备注:
Hive 版本 2.1.1
一.题目要求
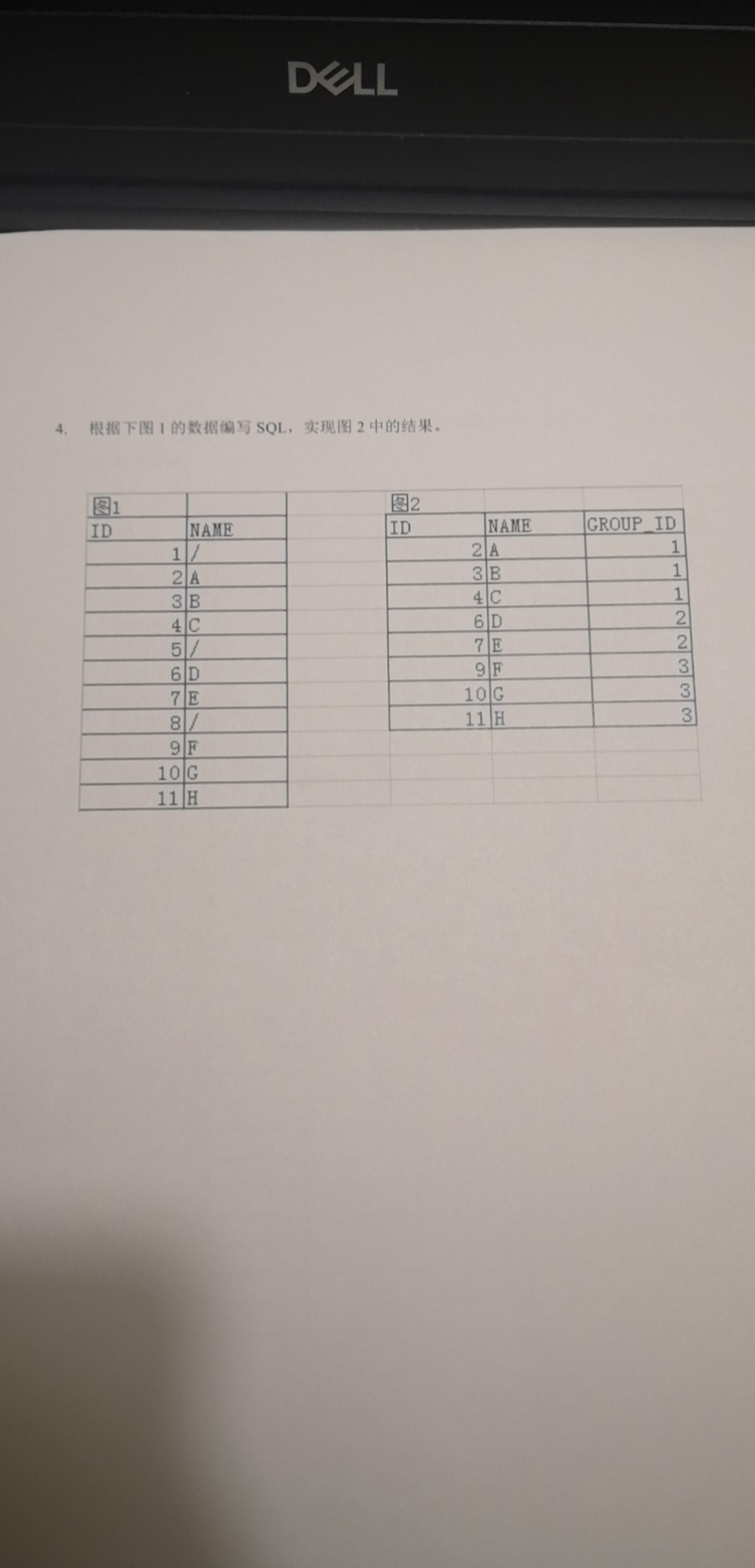
题目要求如下图所示:
二.解决方案
测试数据:
create table test_1 (id int,name string);
insert into test_1 (id,name) values (1,'/'),(2,'A'),(3,'B'),(4,'C'),(5,'/'),(6,'D'),(7,'E'),(8,'/'),(9,'F'),(10,'G'),(11,'H');
2.1 通过lag函数打标记
之前处理过几个求连续登陆时间的,看到题目,首先想到的是lag分析函数求上一行来标记,然后再通过sum()来对标记求和
代码:
with tmp1 as
(
select id,name,lag(name,1,'N/A') over (order by id) pre_name
from test_1
),
tmp2 as
(
select id,name,case when pre_name = '/' then 1 else 0 end flag1
from tmp1
)
select id,name,sum(flag1) over (order by id) flag2
from tmp2
where name != '/';
测试记录:
hive>
> with tmp1 as
> (
> select id,name,lag(name,1,'N/A') over (order by id) pre_name
> from test_1
> ),
> tmp2 as
> (
> select id,name,case when pre_name = '/' then 1 else 0 end flag1
> from tmp1
> )
> select id,name,sum(flag1) over (order by id) flag2
> from tmp2
> where name != '/';
Query ID = root_20210113105331_43367829-d9ca-486e-a8bc-24c0e7cf12b6
Total jobs = 2
Launching Job 1 out of 2
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1610015767041_0017, Tracking URL = http://hp1:8088/proxy/application_1610015767041_0017/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1610015767041_0017
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2021-01-13 10:53:39,253 Stage-1 map = 0%, reduce = 0%
2021-01-13 10:53:45,459 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.77 sec
2021-01-13 10:53:52,713 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.49 sec
MapReduce Total cumulative CPU time: 5 seconds 490 msec
Ended Job = job_1610015767041_0017
Launching Job 2 out of 2
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1610015767041_0018, Tracking URL = http://hp1:8088/proxy/application_1610015767041_0018/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1610015767041_0018
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 1
2021-01-13 10:54:05,265 Stage-2 map = 0%, reduce = 0%
2021-01-13 10:54:11,453 Stage-2 map = 100%, reduce = 0%, Cumulative CPU 1.96 sec
2021-01-13 10:54:17,634 Stage-2 map = 100%, reduce = 100%, Cumulative CPU 4.75 sec
MapReduce Total cumulative CPU time: 4 seconds 750 msec
Ended Job = job_1610015767041_0018
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.49 sec HDFS Read: 9078 HDFS Write: 264 HDFS EC Read: 0 SUCCESS
Stage-Stage-2: Map: 1 Reduce: 1 Cumulative CPU: 4.75 sec HDFS Read: 8338 HDFS Write: 233 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 10 seconds 240 msec
OK
2 A 1
3 B 1
4 C 1
6 D 2
7 E 2
9 F 3
10 G 3
11 H 3
Time taken: 47.526 seconds, Fetched: 8 row(s)
hive>
2.2 省略lag函数直接通过标记sum汇总
其实’/'已经是比较了,无需再使用lag
代码:
select id,name,groupid
from
(
select id,name,sum(case when name = '/' then 1 else 0 end) over (order by id) groupid
from test_1
) tmp1
where name != '/';
测试记录:
hive>
>
>
> select id,name,groupid
> from
> (
> select id,name,sum(case when name = '/' then 1 else 0 end) over (order by id) groupid
> from test_1
> ) tmp1
> where name != '/';
Query ID = root_20210113112024_20a42b2b-b0ac-4adf-ad35-95d83389ff52
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1610015767041_0019, Tracking URL = http://hp1:8088/proxy/application_1610015767041_0019/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1610015767041_0019
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2021-01-13 11:20:31,542 Stage-1 map = 0%, reduce = 0%
2021-01-13 11:20:37,714 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.79 sec
2021-01-13 11:20:44,908 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.63 sec
MapReduce Total cumulative CPU time: 5 seconds 630 msec
Ended Job = job_1610015767041_0019
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 5.63 sec HDFS Read: 10159 HDFS Write: 233 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 5 seconds 630 msec
OK
2 A 1
3 B 1
4 C 1
6 D 2
7 E 2
9 F 3
10 G 3
11 H 3
Time taken: 22.922 seconds, Fetched: 8 row(s)
hive>
2.3 通过id与row_number()求差值
其实有明显的分隔符,可以考虑id与row_number()求差值来进行分组
代码:
select id,name,id - row_number() over(order by id) groupid
from test_1
where name != '/';
;
测试记录:
hive>
>
> select id,name,id - row_number() over(order by id) groupid
> from test_1
> where name != '/';
Query ID = root_20210113112532_82d5b502-42a1-4d84-8adf-a2662971e2ae
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1610015767041_0020, Tracking URL = http://hp1:8088/proxy/application_1610015767041_0020/
Kill Command = /opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/hadoop/bin/hadoop job -kill job_1610015767041_0020
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2021-01-13 11:25:40,503 Stage-1 map = 0%, reduce = 0%
2021-01-13 11:25:47,850 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.09 sec
2021-01-13 11:25:54,025 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 8.24 sec
MapReduce Total cumulative CPU time: 8 seconds 240 msec
Ended Job = job_1610015767041_0020
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 8.24 sec HDFS Read: 10082 HDFS Write: 233 HDFS EC Read: 0 SUCCESS
Total MapReduce CPU Time Spent: 8 seconds 240 msec
OK
2 A 1
3 B 1
4 C 1
6 D 2
7 E 2
9 F 3
10 G 3
11 H 3
Time taken: 22.696 seconds, Fetched: 8 row(s)
hive>