前言
LinkedHashMap 是 HashMap 的子类,其继承了HashMap的方法,同时扩展了自己的能力。因此本章只分析LinkedHashMap的扩展部分,至于HashMap相关部分,请参考下方入口:
第十章 Java的集合之从设计思想分析HashMap源码
本章基于JDK 1.8版本。
基于HashMap的扩展能力
LinkedHashMap从其名字上可知,它与链表结构有着一定的联系。了解过HashMap的人知道,HashMap 是一种无序的存储结构,无法保证内部元素的先后顺序。因此LInkedHashMap的首要功能就是提供有序的结构。其已知的数据结构中,链表是最好的实现之一。
有序
LinkedHashMap 内部和HashMap一样维持着结点Entry,Entry是HashMap中Node的子类,继承了Node的方法和行为,Entry与Node的不同之处在于其内部多了两个变量 before 和 after:
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
before 和 after 的诞生,意味着每一个LinkedHashMap的Entry结点加入集合,内部还是维护着hash算法,内部还是维护这数组,数组上还是维护这链表和红黑树,但是现在的结点Entry可以与上一个结点相连,也可以与下一个结点相连了。
hashMap
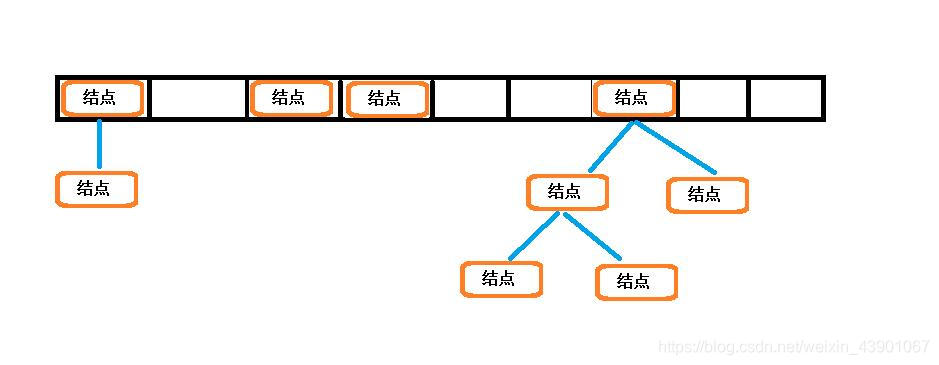
linkedHashMap
大意就是在HashMap的基础上增加了链表结构,并且内部维持着链表头结点和尾结点的指针。
transient LinkedHashMap.Entry<K,V> head;
transient LinkedHashMap.Entry<K,V> tail;
链表设计让LinkedHashMap有了顺序,但是特别说明的是,LInkedHashMap有两个顺序存在,一是插入顺序,二是访问顺序。选择采用哪种排序的机制是维持着一个变量:
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder;
如果是true,代表访问排序。如果是false,代表插入排序。
一般在linkedHashMap在构造器中初始化时,默认都是插入排序的LinkedHashMap对象。
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
插入排序
对于插入排序的linkedHashMap,每新增一个结点,都会通过linkNodeLast 链接前后前后结点,形成插入顺序。
linkNodeLast方法
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
访问排序
对于插入排序,通过上述的链表就应该明白。插入的先后顺序通过该双向链表来维护。那么访问排序是什么呢?在访问linkedHashMap时,通过get方法获取元素。
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
从get方法可知,通过accessOrder 可以控制是否执行afterNodeAccess(e)方法。afterNodeAccess方法做了什么呢?
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// 如果get方法访问的结点不是最后一个结点,则有可能是头结点和中间结点,则进行如下操作
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
// 下面操作意思就是,将这个e结点从链表中解开,单独剔出来。
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
// 将e结点放在链表最后
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
综上大概意思就是,通过get过后的元素结点,都会被放在插入顺序的链表末尾。但是在内部的数组结构上不会变。
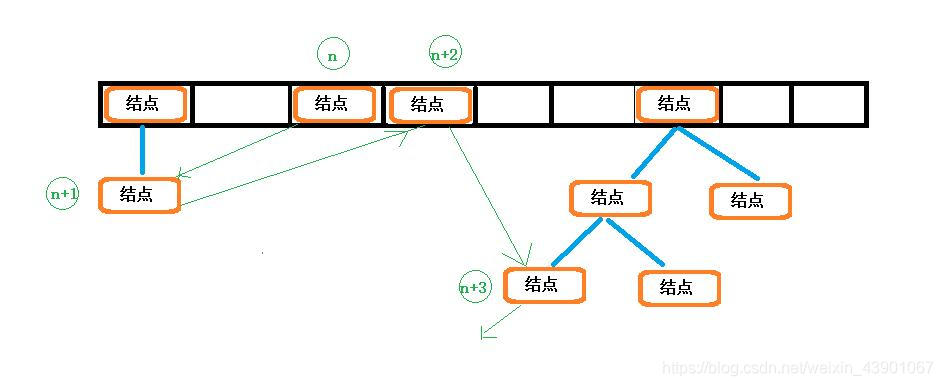
假如下图是一个访问排序的LInkedHashMap对象,当前的访问排序。
访问前
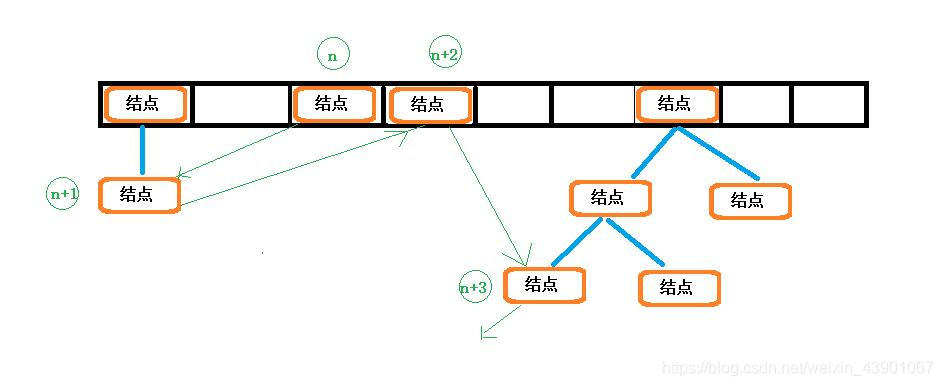
现在访问了n+1 的结点。
使用 get((n+1)),不代表具体的值。
访问后
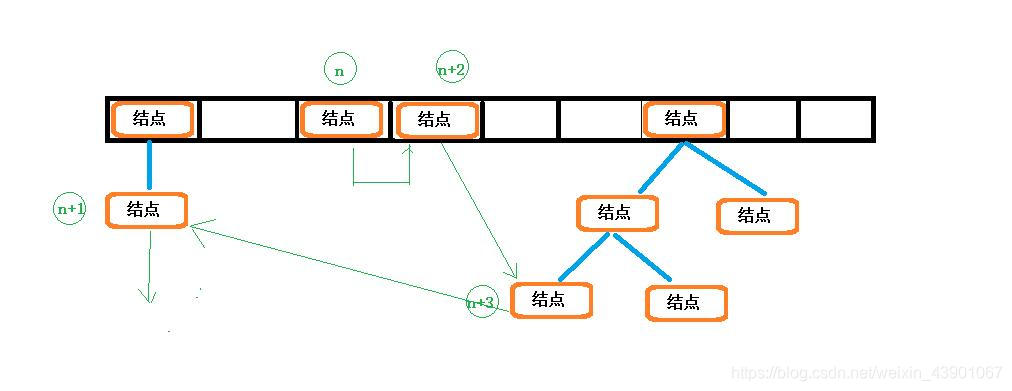
可以看到,元素在内部的位置并没有发生变化,而是维护的链表顺序发生了变化。
总结
对于插入排序和访问排序做以下几点总结:
1. 插入排序和访问排序通过accessOrder变量来控制
2. 默认采用插入排序。
3. 当采用访问排序时,插入排序依然存在。