再回头只能怀念,再见了,马银霜,真的好爱你
produce是kafka的消息发送者,负责将消息发送到kafka代理服务器(broker)指定的topic下的某个partition
一:消息的分布
假设现在一个topic下有两个partition,下面是一个produce按照顺序发送四条消息之后,partition中的情况
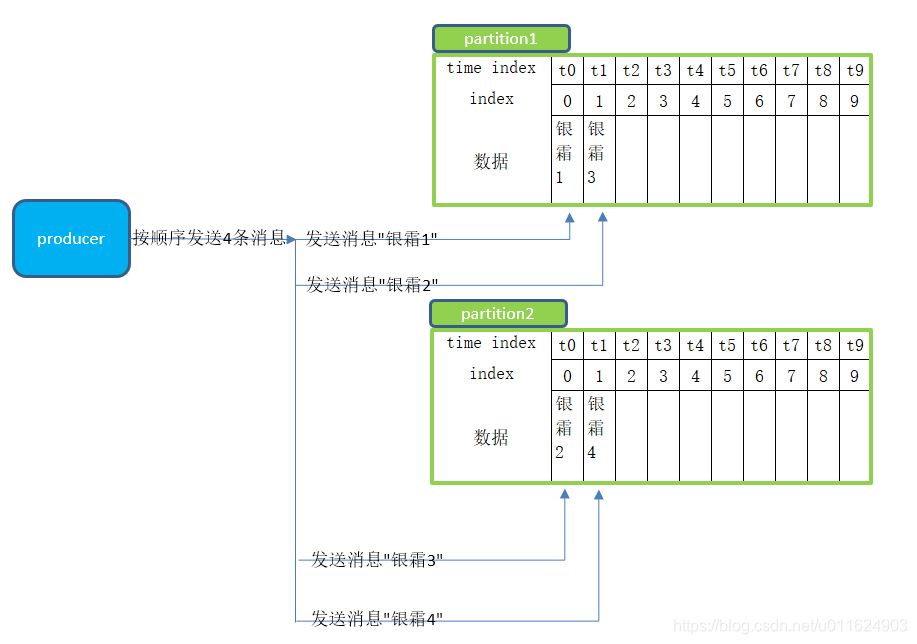
可以看到消息是大致按照图中的样子存储的,主要想阐述的就是分片这个概念,目的是为了减少每个partition的存储数据量,同时也为了消费端可以从多个partition同时取数据,那么这四条数据真实情况到底都存储到哪个partition呢?其实我也不知道,我没有测试,但是只要是分布式架构的中间件,必定遵循分布式理论,也就是说数据的分布方式只有可能是下面三种:
1.hash分布(kafka默认的分布方式)
2.按照数据范围分布(按照数据特征分布)
3.按照数据量分布
所以感兴趣的朋友可以自己测试一下,数据使用hash算法之后,分布到哪个partition,不过我觉得意义不大,我们研究的是kafka的设计思想,而不是这种小事
二:消息的持久化(如何确保消息不丢失)
在研究消息质量保证之前,必须要了解partition副本同步机制,你可以点击这里查看关于partition同步机制
producer只是跟broker中的leader partition交互,不与follower partition交互
参数acks有四个值,分三种情况
acks=0:producer将消息扔给broker(就是leader partition)之后,就认为发送成功,如果出现网络瞬断,这种情况有可能消息丢失
acks=1:producer将消息扔给leader partition之后,等待leader partition数据持久到本地(commit log文件中),持久化完毕之后,认为发送成功
acks=-1:producer讲消息扔给leader partition之后,不但要等待leader partition将数据持久到本地,还要等待follower将leader数据同步过去之后,才认为发送成功,这场景很适合重要的数据,比如订单,银行
acks=all:与-1完全一样
日记:假设一共有3个副本,如果设置min.insync.replicas=2,那等待两个副本写入完毕,就返回
三:缓冲区
buffer_memory参数:发送者会将要发送的数据都扔到缓冲区,然后在缓冲区组装batch包,最后将batch发送出去,注意这不是缓冲多少再发送,而是从缓冲区拿数据,拼装batch,然后发送batch
batch_size参数:当每条消息的总大小达到多少时,发送该条消息
linger_ms参数:如果batch不满,总不能不发吧,这个就是达到多少毫秒后,如果batch还没满,依然会发送出去