本文举例为32位Linux
物理内存
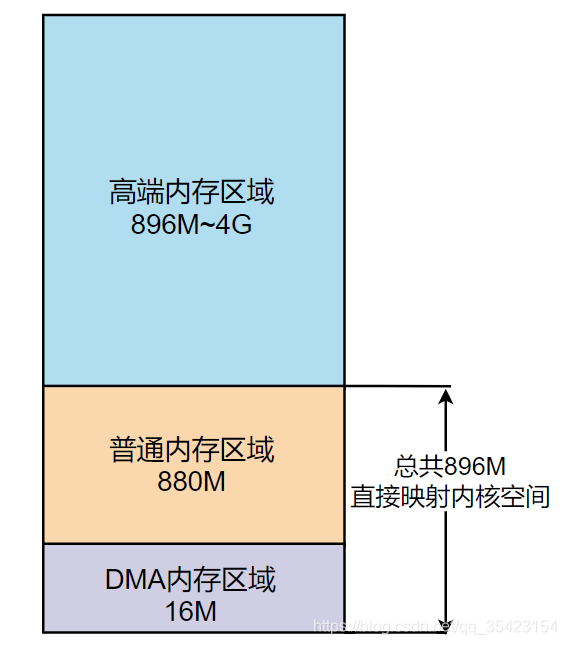
在Linux中,内核将物理内存划分为三个区域。
- DMA内存区域(ZONE_DMA):包含
0M~16M之内的内存页框,可以直接映射到内核空间中的直接映射区 - 普通内存区域(ZONE_NORMAL):包含
16MB~896M以上的内存页框,可以直接映射到内核空间中的直接映射区。与DMA加起来总共896M - 高端内存区域(ZONE_HIGHMEM):包含
896M以上的内存页框,不可以进行直接映射,可以通过高端内存映射区中的永久内存映射区以及临时内存映射区(固定内存映射区中的一部分)来对这块物理内存进行访问
内存分布如下图
物理内存分配
内存碎片
在Linux中,通过分段和分页的机制,将物理内存划分为4k大小的内存页(page),并且将页作为物理内存分配与回收的基本单位。通过分页机制我们可以灵活的对内存进行管理。
- 如果用户申请了小块内存,我们可以直接分配一页给它,就可以避免因为频繁的申请、释放小块内存而发起的系统调用带来的消耗。
- 如果用户申请了大块内存,我们可以将多个页框组合成一大块内存后再进行分配,非常的灵活。
但是,这种直接的内存分配存在着大量的问题,非常容易导致内存碎片的出现,下面就分别介绍内部碎片和外部碎片的情况。
外部碎片
当我们需要分配大块内存时,操作系统会将连续的页框组合起来,形成大块内存,来将其分配给用户。但是,频繁的申请和释放内存页,就会带来内存外碎片的问题,如下图。
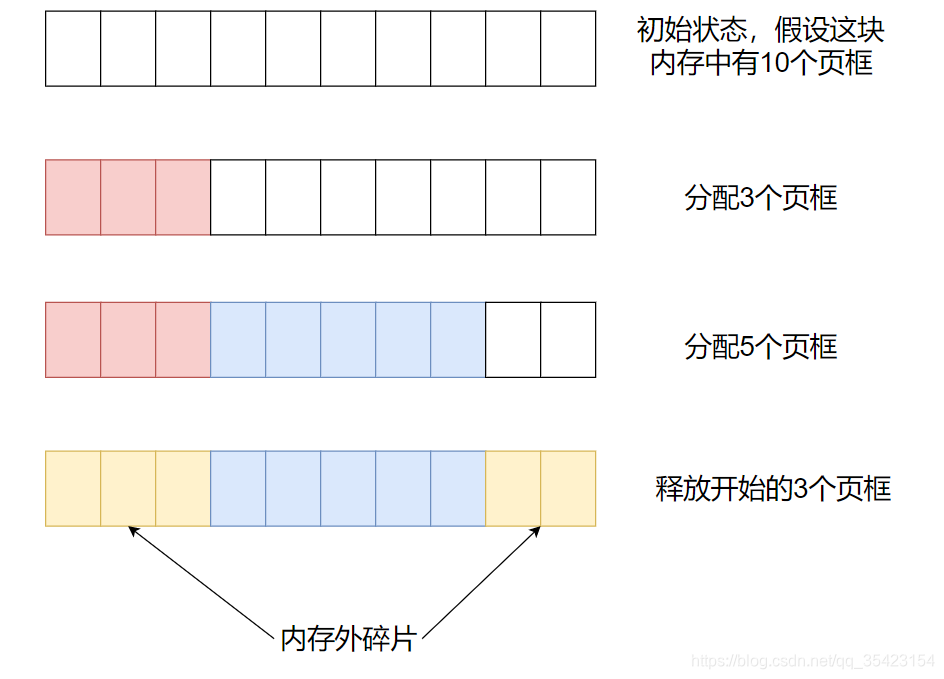
假设我们这块内存块中有10个页框,我们一开始先是分配了3个页框给进程A,而后又分配了5个页框给进程B。当进程A结束后,其释放了申请的3个页框,此时我们剩余空间就是内存块起始位置的3个页框,以及末尾位置的2个页框。
假如此时我们运行了进程C,其需要5个页框的内存,此时虽然这块内存中还剩下5个页框,但是由于我们频繁的申请和释放小块空间导致内存碎片化,因此如果我们想申请5个页框的空间,只能到其他的内存块中申请。久而久之,就造成了大量的空间浪费,这也就是内存外碎片的问题。
内部碎片
一开始的时候也说了,由于页是物理内存分配的基本单位,因此即使我们需求的内存很小,Linux也会至少给我们分配4k的内存页。
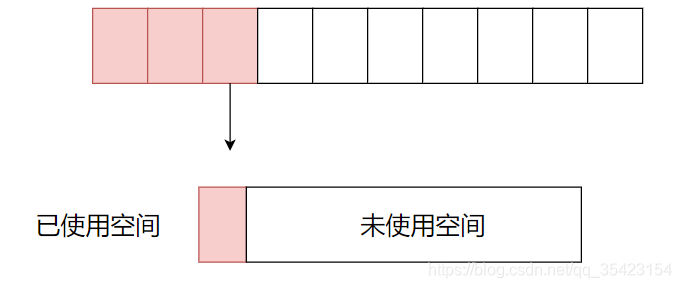
如上图,倘若我们需求的只有几个字节,那该内存页中又有大量的空间未被使用,造成了内存浪费的问题,而如果我们频繁的进行小块内存的申请,这种浪费现象就会愈发严重,这也就是内存内碎片的问题
为了解决上述的内存碎片问题,Linux中引入了伙伴系统以及slab分配器
要想解决内存外碎片的问题,无非就两种方法
- 外碎片问题的本质就是空间不连续,所以可以将非连续的空闲页框映射到连续的虚拟地址空间
- 记录现存的空闲连续页框块的情况,尽量避免为了满足小块内存的请求而分割大的空闲块。
Linux选择了第二种方法来解决这个问题,即引入伙伴系统算法,来解决内存外碎片的问题。
伙伴系统(buddy system)
什么是伙伴系统算法呢?其实就是把相同大小的连续页框块用链表串起来,这也页框之间看起来就像是手拉手的伙伴,这也就是其名字的由来。
伙伴系统将所有的空闲页框分组为11块链表,每个块链表分别包含大小为1,2,4,8,16,32,64,128,256,512和1024个连续页框的页框块,即2的0~10次方,最大可以申请1024个连续页框,对应4MB(1024 * 4k)大小的连续内存。每个页框块的第一个页框的物理地址是该块大小的整数倍。
如下图
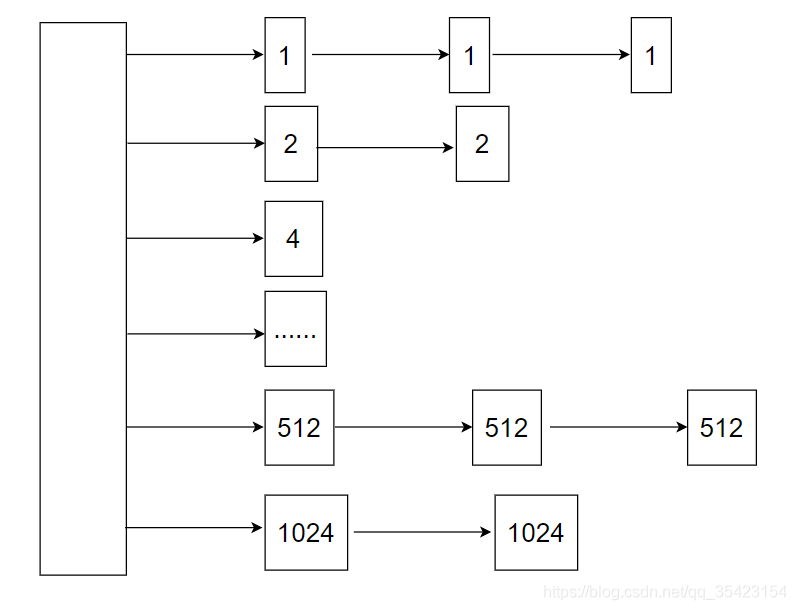
因为任何正整数都可以由 2^n 的和组成,所以我们总能通过拆分与合并,来找到合适大小的内存块分配出去,减少了外部碎片产生 。
倘若我们需要分配1MB的空间,即256个页框的块,我们就会去查找在256个页框的链表中是否存在一个空闲块,如果没有,则继续往下查找更大的链表,如查找512个页框的链表。如果存在空闲块,则将其拆分为两个256个页框的块,一个用来进行分配,另一个则放入256个页框的链表中。
释放时也同理,它会将多个连续且空闲的页框块进行合并为一个更大的页框块,放入更大的链表中
slab分配器
虽然伙伴系统很好的解决了内存外碎片的问题,但是它还是以页作为内存分配和释放的单位,而我们在实际的应用中则是以字节为单位,例如我们要申请2个字节的空间,其还是会向我们分配一页,也就是4096字节的内存,因此其还是会存在内存内碎片的问题。
为了解决这个问题,slab分配器就应运而生了。其以字节为基本单位,专门用于对小块内存进行分配。slab分配器并未脱离伙伴系统,而是对伙伴系统的补充,它将伙伴系统分配的大内存进一步细化为小内存分配。
那么它的原理是什么呢?
对于内核对象,生命周期通常是这样的:分配内存->初始化->释放内存。而内核中如文件描述符、pcb等小对象又非常多,如果按照伙伴系统按页分配和释放内存,不仅存在大量的空间浪费,还会因为频繁对小对象进行分配-初始化-释放这些操作而导致性能的消耗。
所以为了解决这个问题,对于内核中这些需要重复使用的小型数据对象,slab通过一个缓存池来缓存这些常用的已初始化的对象。
当我们需要申请这些小对象时,就会直接从缓存池中的slab列表中分配一个出去。而当我们需要释放时,我们不会将其返回给伙伴系统进行释放,而是将其重新保存在缓存池的slab列表中。通过这种方法,不仅避免了内存内碎片的问题,还大大的提高了内存分配的性能。
下面就由大到小,来画出底层的数据结构
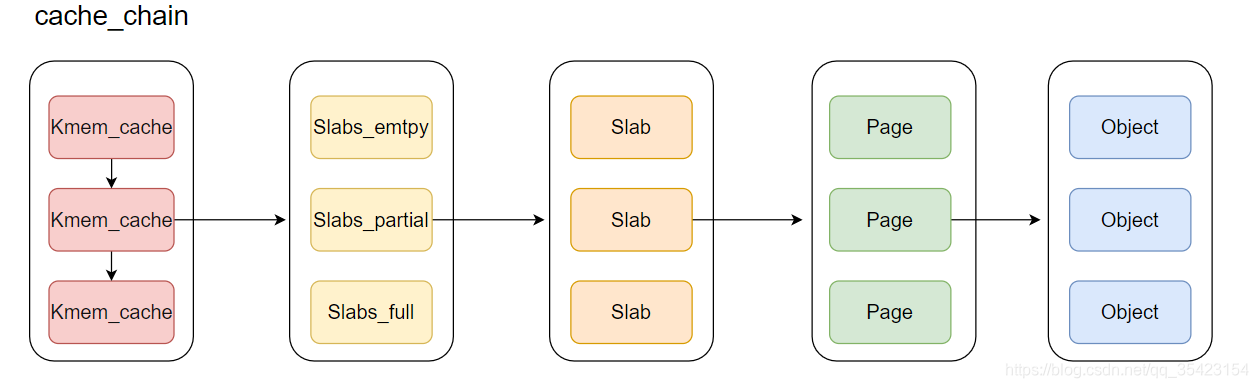
kmem_cache是一个cache_chain的链表,描述了一个高速缓存,这个缓存可以看做是同类型对象的一种储备,每个高速缓存包含了一个slab的列表,这通常是一段连续的内存块,并包含3种类型的slabs链表:
- slabs_full(完全分配的slab)
- slabs_partial(部分分配的slab)
- slabs_empty(空slab,或者没有对象被分配)。
slab是slab分配器的最小单位,在具体实现上一个slab由一个或者多个连续的物理页组成(通常只有一页)。单个slab可以在slab链表中进行移动,例如一个未满的slab节点,其原本在slabs_partial链表中,如果它由于分配对象而变慢,就需要从原先的slabs_partial中删除,插入到完全分配的链表slabs_full中
这里来具体举一个例子,来说明上述之间结构的关系。
假设每一个对象就是一瓶牛奶,kmem_cache结构描述的slab缓存池其实就相当于我们家中的牛奶箱,箱中存储着很多瓶牛奶。
当我们想喝牛奶(分配内存)时,其实就是从牛奶箱中取出一瓶牛奶。由于牛奶箱并非无限,因此总会有拿空的一天,当我们的箱子空了之后,自然就要去商店再买一箱回来。
而商店其实就相当于slabs_partial链表,商店中不仅有现货,它的仓库中还有大量的牛奶储备,仓库即相当于slabs_empty,当我们现货不够的时候就会去仓库中取货,放到商店中进行售卖。
那如果商店的库存也用完了呢?那自然就需要去厂家进货,这里的厂家其实就是我们的伙伴系统,所以结合这个例子,给出内核中slab分配对象的全过程
- 根据对象的类型找到
cache_chain中对应的高速缓存kmem_cache - 如果
slabs_partial链表中还有未分配的空间,则为其分配对象。如果分配对象之后空间已满,则移动slab到slabs_full链表 - 如果
slabs_partial链表没有未分配的空间,则去查看slabs_empty链表 - 如果
slabs_empty还有未分配的空间,则为其分配对象,同时移动slab进入slabs_partial链表中 - 如果
slabs_empty也没有未分配的空间,则说明此时空间不足,就会请求伙伴系统分页,并创建新的空闲slab节点放入slabs_empty链表中,回到步骤3。
从上面可以看出,slab分配器的本质其实就是通过将内存按使用对象不同再划分成不同大小的空间,即对内核对象的缓存操作