
Motivation
文章的目的是希望评估一个RC系统的内部推理,即用一种更细粒度方式体现模型确实在推理。(相比较一些datasets通过预测supporting facts来体现模型推理能力)
对于之前的一些datasets,比如经常以who开头的提问,模型学习之后往往会从一些人名中选择答案。这种启发式的规则容易带来一些bias,而模型是否真正理解了原文,我们无从得知。
另一个问题,作者提到结合多源的infos is not always necessay,其实这一点我保留怀疑,对于某些开放域的问题,多源信息或者多文档还是比较需要的,怎么利用,什么时候利用,如何利用都是值得探讨的问题。
最近这种hot pot QA其实也存在一些weakness。
1, 通过标签训练让模型学会找到和问题相关的证据,但是从人类认知角度,并不能完全说明预测正确即推理正确。
2, 并不是所有的SFs都有助于推理,即某一个SF可能还包含其他无用信息。如图1。比如第一句话,
“Return to Olympus is the only album by the alternative rock band Malfunkshun ”其实包含了两个信息,对于Return to Olympus is the only album这个点来说,在推理的过程中是无用的,所以即使预测对了SFs,也不能很好证明模型真正在推理。
所以可不可以细化呢?
这篇文章的贡献:
1, 以一种更细密度的方式去体现模型的推理能力。
2, 论文提出了一种新的数据,对每一个支撑实时提供了落干个 Derivation。
3, 公开了一个众包的框架。(就是提供了一个众包平台,可以对现存的数据集标注。不是讨论的重点,就不细说了)
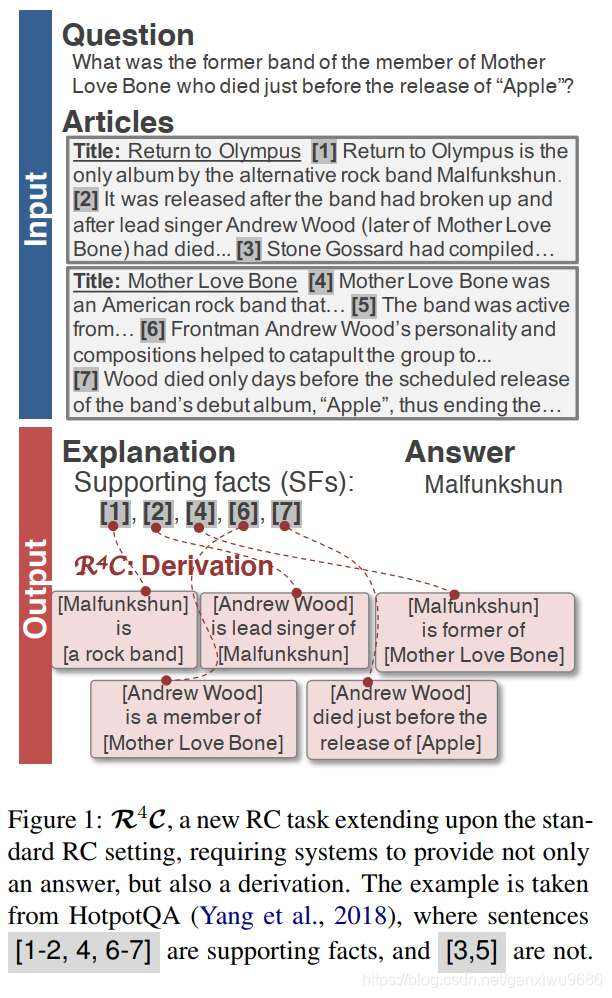
Task definition
这一部分介绍的是,通过什么样的形式进行推理。也就是细化到什么程度,用什么样的结构表示推理的过程。
论文使用一种半结构化的form,具体来说:
Each derivation step di is defined as a relational fact, i.e. di ≡ dh i ; dr i ; dt i, where dh i , dt i are entities (noun phrases), and dr i is a verb phrase representing a relationship between dt i and dh i
类似知识图谱里面的三元组,比如图1所示的那些,但是关系又不是那么严格。

Note:这些derivation 中的元素是否一定会出现在文中呢?
不是的,比如leader singer of,这也就给模型输出的derivation 不做限制,那么怎么取生成或者抽取derivation 是一个值得思考的问题。
Evaluation metrics
直接上图好理解一点,文章是先介绍公式,再说如何计算,当时看的有点晕。
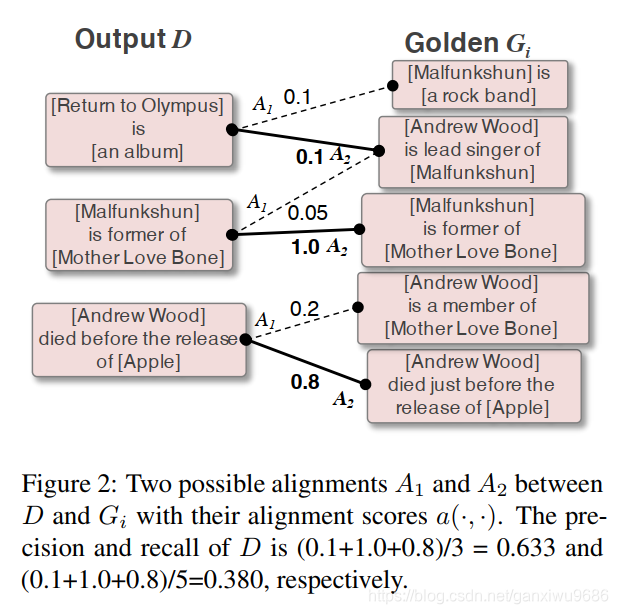
这里就可以简单看成两个部分,一部分是模型输出的output D,一部分是gold G。我们会通过各种排列组合A计算两两之间的相似性a(d, g)。直到满足下列公式:
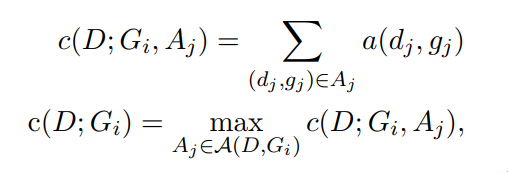
接下来我们就可以根据得到的打分,求得P,R,F,图2也给了计算的例子:
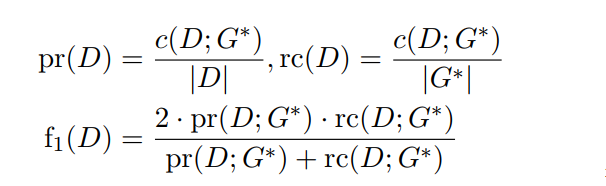
论文给出了三种计算得分的方式,其中的s文章使用 normalized Levenshtein distance :
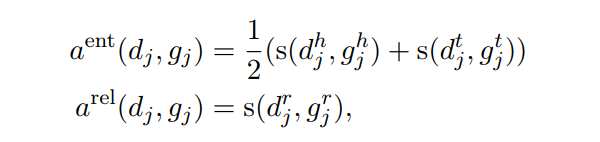
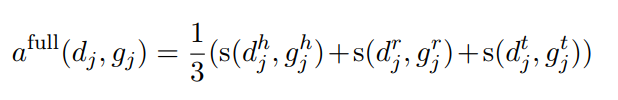
Data collection
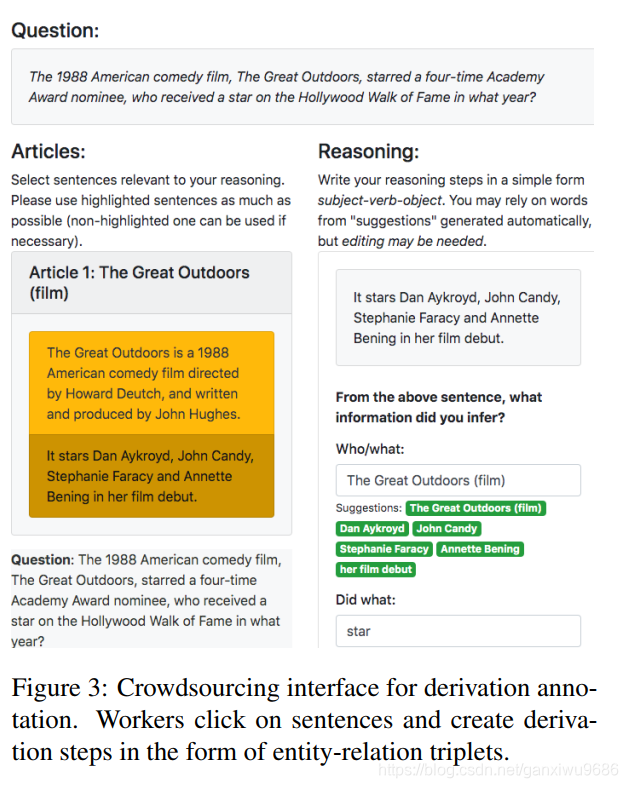
这个图主要描述的是众筹的一个界面。会提供一个问题一篇文章,以及里面的一些SFs。对那些标注的人员要求他们首先能够回答出问题,当然我们会给几个答案的选项提供参考。对于一些错误的数据集可以不回答(少数)。另外对于每一个支撑事实,都要求标注者从当前的SF里面选出对应的实体,或者短语,以及他们之间的动词关系。最终我们对于每个问题提供了三个Derivation。
Results
这个表比较好理解:
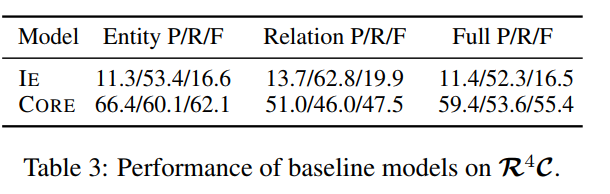
首先对于这个基线的实验结果。IE表示的是从支撑事实里面去抽取所有的实体以及它们的关系。CORE,表示的是从中抽取一些关键的信息。(,这里可能是拿问题的信息对这些信息做了一个匹配或者融合的方法吧),可以看到两个baseline在不同的打分函数下的评价指标。
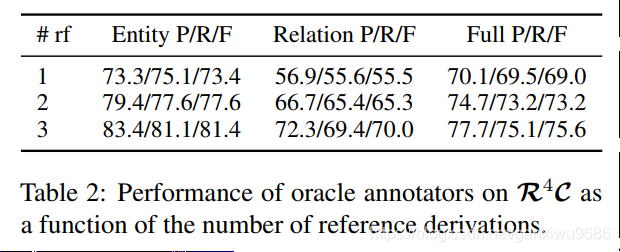
这个表我理解了一部分,纵向来看:
对于第2个实验是想说明随着给定的参考Derivation,数量越来越多,效果会越来越好。因为标注的数据集里面只提供了三个,所以这个地方的是三个的结果最好。
不知道四个会怎么样。哈哈
Question:
不过不太清楚这是谁和谁计算的指标,也就是D和G分别是什么?贴出原文

Sum up
总的来说,这篇文章的目的是希望评估一个RC系统的内部推理,即用一种更细粒度方式体现模型确实在推理。他给出了一个推理的特定的形式,而不是像之前的数据集只给一些SFs。SF prediction,感觉就是个预测,并不是真正的推理。
每天努力一点点,生活进步一点点!大家晚安!^ - ^