BERT,XLNET等分词方法
先给一个结论吧,BERT使用的是wordpiece的分词方法,XLNET和transformer-xl使用的是sentencepiece的切分方法。
概述
在NLP中,分词的形式越来越多,从最开始的字切分,词切分,发展到更细粒度的BPE,以及跨语言的sentencepiece等等的切分方法。
子词层面的切分方法是一种有效的文本切分方法,该方法可以有效的减小词表大小,并且让所有的词都能够被覆盖,并且使得且分开的子词都携带一定的含义,这就有效的解决了当前机器阅读文本所遇到的所有困境。
Byte Pair Encoding (BPE)
一个相当流行的子词切分方法叫做BPE。BPE最初用于通过查找常见的字节对组合来帮助压缩数据。它也可以应用于NLP,以找到表示文本的最有效方法。
FloydHub is the fastest way to build? train and
deploy deep learning models. Build deep learning
models in the cloud. Train deep learning models
对于这个案例,我们可以统计每个单词出现的次数:
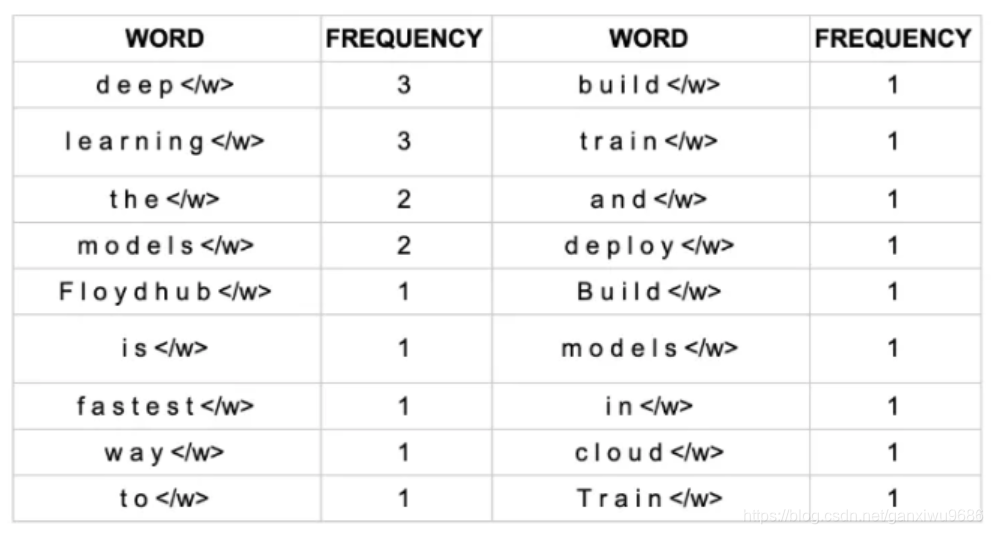
首先你会看到每一个单词后面都会有一个这是表示单词的结尾,告诉算法去识别这个边界。
同样我们对每一个字符出现的次数做统计:
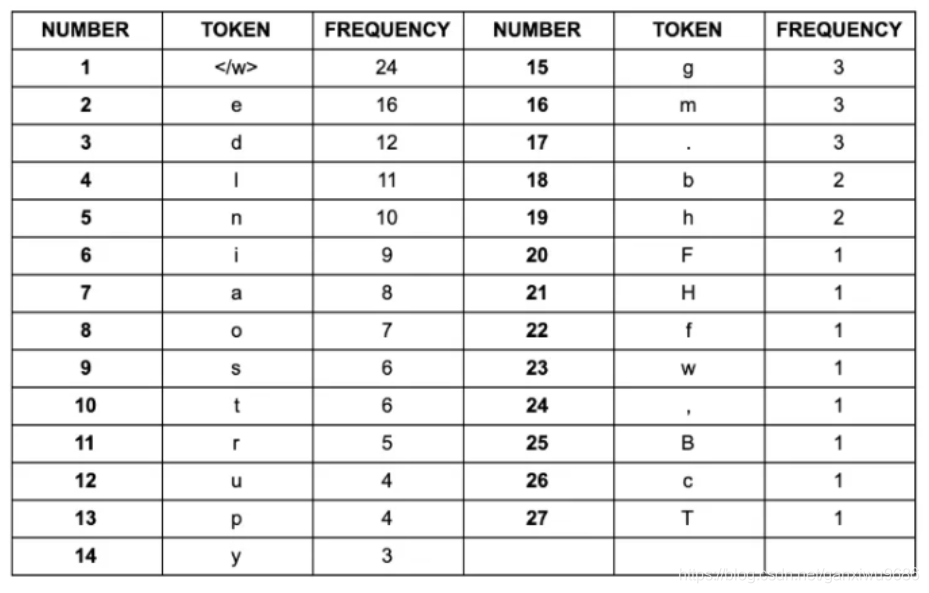
BPE算法的目标就是找到一种方法,可以用最少的token来表示你的文本。
BPE算法包含以下几步:
- 准备一个足够大的训练集
- 确定期望获得的子词词表大小
- 将单词切分成字符,并在单词后面加上< w>。例如"deep"变成"d e e p < w>
- 寻找最常见的成对字符,例如de出现7次,为最高出现频次。
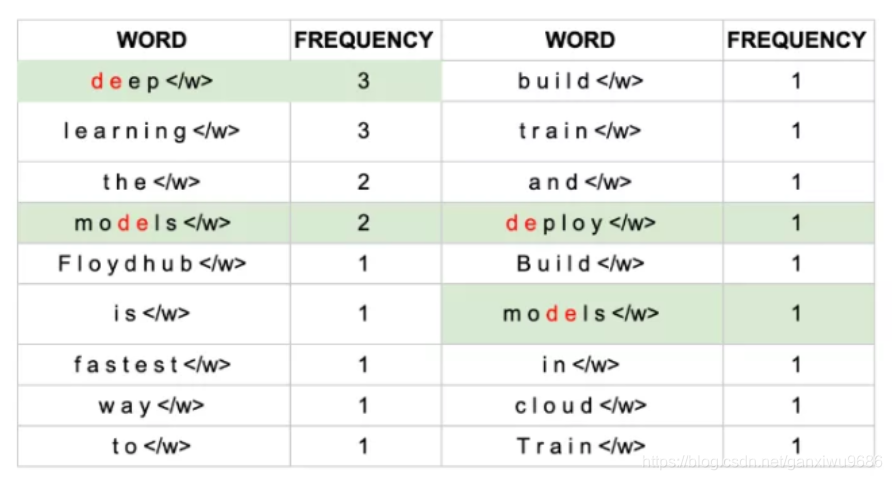
de加入词表。重新计算:
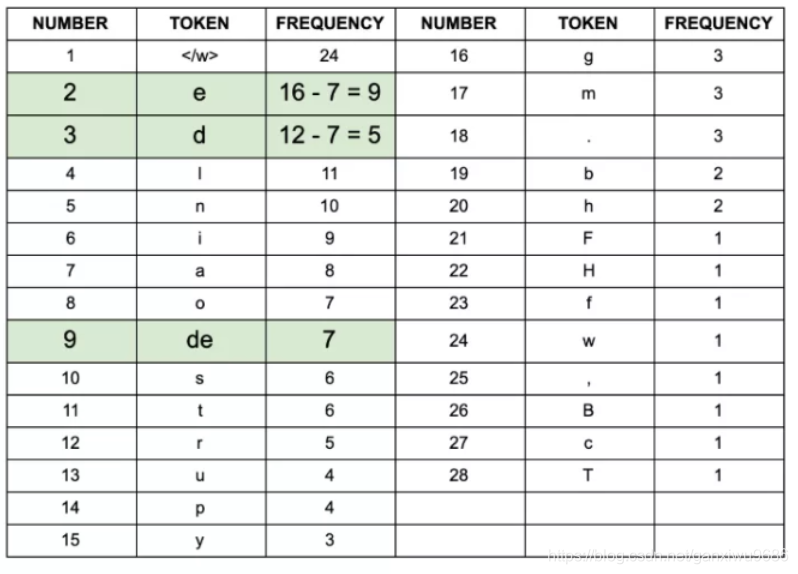
重复上述过程,直到达到停止条件。
unigram子词切分(Unigram subword tokenization)
在BPE算法中,我们需要贪婪的去搜索最常一起出现的字符,但该方法会有显著的缺点,就是它可能使得最终的词表显得存在歧义,举个例子:倘若通过BPE我们获得如下的子词集合:
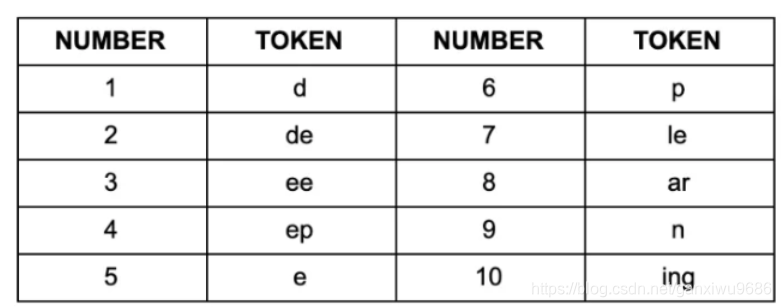
用该子词集合对"deep learning"切分,你会有以下困惑:

究竟哪种才是最合适的切分方法。
为了解决这个问题,我们需要对确定子词切分的优先级顺序,以便对于相同的短语获得相同的分词结果。
因此有人提出了使用unigram语言模型的方法来选择最合适的子词切分方法。与BPE不同,该方法尝试选择最可能的切分方法,而不是去选择最好的切分方法。
Unigram子词切分方法如下所示:
- 准备一个足够的大训练语料库
- 定义期望的子词表大小
- 用EM算法估计每一种子词的概率
- 对于每个子词计算loss,该loss表示当前子词被丢弃时似然的减少量。按照loss对子词排序,并仅保留排在前面的80%的子词
- 重复上一过程直到此表大小达到目标值,或者说在某轮迭代后词表大小不再改变。
到目前为止我们已经介绍了两种子词切分手段,但当你去看当前的一些流行的模型时,你还是会发现难以判断当前模型用的是哪一种子词切分算法。但这并不代表之前的一些知识都白学了,实际上大多时候,通过仔细地分析,你就会发现,这些模型中用的新的方法,都是以这两种模型为基础的。
例如在BERT模型中,一种叫做"WordPiece"的文本切分方法,下面会具体介绍该方法与BPE的联系。此外在ALBERT中用到的"SentencePiece"算法实际上是上面提到的两种算法的一种整合。
WordPiece
Word Piece方法与BPE非常的相似。首先我们将Word Piece方法认为是BPE和unigram方法的一个中间方法。如果你还记得的话,BPE首先考察两个token并考察各token对出现的频次,然后合并拥有最高频次的两个token。在每一步中,它仅仅考虑最常出现的token对。
而另一种可选的方法(WordPiece)是考察合并特定对的token对整体的潜在影响,这个可以通过使用概率语言模型来实现,在每一步迭代中,选择合并能够使得整体似然获得最大提升的token对,(通过合并新的token对时的概率减去单个token时的概率)。
那么WordPiece方法与原本的unigram方法的区别又在哪里呢?
主要的不同在于,WordPiece仍然还是一个贪婪的方法。该方法在每一次合并时候仍然选择最优的token对合并,与BPE不同的是WordPiece使用似然而不是频次。而Unigram方法则不同,Unigram方法是一个纯粹基于概率的方法,从通过概率选择要合并的token以及基于概率判断是否合并这些token。
WordPiece具体流程:
- 准备一个大的语料库
- 定义期望的子词表大小
- 将单词切分成字符
- 基于上一步构建语言模型
- 选择合并能够使得语言模型似然增加的字符对作为新的子词
- 重复上一步,直到达到目标词表,或者似然増加不再明显
小结
BPE :BPE在每一次迭代中通过频次识别最好的子词组合,并最终达到设定的词表大小。
WordPiece:与BPE相同用频次识别潜在的合并对象,但最终合并能够使得整体似然提升最大的子词对。
Unigram:—个完全基于概率的模型,每一次迭代中去除子词表中使得整体似然增加较少少的子词,直到达到限定的词表大小。
SentencePiece
SentencePiece子词切分方法可以说是所有子词切分方法中的瑞士军刀。
BPE,和Unigram方法均假设输入的带切分的文本是已经切分的,只有这样BPE才可以统计频率,通常直接通过空格切分,但问题是,不是所有的语言都是以空格分割的,Unigram同样有该问题存在。
而SentencePiece则是直接输入原始文本而后可以做到所有接下来的事情。
那么SentencePiece是如何做到这点的呢?将所有字符编码成Unicode码(包括空格),这就避免了跨语言纠纷。
HuggingFace Tokenizers
HuggingFance这群人开发的Tokenizers工具包
from tokenizers import (ByteLevelBPETokenizer,BPETokenizer,SentencePieceBPETokenizer,BertWordPieceTokenizer)
tokenizer = SentencePieceBPETokenizer()
tokenizer.train{
["../blog_test.txt"], vocab_size=500, min_frequency=2)
output = tokenizer.encode(MThis is a test")
print(output.tokens)