如索引在创建的时候,应考虑按照经常频繁读取的大范围数据的读取顺序来创建索引。
欢迎关注个人微信公众号“一森咖记”
 image.png
image.png