1. 算法概述
**
ELM算法针对的问题是单隐层的前馈神经网络(single-hidden layer feedforward neural networks,SLFNs),算法特点在于输入层到隐层的权重W和偏差B可以随机设定,隐层激励函数具有无限可微的特征即可(常用的有radial basis、sine、cosine、exponential等函数),而输出层权重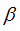
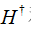
这里的伪逆矩阵又称广义逆矩阵,即Moore-Penrose generalized inverse matrix,对于矩阵A的广义逆矩阵G满足以下表达式:
当 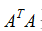
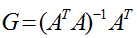
与传统的应用误差梯度下降学习策略的BP神经网络相比,ELM的优点在于学习速度很快,泛化精度高,而且不会陷入局部最小值,可以采用多种激励函数(满足无限可微即可)。而与其他算法相比,例如很火的SVM来说,ELM算法计算速度也更有优势。
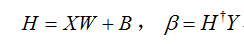
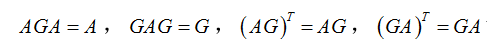
以上内容均出自黄光斌老师的论文:
Huang G B, Zhu Q Y, Siew C K. Extreme learning machine: Theory and
applications[J]. Neurocomputing, 2006, 70(1-3):489-501.
2. 在线学习和离线学习对比
批量学习(Batch Learning):
(1) 样本全部同时进入模型;
(2) 梯度下降的方法容易陷入局部最优;
(3) 学习并行性,速度快,但耗费存储量大。
在线学习(Online Learning):
(1) 样本按顺序进入模型,不断修正模型参数;
(2) 随机性强,不容易陷入局部最优;
(3) 学习串行性,需要依次迭代速度慢,但耗费存储量小。
非线性函数 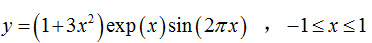
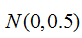
表1 不同学习策略对比结果

3 ELM 和 OLS_RBF 对比实验
OLS_RBF是正交最小二乘径向基神经网络模型,具体内容参见这篇文章:
- 1
实验选用复杂的非线性函数,非线性函数
3.1 隐层中心从样本中选择
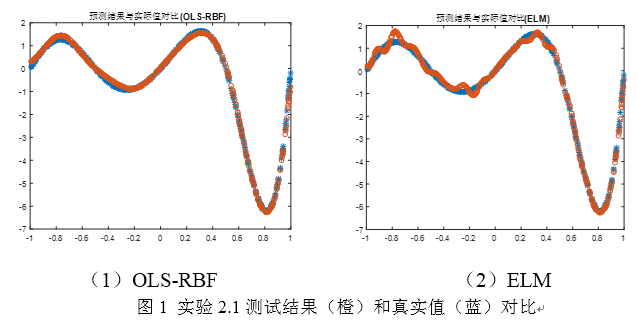
这种条件下,ELM计算速度快,但精度是比OLS_RBF差的,且OLS_RBF具有较小的模型结构。


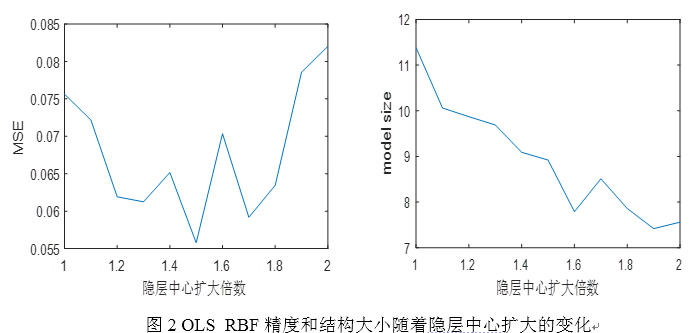
3.2 隐层中心由样本范围扩大若干倍数
OLS_RBF的隐层中心由原来的[-1,1]扩大若干倍数(1至2,间隔0.1)。如图2所示,随着隐层中心选取范围的扩大,模型误差MSE总体先下降后上升,在1.5左右最优,而模型结构大小呈现持续降低。
由于ELM的隐层中心数较多,隐层此次扩大倍数增加,由原来的[-1,1]扩大若干倍数(1至100,间隔1),而模型结构大小不变,设置为100,结果如图3所示。
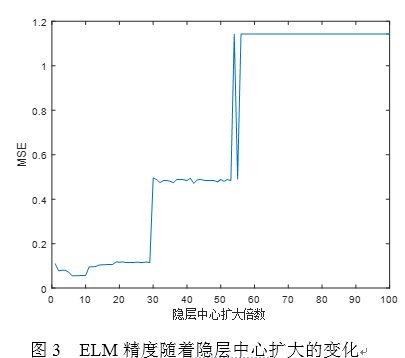
随着隐层中心范围扩大,ELM的误差MSE也是先下降后上升,在10左右取得最优
比较两个模型在最优扩大倍数的MSE发现,两者精度几乎一致,都是0.55的水平。因为所测试的倍数范围有限,因此可能模型只获得局部最优。
3.3 样本服从正态分布的情况
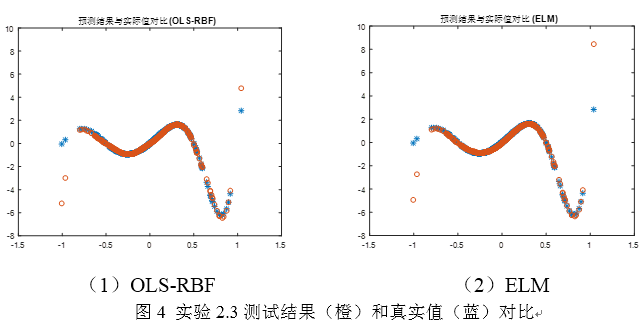
之前的实验样本都是服从均匀分布的,现在让样本服从正态分布,x~N(0,0.3),对两个模型分别取最优的参数(大概选取),由于此次实验有误差离群点,因此只从曲线跟踪图像对两者进行对比。如图4,两种模型在数据密集区域(0附近)的精度都比较高,在数据稀疏区域(远离0)精度都较差,对于绝大部分点,两者的预测精度差别不大(ELM略微占优)。
**%% 清空环境变量
clc;
clear all
close all
nntwarn off;
%% 数据载入
load data;
a=data;
%% 选取训练数据和测试数据
for i=1:6
p(i,:)=[a(i,:),a(i+1,:),a(i+2,:)];
end
% 训练数据输入
p_train=p(1:5,:);
% 训练数据输出
t_train=a(4:8,:);
% 测试数据输入
p_test=p(6,:);
% 测试数据输出
t_test=a(9,:);
% 为适应网络结构 做转置
p_train=p_train';
t_train=t_train';
p_test=p_test';
%% 网络的建立和训练
% 利用循环,设置不同的隐藏层神经元个数
nn=[7 11 14 18];
for i=1:4
threshold=[0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1;0 1];
% 建立Elman神经网络 隐藏层为nn(i)个神经元
net=newelm(threshold,[nn(i),3],{'tansig','purelin'});
% 设置网络训练参数
net.trainparam.epochs=1000;
net.trainparam.show=20;
% 初始化网络
net=init(net);
% Elman网络训练
net=train(net,p_train,t_train);
% 预测数据
y=sim(net,p_test);
% 计算误差
error(i,:)=y'-t_test;
end**
三、运行结果

四、备注
完整代码或者代写添加QQ1575304183