为什么我们选择Flink作为我们的匹配生成服务?

Azar的发展非常迅速,现在该平台每天在高峰时段处理的请求量超过1.8亿次(在移动屏幕实时视频中“向左滑动”)。为了确保Azar的匹配生成服务能够支持不断增长的用户活动和参与度,我们重新设计了匹配生成服务,使Apache Flink成为其架构的核心。Flink被选为首选数据处理框架,因为它提供了必要的可伸缩性,稳定性和处理大量数据的状态计算的能力。
可扩展性
在高峰时段,我们的系统每秒处理超过5,000个匹配生成请求,每秒处理超过1200万对匹配计算,从而为用户提供最佳结果。
稳定性
匹配生成服务是我们产品系列的核心功能,因此我们需要返回结果的响应时间以毫秒为单位且服务的停机时间应该为零,因为它直接影响我们的业务和用户 在我们的应用程序中的体验。
有状态的计算
为了改进我们的配对算法,必须保存有关用户的某些状态。我们在以前的无状态计算中使用了简洁的变通方案,这直接影响了我们的计算延迟和事件流水线pipeline的整体复杂性。因此,我们决定从头开始重新设计配对生成服务。
Apache Flink具有独特的优势,可以执行低延迟的迭代,从而使我们的pipeline计算的总反馈周期不到一秒钟。此外,Flink的基于算子的松散耦合体系结构可以更方便的执行多套打分逻辑,进而获取到更多潜在候选对,从而支持我们提高原始配对系统的匹配质量。另外,Flink对状态管理的内在支持使我们能够通过实施实时推理pipeline来执行有状态计算,从而为用户带来更多价值。以上特性为我们的实时配对服务提供了更好的扩展性与稳定性。
为了更好地了解我们的系统架构,让我们解释一下Hyperconnect和Azar如何进行匹配生成。传统上意义上的配对是将两个或多个实体进行匹配,为了在Azar上进行实时匹配,我们在特定的时间窗口内收集来自个人的匹配请求,并尝试以低延迟返回最佳配对。我们将基于Flink的实时匹配系统分为如下六个步骤:
1.收集源(数据和输入源)
2.特征工程
3.匹配生成
4.配对评分
5.生成匹配
6.输出到多个下游
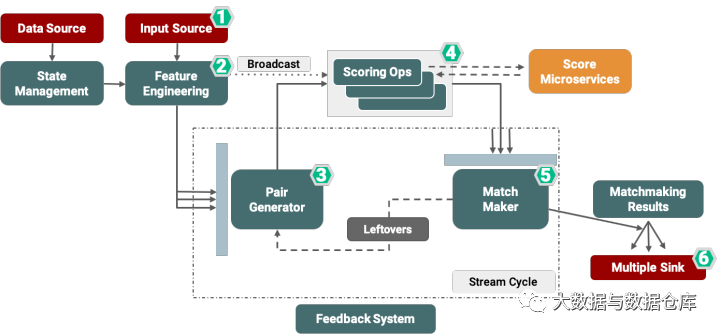
收集源(数据和输入源)
匹配过程的第一步是通过自定义Netty HTTP 收集来自不同客户端的匹配请求,从而使我们能够将系统的响应时间缩短到接近实时。
特征工程
匹配过程的第二步是特征工程,其中包括矢量化,分割和用户标记等。
数据会在匹配环节之前做预处理,如进行标记细分(即执行A / B测试)或对用户特征进行矢量化以用于机器学习模型。
在此步骤中,我们的Flink作业的状态后端将根据用户的偏好和特征来管理用户的历史匹配记录。
匹配生成
我们架构的第三步是匹配生成服务,该服务收集配对请求并生成匹配对,然后再将它们传递给下游进行匹配计算。
在此步骤中,使用Flink的Window API和带key的翻滚窗口来收集匹配请求。
配对评分
匹配过程的第四步是评分计算。在这里,我们并行执行多个评分逻辑以获取最佳结果,多个团队可以参与评分逻辑的迭代。
在此步骤中,我们全局管理匹配矩阵,并在每个计分器中使用它来实施多臂老虎机(Multi Armed Bandit)以提高匹配质量。计分算子负责计算所有配对的得分并及时返回。为此,我们并行化每个打分分组。
与每个评分微服务的通信均基于REST API,并利用Apache Flink的AsyncDataStream。
生成匹配
HyperMatch系统中的第五步是配对生成服务,该服务根据评分算子的结果选择最佳配对。
该服务通过容错的方式汇总不同评分微服务的结果,并通过我们自定义的trigger和evitor以及分布式排序算法来更快的生成最佳配对。
在这里,成功的配对将被传递到“配对结果”服务,而剩余的配对将使用Flink的迭代流功能重定向回配对生成器(第3步)。
输出到多个下游
匹配过程的最后一步为“匹配结果”服务,该服务具有多种功能,如给下游提供最佳匹配结果。
该服务还分发结果并提供反馈以改善未来匹配表现,或将结果发送给我们的日志记录和指标汇总。
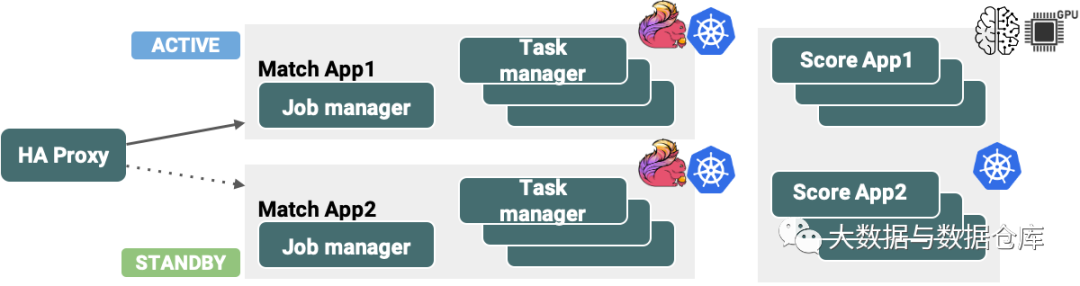
上述基于Flink的HyperMatch架构已在我们的生产环境中使用Kubernetes作为基础资源管理框架进行了部署。
利用Kubernetes可以在我们的Flink部署中实现高可用性(HA),并可以轻松的进行性能测试。为了使此类关键任务实时数据应用程序实现零停机时间,我们已基于下图中的两种体系结构配置了部署管道。
往期精选▼
Spark Shuffle调优之调节map端内存缓冲与reduce端内存占比
Flink中Checkpoint和Savepoint 的 3 个不同点
3种Flink State Backend | 你该用哪个?
回复 flink 获取Flink Forward 2020 PPT。
