贴一下汇总贴:论文阅读记录
论文链接:《Sequence to Sequence Learning with Neural Networks》
一、摘要
深度神经网络(DNNs)是一种功能强大的模型,在困难的学习任务中取得了优异的性能。尽管DNNs在有大型标记训练集的情况下工作良好,但它们不能用于将序列映射到序列。在这篇文章中,我们提出了一种一般的端到端方法来学习序列,它对序列结构做出最小的假设。我们的方法使用多层长短期记忆(LSTM)将输入序列映射到一个固定维数的向量,然后使用另一个深度LSTM从向量中解码目标序列。我们的主要结果是,在WMT-14数据集的英语到法语翻译任务中,LSTM生成的翻译在整个测试集中达到了34.8分的BLEU分数,其中LSTM的BLEU分数在词汇表外的单词上被处罚。此外,LSTM对长句没有困难。为了进行比较,基于短语的SMT系统在同一数据集上获得了33.3的BLEU分数。当我们使用LSTM对上述SMT系统产生的1000个假设重新排序时,它的BLEU分数增加到36.5,这接近于以前的技术水平。LSTM还学习了敏感的词组和句子表征,这些词组和句子表征对词序敏感,并且相对于主动语态和被动语态不变。最后,我们发现在所有源句(但不是目标句)中颠倒单词的顺序显著提高了LSTM的性能,因为这样做在源句和目标句之间引入了许多短期依赖关系,使优化问题更容易。
文章主要内容(model)
- 使用了两种不同的LSTM:一种用于输入序列,另一种用于输出序列,这样虽然增加了模型参数,但计算成本的增加可以忽略不计,并且可以提高模型的泛化能力。
- 发现深度LSTM明显优于浅层LSTM,因此选择了一个4层的LSTM。
- 发现颠倒输入句子的单词顺序非常有价值。(一个段落中有含义相近的句子彼此接近,而含义不同的句子会距离很远)
二、结论
- 大规模机器翻译任务中,词汇量有限的大型深度LSTM的性能优于词汇量无限的基于标准的smt系统。如果有足够的训练数据,LSTM在许多其他序列学习问题上也可以做得很好。
- 重要的是找到一个问题编码具有最大数量的短期依赖,因为它们使学习问题更简单。
- 在反向数据集上训练的LSTM在翻译长句子时几乎没有困难。
- 证明了一个简单、直接和相对未优化的方法可以胜过一个成熟的SMT系统,因此进一步的工作可能会导致更高的翻译准确性。这些结果表明,我们的方法很可能在其他具有挑战性的序列对序列问题上做得很好。
三、DNNs
深度神经网络(DNNs)是非常强大的机器学习模型,在语音识别和视觉对象识别等困难问题上取得了优异的性能。而且,只要标记的训练集有足够的信息来指定网络参数,就可以用有监督的反向传播来训练大型DNNs。
尽管DNNs具有灵活性和力量,但它只适用于输入和目标可以用固定维数的向量进行合理编码的问题。这是一个重要的限制,因为许多重要的问题都是用长度未知的序列来表达的。
于是,本文证明了一个简单的应用LSTM体系结构可以解决这种序列对序列(seq2seq)的问题。
- 使用一个LSTM阅读输入序列
- 使用另一个LSTM从向量中提取输出序列(本质是一个语言模型)
四、seq2seq
使用固定大小的模型实现一个变长序列到变长序列的模型。输入一个变长的句子,返回一个变长的句子,故可以用来执行翻译任务和起标题任务,人机对话等。是RNN的衍生模型。
一个RNN充当编码器,他将输入的变长序列编码成固定长度的上下文向量,理论上,这个上下文向量,也就是RNN最终的隐藏层包含了输入的语义信息,(类似于CNN卷积后的中间层包含了图片的边缘、色彩等信息一样)。第二个RNN充当解码器,他接受输入和上下文向量,并返回对下一个单词的猜测和下一次迭代中使用的隐藏状态。(本文使用的是LSTM)
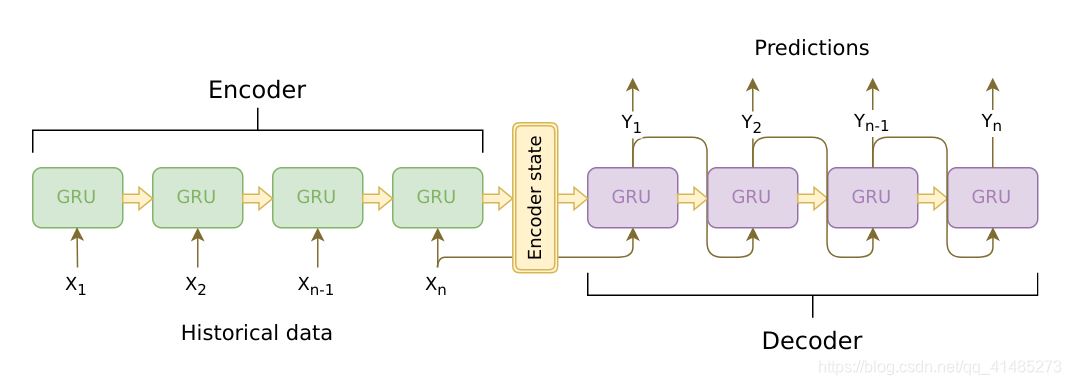
模型流程
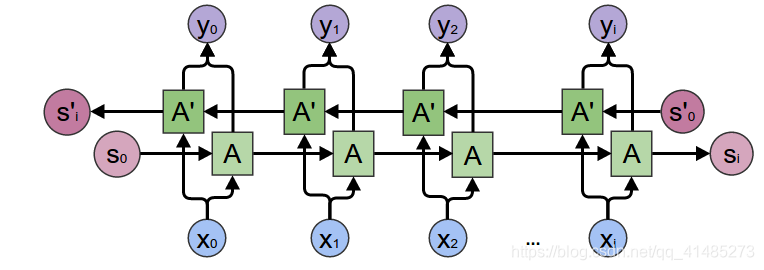
- 将单词索引转化为embeddings
- 为RNN模块打包填充序列
- 正向通过GRU
- 解填充
- 对双向GRU输出进行求和
- 返回输出和最终的隐藏层状态