《R-Trans: RNN Transformer Network for Chinese Machine Reading Comprehension》阅读笔记
这篇文章是国防科大发表在2019年IEEE上的,是针对中文阅读理解数据集提出的自己的方法。在Les MMRC数据集上得到了SOTA效果。
分以下四部分介绍:
- Motivation
- Model
- Experiment
- Discussion
1、Motivation
- 大部分现存的模型都是用于处理英文的阅读理解,如果直接把他们迁移到中文的数据集上面,效果会大打折扣。另外还有一个不可避免的分词错误的问题。
- 为了去缩小分词错误的影响,并且挖掘整个句子的序列信息,使用deep contextualized word representations and bidirectional gated recurrent units networks
2、Model
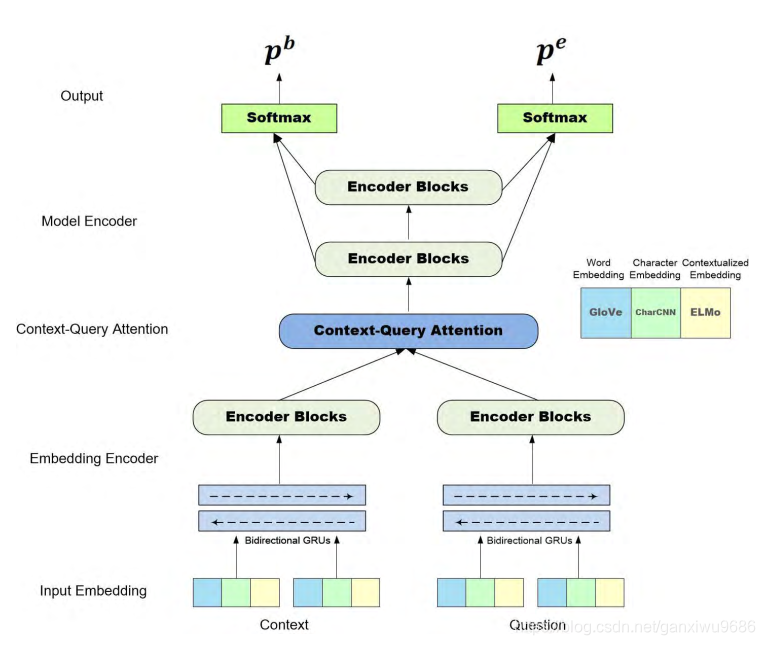
2.1 overview
中间结构主要分成三部分,一部分是embedding encoder, 第2部分是context query attention, 第3部分是model encoder
2.2 INPUT EMBEDDING LAYER
字符向量用CNN每一个词里面的字符都会去嵌入到一个64维向量,然后输入给CNN经过max pooling,得到最终的向量表示。词向量就用传统的与训练方法,得到一个300维度的向量。使用elmo获得词表示。文章说使用elmo,而不是bert,是因为词比字符有更丰富的语言信息。
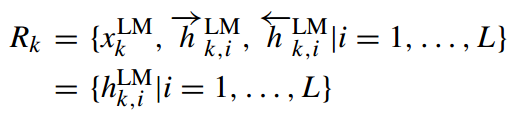
其中 x k L M x^{LM}_k xkLM 是independent of the context,是elmo的输入。 h h h 表示的是多个lstm的隐层向量,L层我们则得到2L+1个向量表示。
接下来通过一个线性结合把所有的输出层into a single vector,其中 w w w 和 gamma 是伴随着任务训练得到的参数。
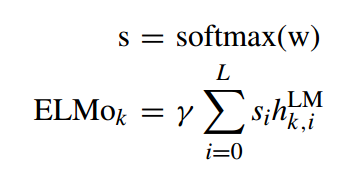
2.3 EMBEDDING ENCODER LAYER
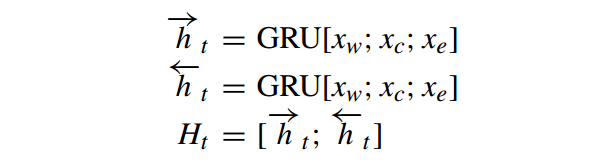
然后会通过残差块(一堆Encoder Block)减少梯度消失或爆炸。在Encoder Block中的Self attention之前增加了卷积层,文章说到它不是传统的卷积层,而是深度分离的depthwise separable ones (黑人问号)Encoder Block的数量为1,与后者的Encoder Block略有区别。
2.4 CONTEXT-QUERY ATTENTION LAYER
2.5 MODEL ENCODER LAYER
Compared to original QANet model, we reduce the number
of model encoder block to 2.
Besides, for each model encoder block, the number of the Encoder Block introduced above decreases from 7 to 3.
除此卷积的设置也有所不同。
2.6 OUTPUT LAYER

类似BI-DAF,直接用上一层的输出连接经过softmax
3、Experiment
这个数据仅有5万篇新闻的文章,每一篇文章大概有5个问题,即25万的问题,其中20万用来训练,5万用来测试

问题的类型比较多,其中大部分的能够用片段去进行回答,但是对于回答一些需要推理和总结类型的问题是一个挑战,如下图:

DATA PRE-PROCESSING
这篇文章有一个数据预处理的操作。随后将文章进行减枝。之前的论文好像很少用到这种方法。首先经过一些简单的预处理,比如说将一些特殊字符删掉,然后把中文的标点符号和数字用英文和阿拉伯数字替代。做完之后还有一个问题,就是文章太长了,导致参数量过大,训练起来比较困难。因此对文本进行如下的处理:
- 如果文章被切分,用问题和段落去计算,最长公共子串的相似性。然后从中选出k个段落,并且将这些段落按照降序的方式排列组成一个新的文章。因为每一个段落的第1句话都是比较重要的,所以将每一个段落的第1句话加到处理过的passage当中。
- 如果文章没有被切分的话,同样的使用上面的方法去计算问题和每一句话之间的最长公共子串的相似性,然后把最相似的t句话连接起来作为新的文章,此处不改变他们的顺序。
QUESTION:
- 对于第1种方法,那如果文章是有篇章结构的话,他把篇章结构的顺序去打乱了,会不会有什么影响?
- 把每段的第1句话加入到passage当中。那之前段落当中的第1句话还保留吗?而且所有段落的第1句话拼在一起,是不是有一点奇怪
- 还有一个操作是在对答案进行标注之后,对于那些没有标注的内容进行prune。如果结束位置没有超过limit L,可以把结束位置之后的所有部分prune。否则,可以从文章的title到开始标志的这一部分内容随机的prune然后再remove the text after the end label which is out of range。那都剩下了什么??

4、Discussion
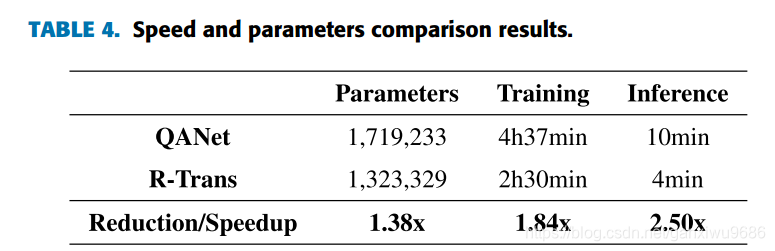
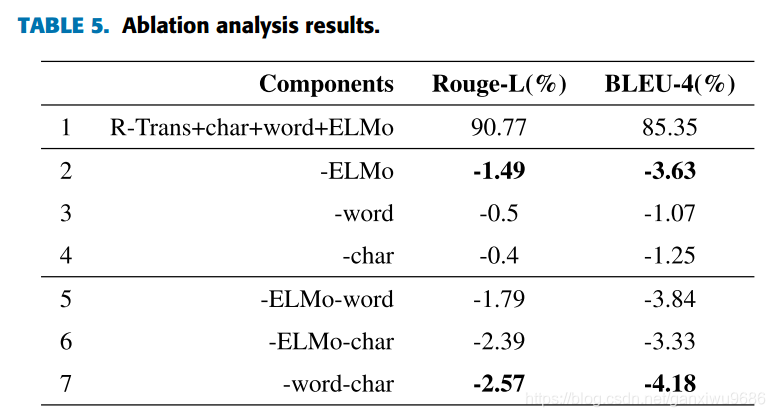
从消融实践中可以看出,如果只使用elmo向量效果会大打折扣,但是如果不使用它的话,效果也会大打折扣,所以需要把这三者向量结合使用。
但是这篇文章只是使用了一个外部的词向量表示然后模型结构稍微改了改,就能够中,也是比较神奇。
QUESTION
1.文章说到它不是传统的卷积层,而是深度分离的depthwise separable ones
可以参看:https://blog.csdn.net/gwplovekimi/article/details/89890510
2.DATA PRE-PROCESSING中提到的问题。
欢迎解答!