![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ct6mGp6C-1588060318500)(http://www.xiaokai1999.cn/wp-content/uploads/2020/04/20140929105843541.jpg)]](https://img-blog.csdnimg.cn/20200428155241653.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3hpYW9rYWkxOTk5,size_16,color_FFFFFF,t_70) 最新文章首先会在我的个人网站更新:戳一戳
最新文章首先会在我的个人网站更新:戳一戳
分享并记录自己的代码,仅供学习~
通过罗志祥最新微博下面的评论通过可视化词云分析网友对罗志祥的看法是什么。
效果

从上面可视化词云可以看出来,网友对罗志祥持有一种失望的感觉。
查找入口
1.依旧是那个熟悉的第一步,直接进入NetWork分析网络包。
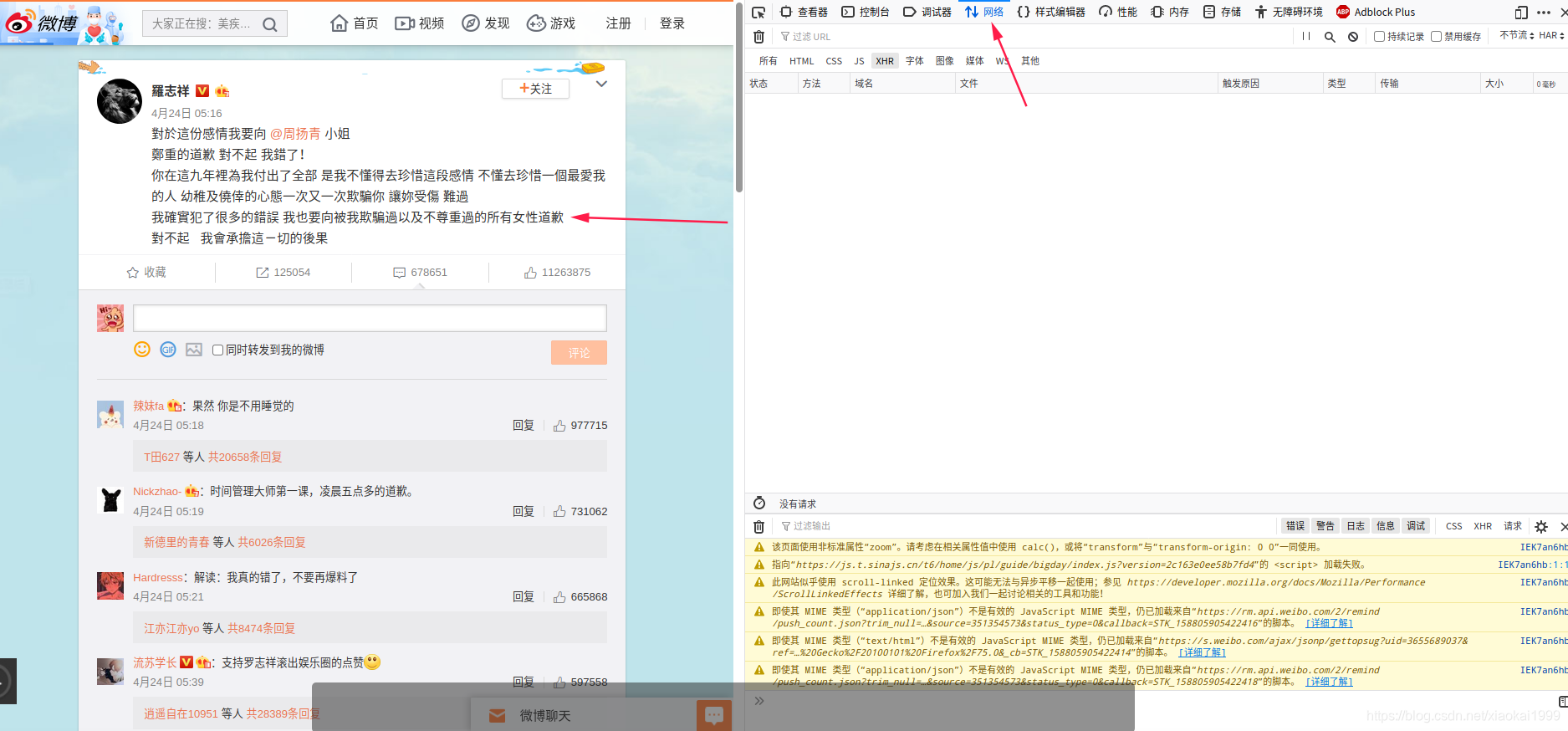
2.刷新网页,选中XHR格式,直接得到评论数据
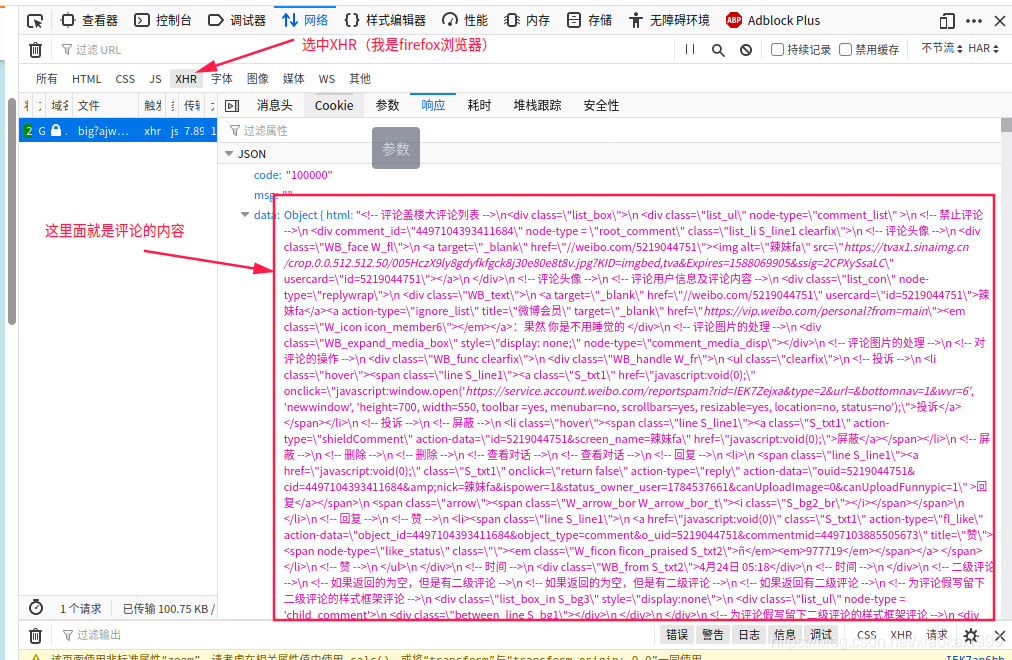
3.随即查看消息头分析网页URL
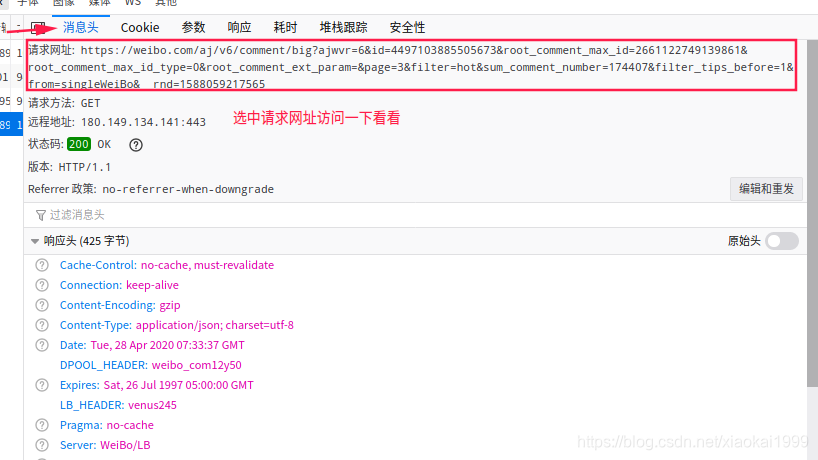
4.话不多说,直接复制看看能否直接访问
 可以直接访问就好办了,说明这个url和一些时间戳的关系不是很大,主要是其中的
可以直接访问就好办了,说明这个url和一些时间戳的关系不是很大,主要是其中的
- id #这条微博的id
- root_comment_max_id_type
- page #很明显这个是评论页码,越往下刷新,页码越大
源代码
import requests
import time
from random import randint
import re
import json
import os
path = os.getcwd()
# 40
for i in range(10,15):
url = "https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4497103885505673&root_comment_max_id=4498671825072962&root_comment_max_id_type=0&root_comment_ext_param=&page="+str(i)
headers = {
"cookie":,#填写自己的cookie
"Connection":"keep-alive",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36"
}
requests.adapters.DEFAULT_RETRIES = 5 # 增加重连次数
s = requests.session()
# 关闭多余连接
s.keep_alive = False
# http请求头
url_data = s.get(url,headers=headers, timeout=randint(1, 6)*1).text
json_data = json.loads(url_data)
html_data = json_data['data']['html']
print(html_data)
commends = re.findall("</a>:(.*)</div>",html_data)
print("第"+str(i)+"页")
with open(path+"/information.txt",'a') as f:
for commend in commends:
if "回复" in commend:
index = commend.index(">:")
commend = commend[index:]
# if "<img" in commend:
# index = commend.index("<img")
# commend = commend[:index]
# elif "<a" in commend:
# index = commend.index("<a")
# commend = commend[:index]
f.writelines(commend+'\n')
print(commend)
f.close()
time.sleep(5)
mark一个好用的词云网站:http://cloud.niucodata.com/