在服务设计中,经常遇到的一个问题就是如何生成一个全局唯一的ID,例如订单号,流水号等。对于ID的要求主要有以下几点:
全局唯一,不会存在冲突;
快速生成,能够满足高并发场景下的需求;
能够满足分布式场景下的业务需求;
ID生成服务能够方便的扩容缩容。
最好基本有序;
能够附加一些业务信息,例如时间,系统标识等;
能够应对测试环境的一些特殊需求,如跳日,日期回拨等。
我们简单分析下常见的实现方式:
UUID
最熟悉的应该是UUID,UUID 是 通用唯一识别码(Universally Unique Identifier)的缩写。按照UUID规范,UUID的实现方式一共有四种:
基于时间戳的UUID。这个UUID是基于时间戳,随机数和当前机器mac地址计算得到的,可以保证全球范围内的唯一性。但是,使用mac地址为带来安全问题。
DCE(Distributed Computing Environment)安全的UUID和基于时间的UUID算法相同,但会把时间戳的前4位置换为POSIX的UID或GID。
基于名字的UUID(MD5),通过计算名字和名字空间的MD5散列值得到。这个版本的UUID保证了:相同名字空间中不同名字生成的UUID的唯一性;不同名字空间中的UUID的唯一性;相同名字空间中相同名字的UUID重复生成是相同的。
根据随机数,或者伪随机数生成UUID。这个是存在重复概率的,虽然概率很小,但是还是存在的。
基于名字的UUID(SHA1),这个与第三种类似。
以java为例,常用的java.util.UUID这个类支持第三、四两种UUID的生成方法:
如源码所示,分别是随机UUID和基于名字的UUID。
UUID是优点在于使用相对简单,每个服务自己生成。
缺点我认为主要有几个:
生成的ID是随机的,不能从字面上看出一些附加信息。
索引效率比较低;
不满足基本有序;
存储占用空间大,这个在目前看来不是主要问题。
数据库自增主键
数据库提供了一种自增主键的方式来生成ID,这种方式的主要优点是生成简单,ID是严格有序的。
方式比较简单,这里不再赘述。
可能存在问题的地方我认为主要有几点:
在分库分表场景下不太合适。第一个问题是存在多库的场景下可能存在ID冲突的问题,虽然可以通过设定步长解决,但是不利于数据库扩展;
数据库自增ID存在一个上限,mysql默认的应该是Int,默认长度是32位。大概是几十亿,这个上限应该很容易达到。
数据库压力大。每次生成ID都需要读写数据库,数据库压力较大,容易成为瓶颈。
基于redis实现
Redis 的 INCR 命令支持 “INCR AND GET” 原子操作。利用这个特性,我们可以在 Redis 中存序列号,让分布式环境中多个取号服务在 Redis 中通过 INCR 命令来实现取号;同时 Redis 是单进程单线程架构,不会因为多个取号方的 INCR 命令导致取号重复。因此,基于 Redis 的 INCR 命令实现序列号的生成基本能满足全局唯一与单调递增的特性,并且性能还不错。
但是不足的地方是不能够附加一些业务信息,例如时间,业务系统信息等。
基于ZOOKEEPER实现
下图是一个经典的基于zk实现的ID生成器的解决方案,参考了网友的实现:
这个方案的缺点也很明显,无法附加业务信息,且只能产生32位的ID。
SnowFlake
SnowFlake是Twitter开源的一个全局ID生成算法,长度为64位,在java中刚好是一个long型。
SnowFlake中各个bit位的含义如下图(图片来自于网络)所示:

主要分为四段:
第一位是0,暂时未使用;
接下来是41位,表示与1970-01-01 00:00:00:000的毫秒时间数差,也可以指定时间,够用69年;
接下来10位表示集群ID和机器实例ID,最大支持1024个实例;
最后12位表示同一毫秒内的序列号,最多支持4096个,也就是说每毫米最多生成4096个全局ID。
这里提供了一种思路,具体的实现我们可以参考,也可以根据需求去改进自己的实现,例如每段含义可以自己修改或扩充。
这种方案有个缺点:在做业务测试的时候经常会出现跳日和时钟回拨的情况,这种情况下,生成的ID是会发生冲突的。建议解决方案时冲突时直接抛出异常,重新生成。
美团的Leaf
这个是美团开源的全局ID生成器,取自于这个世界上没有两片完全相同的叶子。主要有以下几个特点:
全局唯一,绝对不会出现重复的ID,且ID整体趋势递增。
高可用,服务完全基于分布式架构,即使MySQL宕机,也能容忍一段时间的数据库不可用。
高并发低延时。
接入简单。
这个算法在美团内部已经迭代了很多版本,这里简单介绍下第一个版本的简单实现,具体深入的研究可以参考github上开源的代码。
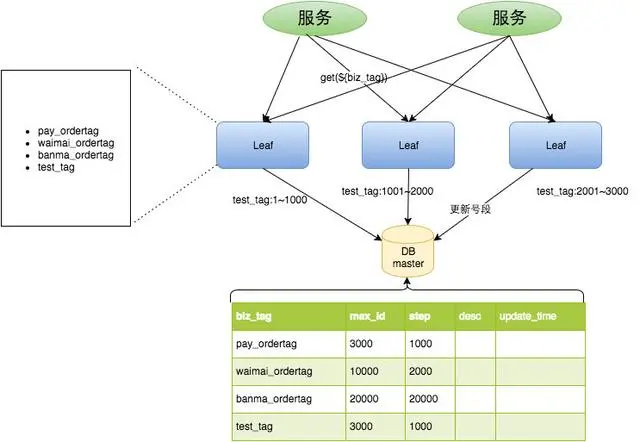
Leaf是基于分布式架构的,即一个数据库上挂了N个server,ID的生成采用预发的方式,每次server启动时会去数据库拿一批固定长度的ID,然后把最大的ID持久化在数据库中,也就是说并不是每个ID都需要持久化,可以减轻数据库压力。
同时Leaf除了上述的号段模式之外还支持SnowFlake模式,可以根据自己需要选择。
总结
其实没有所谓的最优的解决方案,在日常的使用中我们需要根据自己的具体业务场景选择合适的ID生成方式,如果业务比较简单,完全可以采用UUID或者是mysql自增主键的方式,如果业务场景复杂,则需要根据业务场景的特点作出权衡。