ROC
在分类任务中,经常基于错误率来衡量分类器任务的成功程度。错误率指的是在所有测试样例中错分的样例比例。实际上,这样的度量错误掩盖了样例如何被分错的事实。在机器学习中,有一个普遍适用的称为混淆矩阵(confusion matrix)的工具,它可以帮助人们更好地了解分类中的错误。
混淆矩阵
我们举个列子,并画出混淆矩阵表,假如宠物店有10只动物,其中6只狗,4只猫,现在有一个分类器将这10只动物进行分类,分类结果为5只狗,5只猫,那么我们画出分类结果混淆矩阵,并进行分析,如下(我们把狗作为正类):
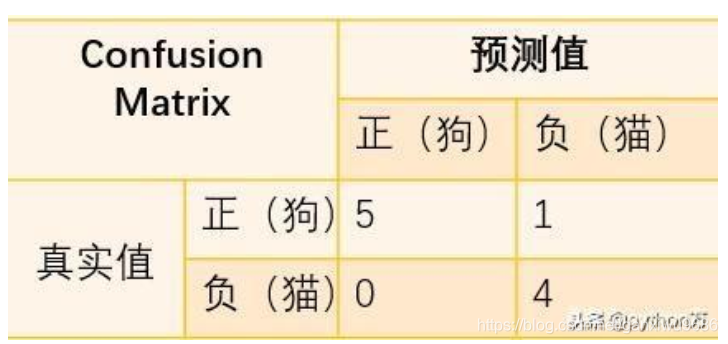
如果混淆矩阵中的非对角线元素均为0,就会得到一个近乎完美的分类器。
二分类问题在机器学习中是一个很常见的问题,经常会用到。ROC (Receiver Operating Characteristic) 曲线和 AUC (Area Under the Curve) 值常被用来评价一个二值分类器 (binary classifier) 的优劣。之前做医学图像计算机辅助肺结节检测时,在评定模型预测结果时,就用到了ROC和AUC,这里简单介绍一下它们的特点,以及更为深入地,讨论如何作出ROC曲线图和计算AUC值。
医学上的二分类
例如:在肺结节计算机辅助识别这一问题上,一幅肺部CT图像中有肺结节被认为是阳性(positive),没有肺结节被认为是阴性(negative)。
在实际检测时,就会有如下四种情况:
(1) 真阳性(True Positive,TP):检测有结节,且实际有结节;正确肯定的匹配数目;
(2) 假阳性(False Positive,FP):检测有结节,但实际无结节;误报,给出的匹配是不正确的;
(3) 真阴性(True Negative,TN):检测无结节,且实际无结节;正确拒绝的非匹配数目;
(4) 假阴性(False Negative,FN):检测无结节,但实际有结节;漏报,没有正确找到的匹配的数目。
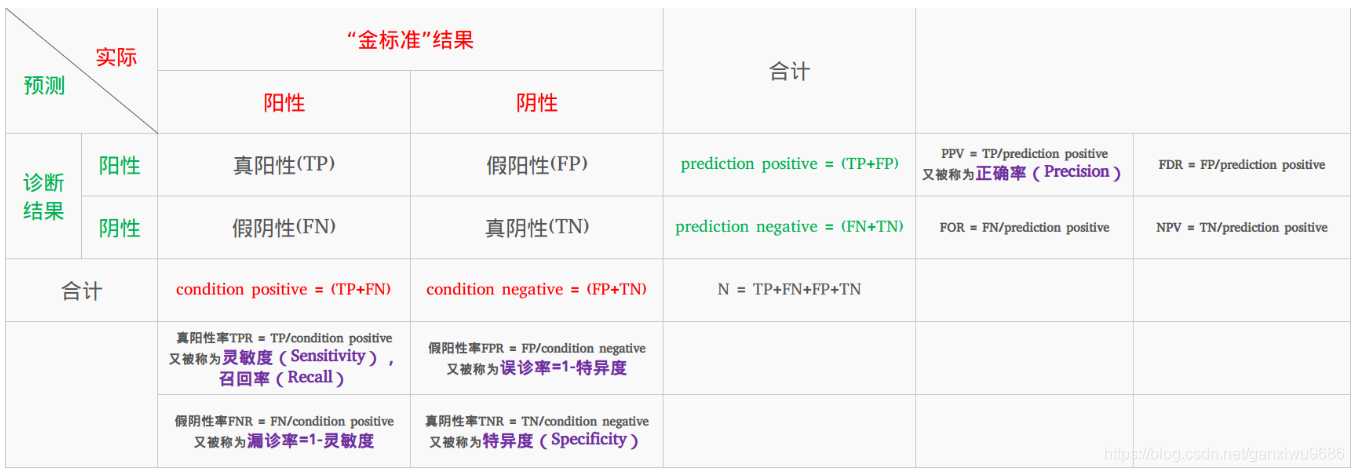
图源来自 https://www.deeplearn.me/1522.html
• 正确率(Precision):
Precision=TP/(TP+FP )
• 真阳性率(True Positive Rate,TPR),灵敏度(Sensitivity),召回率(Recall):
Sensitivity=Recall=TPR=TP/(TP+FN)
• 真阴性率(True Negative Rate,TNR),特异度(Specificity):
Specificity=TNR=TN/(FP+TN)
• 假阴性率(False Negatice Rate,FNR),漏诊率( = 1 – 灵敏度):
FNR=FN/(TP+FN)
• 假阳性率(False Positice Rate,FPR),误诊率( = 1 – 特异度):
FPR=FP/(FP+TN)
ROC曲线
接收者操作特征曲线(receiver operating characteristic curve),是反映敏感性和特异性连续变量的综合指标,roc曲线上每个点反映着对同一信号刺激的感受性。
对于分类器或者说分类算法,评价指标主要有precision,recall,F1 score等,以及这里要讨论的ROC和AUC。下图是一个ROC曲线的示例:
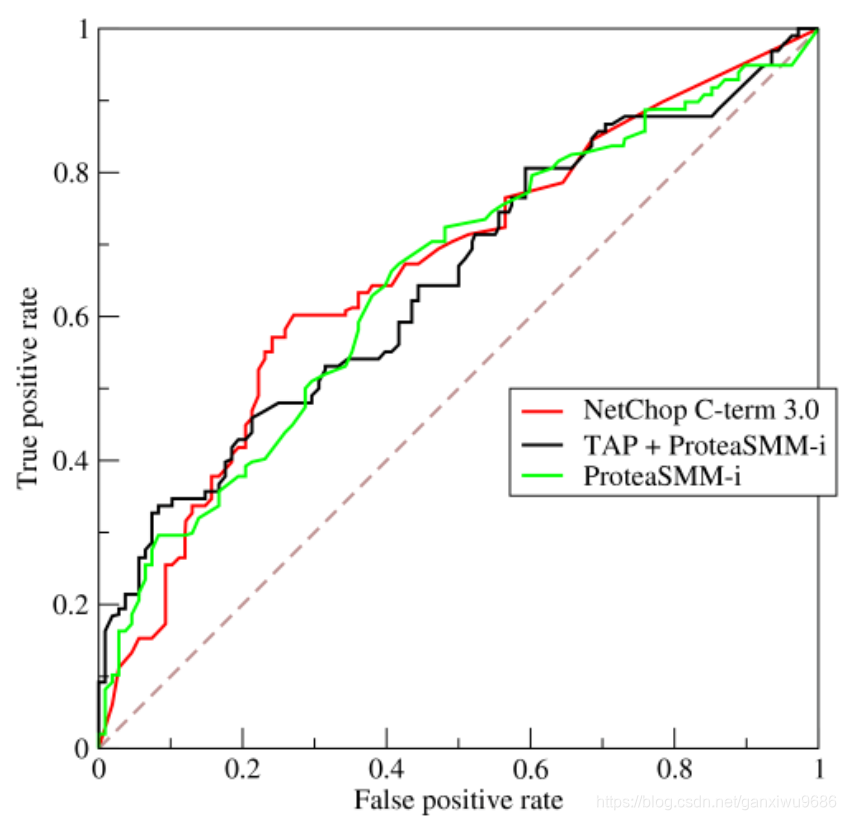
• 横坐标:Sensitivity,伪正类率(False positive rate, FPR),预测为正但实际为负的样本占所有负例样本 的比例;
• 纵坐标:1-Specificity,真正类率(True positive rate, TPR),预测为正且实际为正的样本占所有正例样本 的比例。
在一个二分类模型中,假设采用逻辑回归分类器,其给出针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组(FPR,TPR),在平面中得到对应坐标点。随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。
理想情况下,TPR应该接近1,FPR应该接近0。ROC曲线上的每一个点对应于一个threshold,对于一个分类器,每个threshold下会有一个TPR和FPR。比如Threshold最大时,TP=FP=0,对应于原点;Threshold最小时,TN=FN=0,对应于右上角的点(1,1)。
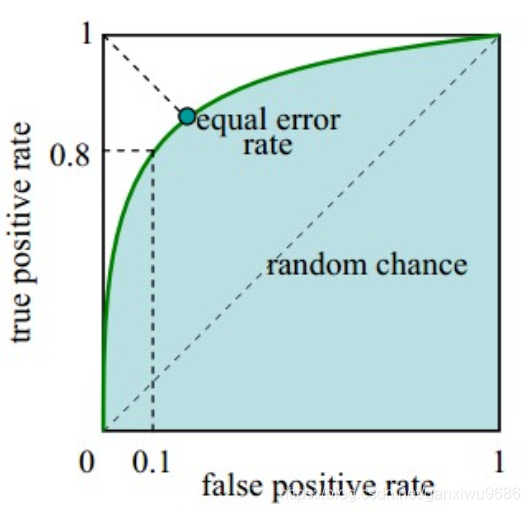
有了这个概念之后。我们可以看看python中怎么使用sklearn.metrics.roc_curve?
Parameters :
y_true : 数组,shape = [样本数]
在范围{0,1}或{-1,1}中真正的二进制标签。如果标签不是二进制的,则应该显式地给出pos_label
y_score : 数组, shape = [样本数]
目标得分,可以是积极类的概率估计,信心值,或者是决定的非阈值度量(在某些分类器上由“decision_function”返回)。
pos_label:int or str, 标签被认为是积极的,其他的被认为是消极的。
sample_weight: 顾名思义,样本的权重,可选择的
drop_intermediate: boolean, optional (default=True)
是否放弃一些不出现在绘制的ROC曲线上的次优阈值。这有助于创建更轻的ROC曲线
Returns :
fpr : array, shape = [>2] 增加假阳性率,例如,i是预测的假阳性率,得分>=临界值[i]
tpr : array, shape = [>2] 增加真阳性率,例如,i是预测的真阳性率,得分>=临界值[i]。
thresholds : array, shape = [n_thresholds]
减少了用于计算fpr和tpr的决策函数的阈值。阈值[0]表示没有被预测的实例,并且被任意设置为max(y_score) + 1
ROC曲线就由这两个值绘制而成。接下来进入sklearn.metrics.roc_curve:
import numpy as np
from sklearn import metrics
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
y 就是标准值,scores 是每个预测值对应的阳性概率,比如0.1就是指第一个数预测为阳性的概率为0.1,很显然,y 和 socres应该有相同多的元素,都等于样本数。pos_label=2 是指在y中标签为2的是标准阳性标签,其余值是阴性。
所以在标准值y中,阳性有2个,后两个;阴性有2个,前两个。
接下来选取一个阈值计算TPR/FPR,阈值的选取规则是在scores值中从大到小的以此选取,于是第一个选取的阈值是0.8
scores中大于阈值的就是预测为阳性,小于的预测为阴性。所以预测的值设为y_=(0,0,0,1),0代表预测为阴性,1代表预测为阳性。可以看出,真阴性都被预测为阴性,真阳性有一个预测为假阴性了。
FPR = FP / (FP+TN) = 0 / 0 + 2 = 0
TPR = TP/ (TP + FN) = 1 / 1 + 1 = 0.5
thresholds = 0.8
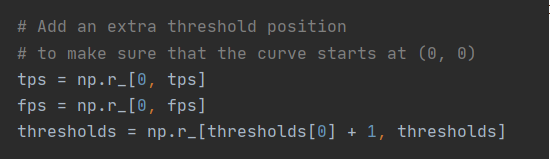
最后得到的结果是5列。第一列通过看源代码可以发现是什么。如上图所示。
那么为什么需要有这个东西呢?这就涉及到开集和闭集的概念了。具体可以见这个博客