本文是Hinton 大神在2014年NIPS上一篇论文《Distilling the Knowledge in a Neural Network》
1、Introduction
文章开篇用一个比喻来引入网络蒸馏:
昆虫作为幼虫时擅于从环境中汲取能量,但是成长为成虫后确是擅于其他方面,比如迁徙和繁殖等。
同理,神经网络训练阶段从大量数据中获取网络模型,训练阶段可以利用大量的计算资源且不需要实时响应。然而到达使用阶段,神经网络需要面临更加严格的要求包括计算资源限制,计算速度要求等等。
一个复杂的网络结构模型是若干个单独模型组成的集合,或者是一些很强的约束条件下(比如dropout率很高)训练得到的一个很大的网络模型。一旦复杂网络模型训练完成,我们便可以用另一种训练方法:“蒸馏”,把我们需要配置在应用端的缩小模型从复杂模型中提取出来。
通过soft target的形式,增加模型的泛化性能
2、soft target why?
标准的one hot信息熵太小,非常确定。使用大模型的soft target增加信息熵,信息量大,拥有不同类之间关系的信息,相当于增加了先验知识。
如果只有label这样的一个目标的话,那么这个模型的目标就是把训练样本中每一类的样本强制映射到同一个点上,这样其实对于训练很有帮助的类内variance和类间distance就损失掉了。
下图中,纵轴表示概率,横轴表示类别数,共10类。不同颜色表示下面公式中参数T不同,红色方差最大,蓝色方差最小(熵最大,最不确定,信息量页最大)。
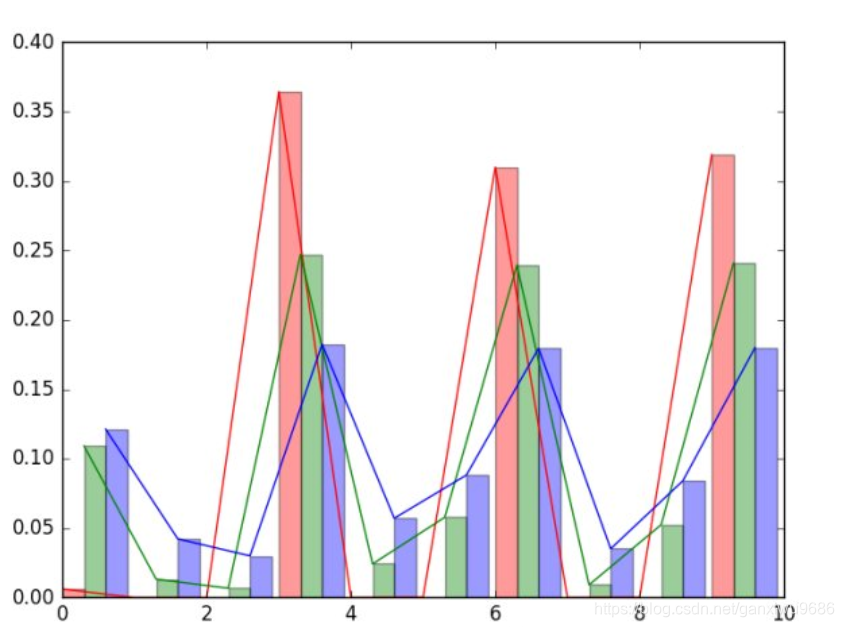
当“软目标的”熵值较高时,相对“硬目标”,它每次训练可以提供更多的信息和更小的梯度方差,因此小模型可以用更少的数据和更高的学习率进行训练。
3、How?怎么蒸馏?
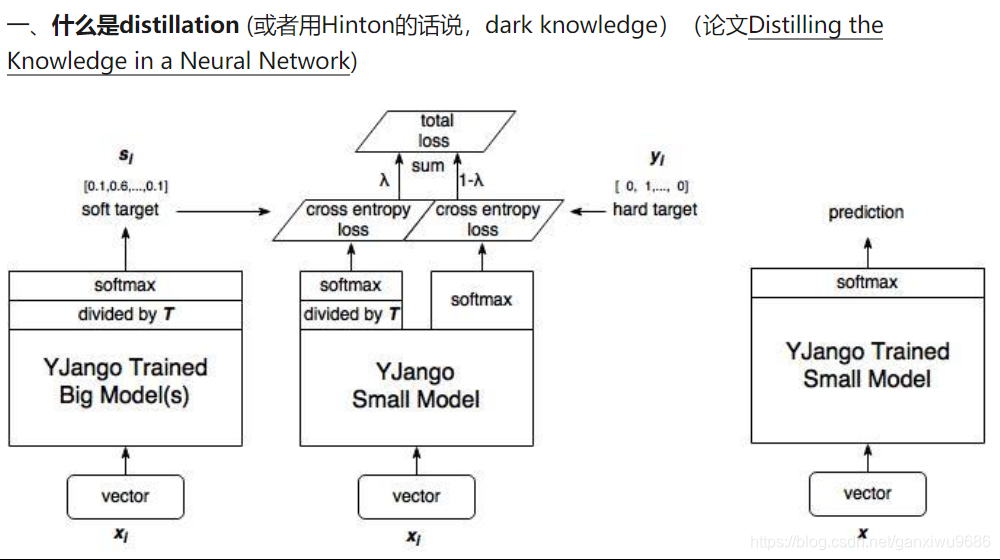
通过复杂网络产生的分类概率分布作为soft target来训练小模型。在transfer的过程中(即cumbersome network转向small network的时候)可以使用同样的训练集也可以使用单独的训练集。
但是,在mnist,对于正确的2来说,被分类为3的概率为10−610−6被分类为7的概率为10−910−9。在这种情况下soft target的帮助就很小(可以理解回归到了one hot),本文利用蒸馏解决这个问题(蒸馏会使得target变得更加soft)

这里T是超参数,文中说是‘温度’,经过该参数之后的softmax会更加平滑,分布更加均匀而大小关系不变,作为soft target时简易(student)网络能学到更多东西
“蒸馏”最简单的形式就是:以从复杂模型得到的“软目标”为目标(这时T比较大),用“转化”训练集训练小模型。训练小模型时T不变仍然较大,训练完之后T改为1。
4、总结
KD的核心思想在于"打散"原来压缩到了一个点的监督信息,让student模型的输出尽量match teacher模型的输出分布。小模型因为有了大模型帮忙提取出的标定空间的更多关联信息,所以能更好的进行学习。可以预见,小模型的performance并不会超过大模型,但是会比原来在离散标定空间上面训练的效果好。
KD本身还有很多局限,比如当类别少的时候效果就不太显著,对于非分类问题也不适用(或许现在衍生出了很多其他方法,有待继续调研)。
5、引申
以往研究忽略的一个重要瓶颈是输入的词汇量及其相应的词嵌入矩阵,通常占所有模型参数的很大比例。例如, BERT_Base模型的嵌入表,包括超过30K的单词标记,占模型大小的21%以上。虽然已有关于减少NLP模型词汇量大小的工作,但蒸馏技术无法利用这些,因为它们要求学生和教师模型共享相同的词汇量和输出空间。这严重限制了他们进一步缩小模型尺寸的潜力。
Google将BERT压缩到7MB,最新基于最优子词和共享投影的极限语言压缩模型,未完待续…