Quartz 有四个核心接口 Job、JobDetail、Trigger 和 Scheduler[15]。Quartz 的运行原理如图 所示。Scheduler 是整个任务调度的总部,里面注册了很多的 JobDetail 和
Trigger。Trigger 主要有表达式触发和简单触发两个接口,表达式触发的功能更强大,在开发时使用比较广泛,用来设置多久进行一次任务调度。当 Scheduler 容器启动时,JobDetail 和 Trigger 会在 Scheduler 容器上进行注册。注册后,JobDetail 和Trigger 将会组成的一对装配好的作业。在 Scheduler 中有一个线程池,按照 Trigger 中配置的规则,为每个作业开启一个线程来并行执行。

图 Quartz 运行原理图
消息中间件 RabbitMQ 和搜索服务器 Solr
RabbitMQ 是一款开源的消息框架,在网易、爱奇艺等大型互联网公司被广泛的运用。在 RabbitMQ 中主要含有 Producer(消息生产者)、Exchange(交换机)、Queue
(消息队列)、Consumer(消息消费者)几个角色,其运行原理如图 。
图 RabbitMQ 运行原理图
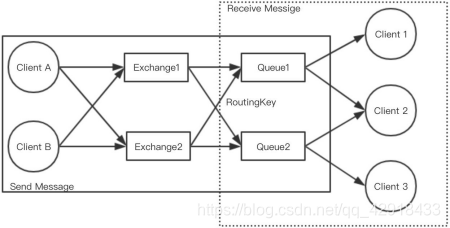
Client A 和Client B 都是消息生产者,其生产的消息并不是直接传递给消息队列, 而是先经过交换机(Exchange),在 RabbitMQ 中有一个很重要的概念就是绑定
(Binding),其作用是将交换机和队列按照一定的规则进行绑定,然后,交换机就知道将消息投递到哪个或哪几个队列里面。最后,消费者订阅队列中的消息,按照先进先出的规则进行消费。相比如 Kafka 等其他的消息中间件,RabbitMQ 在易用性,稳定性等方面有明显的优势,扩展集群时可以十分轻松的删除或者增加集群节点。RabbitMQ 还有强大的可视化 Web 管理界面,对开发者非常友好。
Solr 是 Apache 公司开发的全文搜索服务器,在 Lucene 的基础上对其进行了优化,将整个索引操作功能封装了起来。相比以前的搜索框架,Solr 提供的查询语言更加丰富,并对搜索性能和索引进行了很大的优化[21]。Solr 不仅可以将用户提交的搜索关键字进行智能分解,还能过滤掉 “也”、“的”等语气停顿词。
除此之外,Solr 还为用户提供了可视化操作的界面,开发者可以方便的通过可视化界面查看 Solr 的配置和运行情况。Solr 索引的实现是通过将描述的 Field 及其内容加进一个 XML 文档,然后用 POST 方法将文档提交到 Solr 服务器。Solr 服务器再根据提交的 XML 文档中的内容更新索引。此时搜索的索引已经建立,可以通过Solr 服务器搜索到。最后根据需要组建搜索关键词,调用方向 Solr 服务器发送 GET 请求,Solr 服务器将搜索到的结果以 XML 或者 JSON 等格式返回,调用方拿到返回的 XML 或者 JSON 数据将其解析。