
前言
在讨论函数式编程(Functional Programming)的具体内容之前,我们首先看一下函数式编程的含义。在维基百科上,函数式编程的定义如下:"函数式编程是一种编程范式。它把计算当成是数学函数的求值,从而避免改变状态和使用可变数据。它是一种声明式的编程范式,通过表达式和声明而不是语句来编程。" (见 Functional Programming)
函数式编程的思想在软件开发领域由来已久。在众多的编程范式中,函数式编程虽然出现的时间很长,但是在编程范式领域和整个开发社区中的流行度一直不温不火。函数式编程有一部分狂热的支持者,在他们眼中,函数式编程思想是解决各种软件开发问题的终极方案;而另外的一部分人,则觉得函数式编程的思想并不容易理解,学习曲线较陡,上手起来也有一定的难度。大多数人更倾向于接受面向对象或是面向过程这样的编程范式。这也是造成函数式编程范式一直停留在小众阶段的原因。
这样两极化的反应,与函数式编程本身的特性是分不开的。函数式编程的思想脱胎于数学理论,也就是我们通常所说的λ演算( λ-calculus)。一听到数学理论,可能很多人就感觉头都大了。这的确是造成函数式编程的学习曲线较陡的一个原因。如同数学中的函数一样,函数式编程范式中的函数有独特的特性,也就是通常说的无状态或引用透明性(referential transparency)。一个函数的输出由且仅由其输入决定,同样的输入永远会产生同样的输出。这使得函数式编程在处理很多与状态相关的问题时,有着天然的优势。函数式编程的代码通常更加简洁,但是不一定易懂。函数式编程的解决方案中透露出优雅的美。
函数式编程所涵盖的内容非常广泛,从其背后的数学理论,到其中包含的基本概念,再到诸如 Haskell 这样的函数式编程语言,以及主流编程语言中对函数式编程方式的支持,相关的专有第三方库等。通过本系列的学习,你可以了解到很多函数式编程相关的概念。你会发现很多概念都可以在日常的开发中找到相应的映射。比如做前端的开发人员一定听说过高阶组件(high-order component),它就与函数式编程中的高阶函数有着异曲同工之妙。流行的前端状态管理方案 Redux 的核心是 reduce 函数。库 reselect 则是记忆化( memoization)的精妙应用。很多 Java 开发人员已经切实的体会到了 Java 8 中的 Lambda 表达式如何让对流(Stream)的操作变得简洁又自然。
近年来,随着多核平台和并发计算的发展,函数式编程的无状态特性,在处理这些问题时有着其他编程范式不可比拟的天然优势。不管是前端还是后端开发人员,学习一些函数式编程的思想和概念,对于手头的开发工作和以后的职业发展,都是大有裨益的。本系列虽然侧重的是 Java 平台上的函数式编程,但是对于其他背景的开发人员同样有借鉴意义。
下面介绍函数的基本概念。
函数
我们先从数学中的函数开始谈起。数学中的函数是输入元素的集合到可能的输出元素的集合之间的映射关系,并且每个输入元素只能映射到一个输出元素。比如典型的函数 f(x)=x*x 把所有实数的集合映射到其平方值的集合,如 f(2)=4 和 f(-2)=4。函数允许不同的输入元素映射到同一个输出元素,但是每个输入元素只能映射到一个输出元素。比如上述函数 f(x)=x*x 中,2 和-2 都映射到同一个输出元素 4。这也限定了每个输入元素所对应的输出元素是固定的。每个输入元素都必须被映射到某个输出元素,也就是说函数可以应用到输入元素集合中的每个元素。
用专业的术语来说,输入元素称为函数的参数(argument)。输出元素称为函数的值(value)。输入元素的集合称为函数的定义域(domain)。输出元素和其他附加元素的集合称为函数的到达域(codomain)。存在映射关系的输入和输出元素对的集合,称为函数的图形(graph)。输出元素的集合称为像(image)。这里需要注意像和到达域的区别。到达域还可能包含除了像中元素之外的其他元素,也就是没有输入元素与之对应的元素。
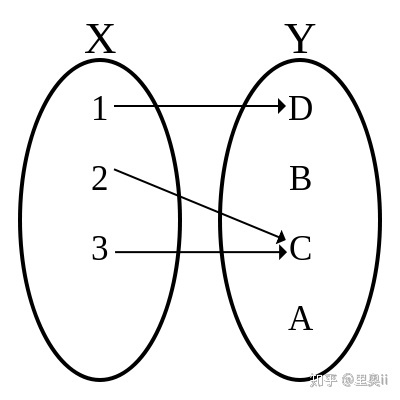
图 1 表示了一个函数对应的映射关系(图片来源于维基百科上的 Function 条目)。输入集合 X 中的每个元素都映射到了输出集合 Y 中某个元素,即 f(1)=D、f(2)=C 和 f(3)=C。X 中的元素 2 和 3 都映射到了 Y 中的 C,这是合法的。Y 中的元素 B 和 A 没有被映射到,这也是合法的。该函数的定义域是 X,到达域是 Y,图形是 (1, D)、(2, C) 和 (3, C) 的集合,像是 C 和 D 的集合。
图 1. 函数的映射关系
我们通常可以把函数看成是一个黑盒子,对其内部的实现一无所知。只需要清楚其映射关系,就可以正确的使用它。函数的图形是描述函数的一种方式,也就是列出来函数对应的映射中所有可能的元素对。这种描述方式用到了集合相关的理论,对于图 1 中这样的简单函数比较容易进行描述。对于包含输入变量的函数,如 f(x)=x+1,需要用到更加复杂的集合逻辑。因为输入元素 x 可以是任何数,定义域是一个无穷集合,对应的输出元素集合也是无穷的。要描述这样的函数,用我们下面介绍的 λ 演算会更加直观。
λ 演算
λ 演算是数理逻辑中的一个形式系统,在函数抽象和应用的基础上,使用变量绑定和替换来表达计算。讨论 λ 演算离不开形式化的表达。在本文中,我们尽量集中在与编程相关的基本概念上,而不拘泥于数学上的形式化表示。λ 演算实际上是对前面提到的函数概念的简化,方便以系统的方式来研究函数。λ 演算的函数有两个重要特征:
- λ 演算中的函数都是匿名的,没有显式的名称。比如函数 sum(x, y) = x + y 可以写成 (x, y)|-> x + y。由于函数本身仅由其映射关系来确定,函数名称实际上并没有意义。因此使用匿名函数是合理的。
- λ演算中的函数都只有一个输入。有多个输入的函数可以转换成多个只包含一个输入的函数的嵌套调用。这个过程就是通常所说的柯里化(currying)。如 (x, y)|-> x + y 可以转换成 x |-> (y |-> x + y)。右边的函数的返回值是另外一个函数。这一限定简化了λ演算的定义。
对函数简化之后,就可以开始定义 λ 演算。λ 演算是基于 λ 项(λ-term)的语言。λ 项是 λ 演算的基本单元。λ 演算在 λ 项上定义了各种转换规则。
λ项
λ 项由下面 3 个规则来定义:
- 一个变量 x 本身就是一个 λ 项。
- 如果 M 是 λ 项,x 是一个变量,那么 (λx.M) 也是一个 λ 项。这样的 λ 项称为 λ 抽象(abstraction)。x 和 M 中间的点(.)用来分隔函数参数和内容。
- 如果 M 和 N 都是 λ 项,那么 (MN) 也是一个 λ 项。这样的λ项称为应用(application)。
所有的合法 λ 项,都只能通过重复应用上面的 3 个规则得来。需要注意的是,λ 项最外围的括号是可以省略的,也就是可以直接写为 λx.M 和 MN。当多个 λ 项连接在一起时,需要用括号来进行分隔,以确定 λ 项的解析顺序。默认的顺序是左向关联的。所以 MNO 相当于 ((MN)O)。在不出现歧义的情况下,可以省略括号。
重复应用上述 3 个规则就可以得到所有的λ项。把变量作为λ项是重复应用规则的起点。λ 项 λx.M 定义的是匿名函数,把输入变量 x 的值替换到表达式 M 中。比如,λx.x+1 就是函数 f(x)=x+1 的 λ 抽象,其中 x 是变量,M 是 x+1。λ 项 MN 表示的是把表达式 N 应用到函数 M 上,也就是调用函数。N 可以是类似 x 这样的简单变量,也可以是 λ 抽象表示的项。当使用λ抽象时,就是我们通常所说的高阶函数的概念。
绑定变量和自由变量
在 λ 抽象中,如果变量 x 出现在表达式中,那么该变量被绑定。表达式中绑定变量之外的其他变量称为自由变量。我们可以用函数的方式来分别定义绑定变量(bound variable,BV)和自由变量(free variable,FV)。
对绑定变量来说:
- 对变量 x 来说,BV(x) = ∅。也就是说,一个单独的变量是自由的。
- 对 λ 项 M 和变量 x 来说,BV(λx.M) = BV(M) ∪ { x }。也就是说,λ 抽象在 M 中已有的绑定变量的基础上,额外绑定了变量 x。
- 对 λ 项 M 和λ项 N 来说,BV(MN) = BV(M) ∪ BV(N)。也就是说,λ 项的应用结果中的绑定变量的集合是各自 λ 项的绑定变量集合的并集。
对自由变量来说,相应的定义和绑定变量是相反的:
- 对变量 x 来说,FV(x) = { x }。
- 对 λ M 和变量 x 来说,FV(λx.M) = FV(M) − { x }。
- 对 λ 项 M 和 λ 项 N 来说,FV(MN) = FV(M) ∪ FV(N)。
在 λ 项 λx.x+1 中,x 是绑定变量,没有自由变量。在 λ 项 λx.x+y 中,x 是绑定变量,y 是自由变量。
在λ抽象中,绑定变量的名称在某些情况下是无关紧要的。如 λx.x+1 和 λy.y+1 实际上表示的是同样的函数,都是把输入值加 1。变量名称 x 或 y,并不影响函数的语义。类似 λx.x+1 和 λy.y+1 这样的 λ 项在λ演算中被认为是相等的,称为 α 等价(alpha equivalence)。
约简
在 λ 项上可以进行不同的约简(reduction)操作,主要有如下 3 种。
α 变换
α 变换(α-conversion)的目的是改变绑定变量的名称,避免名称冲突。比如,我们可以通过 α 变换把 λx.x+1 转换成 λy.y+1。如果两个λ项可以通过α变换来进行转换,则这两个 λ 项是 α 等价的。这也是我们上一节中提到的 α 等价的形式化定义。
对 λ 抽象进行 α 变换时,只能替换那些绑定到当前 λ 抽象上的变量。如 λ 抽象 λx.λx.x 可以 α 变换为 λx.λy.y 或 λy.λx.x,但是不能变换为 λy.λx.y,因为两者的语义是不同的。λx.x 表示的是恒等函数。λx.λx.x 和 λy.λx.x 都是表示返回恒等函数的 λ 抽象,因此它们是 α 等价的。而 λx.y 表示的不再是恒等函数,因此 λy.λx.y 与 λx.λy.y 和 λy.λx.x 都不是 α 等价的。
β 约简
β 约简(β-reduction)与函数应用相关。在讨论 β 约简之前,需要先介绍替换的概念。对于 λ 项 M 来说,M[x := N] 表示把 λ 项 M 中变量 x 的自由出现替换成 N。具体的替换规则如下所示。A、B 和 M 是 λ 项,而 x 和 y 是变量。A ≡ B 表示两个 λ 项是相等的。
- x[x := M] ≡ M:直接替换一个变量 x 的结果是用来进行替换的 λ 项 M。
- y[x := M] ≡ y(x ≠ y):y 是与 x 不同的变量,因此替换 x 并不会影响 y,替换结果仍然为 y。
- (AB)[x := M] ≡ (A[x := M]B[x := M]):A 和 B 都是 λ 项,(AB) 是 λ 项的应用。对 λ 项的应用进行替换,相当于替换之后再进行应用。
- (λx.A)[x := M] ≡ λx.A:这条规则针对 λ 抽象。如果 x 是 λ 抽象的绑定变量,那么不需要对 x 进行替换,得到的结果与之前的 λ 抽象相同。这是因为替换只是针对 M 中 x 的自由出现,如果 x 在 M 中是不自由的,那么替换就不需要进行。
- (λy.A)[x := M] ≡ λy.A[x := M](x ≠ y 并且 y ∉ FV(M)):这条规则也是针对λ抽象。λ 项 A 的绑定变量是 y,不同于要替换的 x,因此可以在 A 中进行替换动作。
在进行替换之前,可能需要先使用 α 变换来改变绑定变量的名称。比如,在进行替换 (λx.y)[y := x] 时,不能直接把出现的 y 替换成 x。这样就改变了之前的 λ 抽象的语义。正确的做法是先进行 α 变换,把 λx.y 替换成 λz.y,再进行替换,得到的结果是 λz.x。
替换的基本原则是要求在替换完成之后,原来的自由变量仍然是自由的。如果替换变量可能导致一个变量从自由变成绑定,需要首先进行 α 变换。在之前的例子中,λx.y 中的 x 是自由变量,而直接替换的结果 λx.x 把 x 变成了绑定变量,因此 α 变换是必须的。在正确的替换结果 λz.x 中,z 仍然是自由的。
β 约简用替换来表示函数应用。对 ((λV.E) E′) 进行 β 约简的结果就是 E[V := E′]。如 ((λx.x+1)y) 进行 β 约简的结果是 (x+1)[x := y],也就是 y+1。
η 变换
η 变换(η-conversion)描述函数的外延性(extensionality)。外延性指的是如果两个函数当且仅当对所有参数的结果相同时,才被认为是相等的。比如一个函数 F,当参数为 x 时,它的返回值是 Fx。那么考虑声明为 λy.Fy 的函数 G。函数 G 对于输入参数 x,同样返回结果 Fx。F 和 G 可能由不同的 λ 项组成,但是只要 Fx=Gx 对所有的 x 都成立,那么 F 和 G 是相等的。
以 F=λx.x 和 G=λx.(λy.y)x 来说,F 是恒等函数,而 G 则是在输入参数 x 上应用恒等函数。F 和 G 虽然由不同的 λ 项组成,但是它们的行为是一样,本质上都是恒等函数。我们称之为 F 和 G 是 η 等价的,F 是 G 的 η 约简,而 G 是 F 的 η 扩展。F 和 G 互为对方的 η 变换。
纯函数、副作用和引用透明性
了解函数式编程的人可能听说过纯函数和副作用等名称。这两个概念与引用透明性紧密相关。纯函数需要具备两个特征:
- 对于相同的输入参数,总是返回相同的值。
- 求值过程中不产生副作用,也就是不会对运行环境产生影响。
对于第一个特征,如果是从数学概念上抽象出来的函数,则很容易理解。比如 f(x)=x+1 和 g(x)=x*x 这样的函数,都是典型的纯函数。如果考虑到一般编程语言中出现的方法,则函数中不能使用静态局部变量、非局部变量,可变对象的引用或 I/O 流。这是因为这些变量的值可能在不同的函数执行中发生变化,导致产生不一样的输出。第二个特征,要求函数体中不能对静态局部变量、非局部变量,可变对象的引用或 I/O 流进行修改。这就保证了函数的执行过程中不会对外部环境造成影响。纯函数的这两个特征缺一不可。下面通过几个 Java 方法来具体说明纯函数。
在清单 1 中,方法 f1 是纯函数;方法 f2 不是纯函数,因为引用了外部变量 y;方法 f3 不是纯函数,因为使用了调用了产生副作用的 Counter 对象的 inc 方法;方法 f4 不是纯函数,因为调用 writeFile 方法会写入文件,从而对外部环境造成影响。
清单 1. 纯函数和非纯函数示例
int f1(int x) {
return x + 1;}
int f2(int x) {
return x + y;}
int f3(Counter c) {
c.inc();
return 0;}
int f4(int x) {
writeFile();
return 1;}
如果一个表达式是纯的,那么它在代码中的所有出现,都可以用它的值来代替。对于一个函数调用来说,这就意味着,对于同一个函数的输入参数相同的调用,都可以用其值来代替。这就是函数的引用透明性。引用透明性的重要性在于使得编译器可以用各种措施来对代码进行自动优化。
函数式编程与并发编程
随着计算机硬件多核的普及,为了尽可能地利用硬件平台的能力,并发编程显得尤为重要。与传统的命令式编程范式相比,函数式编程范式由于其天然的无状态特性,在并发编程中有着独特的优势。以 Java 平台来说,相信很多开发人员都对 Java 的多线程和并发编程有所了解。可能最直观的感受是,Java 平台的多线程和并发编程并不容易掌握。这主要是因为其中所涉及的概念太多,从 Java 内存模型,到底层原语 synchronized 和 wait/notify,再到 java.util.concurrent 包中的高级同步对象。由于并发编程的复杂性,即使是经验丰富的开发人员,也很难保证多线程代码不出现错误。很多错误只在运行时的特定情况下出现,很难排错和修复。在学习如何更好的进行并发编程的同时,我们可以从另外一个角度来看待这个问题。多线程编程的问题根源在于对共享变量的并发访问。如果这样的访问并不需要存在,那么自然就不存在多线程相关的问题。在函数式编程范式中,函数中并不存在可变的状态,也就不需要对它们的访问进行控制。这就从根本上避免了多线程的问题。
总结
作为 Java 函数式编程系列的第一篇文章,本文对函数式编程做了简要的概述。由于函数式编程与数学中的函数密不可分,本文首先介绍了函数的基本概念。接着对作为函数式编程理论基础的λ演算进行了详细的介绍,包括λ项、自由变量和绑定变量、α变换、β约简和η变换等重要概念。最后介绍了编程中可能会遇到的纯函数、副作用和引用透明性等概念。本系列的下一篇文章将对函数式编程中的重要概念进行介绍,包括高阶函数、闭包、递归、记忆化和柯里化等。
参考资源
原作者:成 富
原文链接: 函数式编程思想概论
原出处:IBM Developer
