Service(svc)
通过标签选择的方式匹配一组Pod对外访问服务的一种机制,每一个svc可以理解为一个微服务。微服务对这一组Pod进行轮循访问
工作原理:
| 1 |
k8s在创建service时候,会根据标签选择器selector(Lable selector)来查找pod,据此创建与service同名的endpoint对象,当pod地址发生变化时,endpoint也会随之发生变化,service接收到前端client请求的时候,就会通过endpoint,找到要转发到哪个Pod进行访问网站的地址。(至于要转发到哪个节点的Pod,由负载均衡kube-proxy起初就决定好了的) |
endpoint解释
| 1 2 3 |
1.endpoint是k8s集群中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod的访问地址。 2.只有当service配置selector(选择器) ,endpoint controller才会自动创建对应的endpoint对象,否则,不会生成endpoint对象。 3.例:k8s集群中创建一个名为hello的service,就会生成一个同名的endpoint对象,endpoint就是service关联的pod的ip地址和端口。 |
userspace模式工作原理图(按个人理解画的)
此图为node1服务器节点
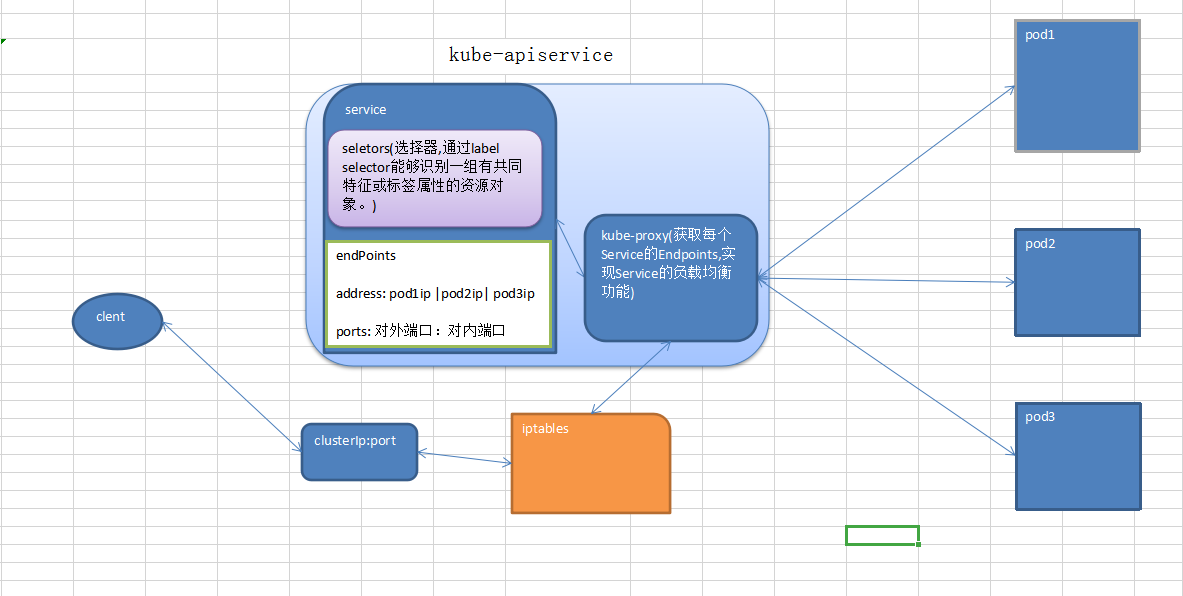
clusterIP 主要在每个 node 节点使用 iptables,将发向 clusterIP :port的数据,转发到 kube-proxy 中。然后 kube-proxy 自己内部实现有负载均衡的方法,并查询到这个 service 下的 endPoints,找到对应的 pod 的地址和对应端口,进而把
数据转发给对应的 pod 的地址和端口
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
访问Service的请求,不论是Cluster IP + TargetPort的方式;还是用Node节点的IP+NodePort的方式,都被Node节点的Iptables规则重定向到Kube-proxy监听Service服务代理端口。 kube-proxy接收到Service的访问请求后,根据负载策略,转发到后端的Pod。 1.Service在很多情况下只是一个概念,而真正将Service的作用实现的是kube-proxy服务进程。 2.每个Node节点上都会运行一个kube-proxy服务进程。 3.对每一个TCP类型的Kubernetes Service,kube-proxy都会在本地Node节点上建立一个SocketServer来负责接收请求,然后均匀发送到后端某个Pod的端口上。这个过程默认采用Round Robin负载均衡算法。 4.kube-proxy在运行过程中动态创建与Service相关的Iptables规则,这些规则实现了ClusterIp及NodePort的请求流量重定向到kube-proxy进程上对应服务的代理端口功能。 5.kube-proxy通过查询和监听API Server 中Service与Endpoints的变化,为每个Service都建立一个“服务代理对象”,并自动同步。服务代理对象是kube-proxy程序内部的一种数据结构,它包括一个用于监听此服务请求的SockerServer,SocketServer的端口是随机选择一个本地空闲端口。此外,kube-proxy内部创建了一个负载均衡器-LoadBalancer. 6.针对发生变化的Service列表,kube-proxy会逐个处理: a. 如果没有设置集群IP,则不做任何处理,否则,取该Service的所有端口定义列表。 b.为Service端口分配服务代理对象并为该Service创建相关的Iptables规则。 c.更新负载均衡器组件中对应Service的转发地址列表 7.kube-proxy在启动时和监听到Service或Endpoint的变化后,会在本机Iptables的NAT表中添加4条规则链。 a.KUBE-PORTALS-CONTAINER: 从容器中通过Cluster IP 和端口号访问service. b.KUBE-PORTALS-HOST: 从主机中通过Cluster IP 和端口号访问service. c.KUBE-NODEPORT-CONTAINER:从容器中通过NODE IP 和端口号访问service. d. KUBE-NODEPORT-HOST:从主机中通过Node IP 和端口号访问service. |
Service提供常用的类型有:
- ClusterIP,也是默认方式。Service会分配一个集群内部的固定虚拟IP,实现集群内通过该IP来对POD进行访问。这个又有两类,上面说到的最普通的Service,ClusterIP还有一种是Headless Service,这种形式不会分配IP也不会通过kube-proxy做反向代理或者负载均衡,而是通过DNS提供稳定的网络ID来访问,DNS会将headless service的后端直接解析为POD的IP列表,这种主要是共StatefulSet类型使用。
- NodePort,这种类型的Service是除了使用ClusterIP的功能外还会映射一个宿主机随机端口到service上,这样集群外部可以通过宿主机IP+随机端口来访问。
- LoadBalancer:和nodePort类似,不过除了使用ClusterIP和NodePort之外还会向使用的公有云申请一个负载均衡器,从而实现集群外部通过LB来访问服务 (公有云负载 要花钱)
- ExternalName:是Service的一种特例,此模式主要面对运行在集群外部的服务,通过它可以将外部服务映射到k8s集群,具备k8s内服务的一些特性,来为集群内部提供服务。
| 1 2 3 4 5 6 |
简单概括: 1.ClusterIP,默认类型,自动为每个Pod分配一个仅cluster内部可以访问的虚拟IP 2.NodePort,在ClusterIp的基础上,为每台机器绑定一个端口。这样就可以通过NodeIP:NodePort(节点ip:端口)来访问该服务 3.loadBalaner,在NodePort的基础上,借助cloud provider创建一个外部负载均衡器并将请求转发到NodePort (需要独立收费外部设备) 4.Externalname,把集群外部的服务引入到集群内部来,在集群内部直接 使用,没有任何类型代理被创建,只有kubernetes1.7以上版本才支持 |
要说一下ClusterIP这个东西,这是通过yaml安装的一个coredns插件,它就的配置清单中就定义了service。
| 1 |
kubectl get svc |

这个servic ip地址段是在部署API server的时候, API server服务 配置文件中定义的地址段。而且在Flannel中都没有这个地址段。相比之下POD的IP其实是实实在在配置在容器中的。
最重要的是集群中任何节点上都没有关于这个网段的路由信息,那么集群内部是如何通过这个完全虚拟的IP来访问的呢?这就要说到kube-proxy了

你看在集群的任何机器上都可以PING通这个地址。我们来看看这个svc的详情
| 1 |
kubectl describe svc myapp-nodeport |

| 1 2 |
这个10.101.188.44 serviceIP关联了Endpoints,那么现在就有了一个大致的认识就是你访问10.101.188.44就是访问10.244.1.93:80,10.244.1.94:80,10.244.2.96:80其中一个,而这个IP就是POD的真实IP,这个IP段是在Flannel上配置过的。 下面再来看一张图: |

| 1 2 3 4 5 6 7 |
在IPVS规则中定义了访问10.101.188.44就会转发到(10.244.1.93:80,10.244.1.94:80,10.244.2.96:80)轮循, 所以通过上面我们就知道它其实是通过IPVS规则来转发的根本不是通过路由来实现的。可是你想过没有这个规则是谁生成的呢?其实就是kube-proxy来生成的,而且这样的规则会同步到集群其他机器上,哪怕这个POD没有运行在自己的机器上也要有这样的规则,只有这样才能保证集群任何一台主机都可以通过这个serviceIP来访问到POD,当面临跨主机的时候才会用到路由规则,由Flannel的隧道来进行转发到真实POD所在主机,然后由该主机的kube-proxy来转发到具体的POD上。 这时候我们就明白了kube-proxy的大致作用,当service有了IP和端口,以及POD的IP和端口对应关系,以及宿主机随机端口到service的映射,就可以完成对内、外请求的转发,而转发就是,本地转发或是用IPVS规则,而远程则用了路由信息。 集群中每个NODE都运行一个kube-proxy进程,这个就是service的载体。它负责建立、删除和更新IPVS规则、通知API SERVER自己的更新,或者从API service那里获取其他kube-proxy的IPVS规则变化来更新自己的。 |
但是 userspace 模式每次请求都要走一遍kube-proxy,那么kube-proxy的频繁任务太重。并且效率不高怎么办?于是诞生了iptables模式
iptables
在这种模式下kube-proxy监控kubernetes对svc和endpoints对象进行增删改查。
并且这种模式使用iptables来做用户态的入口。而真正提供服务的是内核的Netilter,Netfilter采用模块化设计,具有良好的可扩充性。其重要工具模块IPTables从用户态的iptables连接到内核态的Netfilter的架构中,Netfilter与IP协议栈是无缝契合的,并允许使用者对数据报进行过滤、地址转换、处理等操作。这种情况下proxy只作为Controller。
Kube-Proxy 监听 Kubernetes Master 增加和删除 Service 以及 Endpoint 的消息。对于每一个 Service,Kube Proxy 创建相应的 IPtables 规则,并将发送到 Service Cluster IP 的流量转发到 Service 后端提供服务的 Pod 的相应端口上。并且流量的转发都是在内核态进行的,所以性能更高更加可靠。
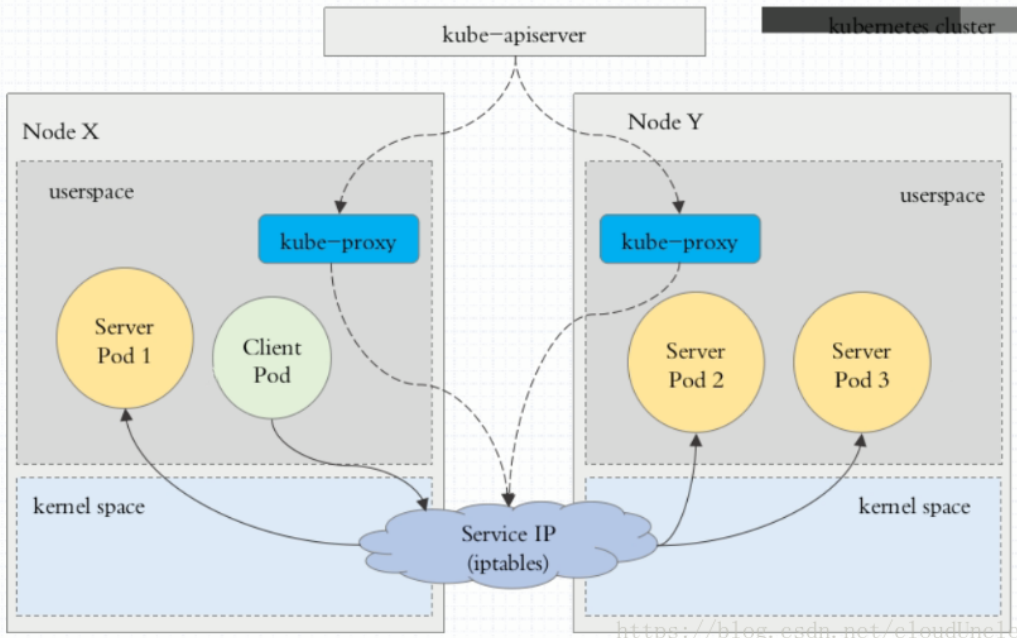
此图片来源于网络,懒不想画了。
| 1 |
在这种模式下缺点就是在大规模的集群中,iptables添加规则会有很大的延迟。因为使用iptables,每增加一个svc都会增加一条iptables的chain。并且iptables修改了规则后必须得全部刷新才可以生效。 |
IPVS
IPVS相对于iptables来说效率会更加高,使用ipvs模式需要在允许proxy的节点上安装ipvsadm,ipset工具包加载ipvs的内核模块。并且ipvs可以轻松处理每秒 10 万次以上的转发请求。
当proxy启动的时候,proxy将验证节点上是否安装了ipvs模块。如果未安装的话将回退到iptables模式。
这种模式,kube-proxy 会监视 Kubernetes Service 对象和 Endpoints ,调用 netlink 接口以相应地创建 ipvs 规则并定期与 Kubernetes Service 对象和 Endpoints 对象同步 ipvs 规则,以确保 ipvs 状态与期望一 致。访问服务时,流量将被重定向到其中一个后端 Pod
ipvs模式也是基于netfilter,对比iptables模式在大规模Kubernetes集群有更好的扩展性和性能,支持更加复杂的负载均衡算法(如:最小负载、最少连接、加权等),支持Server的健康检查和连接重试等功能。ipvs依赖于iptables,使用iptables进行包过滤、SNAT、masquared。ipvs将使用ipset需要被DROP或MASQUARED的源地址或目标地址,这样就能保证iptables规则数量的固定,我们不需要关心集群中有多少个Service了

- 本文固定链接: http://www.yoyoask.com/?p=2163
- 转载请注明: shooter 2020年03月02日 于 SHOOTER 发表