FaaS 和容器
容器镜像因其颠覆式创新成为云原生时代应用部署格式的事实标准。头部云厂商 FaaS (Function-as-a-Service) 服务如阿里云函数计算、AWS Lambda 也相继在2020年支持使用容器镜像部署函数,全面拥抱容器生态。自发布以来,开发者陆续将机器学习、音视频处理、事件驱动离线数据处理、前端自动化等多个场景使用镜像快速无服务器化,提高效率、降低成本。然而,冷启动一直是 Serverless 无法绕开的问题。容器镜像需要将数据通过网络远程下载并解压,对于GB级别的镜像,拉取时间可能高达分钟级别,客观上放大了冷启动副作用,阻碍实时应用的 Serverless 演进。
函数计算镜像加速功能
传统的镜像拉取加速强调"开发者负责",如精简镜像,合理分配镜像层,multi-stage 构建,使用工具(如 docker-slim)去除不需要的数据,遵循构建最佳实践等。这些工作不仅加重了用户负担,加速效果有限,且有运行时稳定性风险。阿里集团超大规模和场景高度复杂的容器环境,对镜像存储、加速技术有深厚的积累,出色地承担了3年双十一,双十二,春节等大促秒杀场景的严苛的挑战。阿里云 Serverless 同容器镜像、存储等服务深度合作,将内部创新在函数计算输出:杭州、北京、上海、美东、美西正式发布了镜像加速功能。该功能将原本属于开发者的镜像优化负担转由函数计算承担,进一步帮助开发者提高生产效率,专注业务创新。
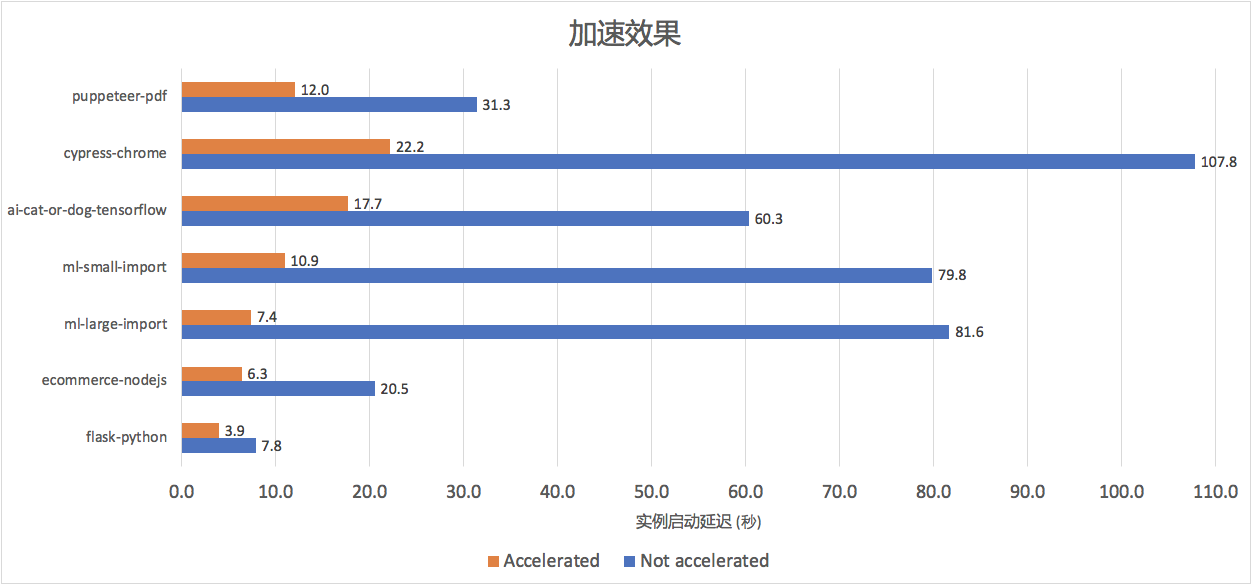
加速效果
我们在选择了内部生产环境和开源社区的工作负载,覆盖机器学习、人工智能、前端自动化、Web 应用等7种镜像大小、IO 访问模式、启动命令的不同组合作为 benchmark,部署在 FC 北京区域。如下图所示,函数计算开启镜像加速功能后加速普遍超过 50%,对于机器学习场景中常见的臃肿镜像(如多个团队共享基础镜像, ml-small-import, ml-large-import, ai-cat-or-dog)加速效果更为明显(约 70%-86%),镜像越大优化空间往往越高。

使用方式
镜像加速可以通过控制台、CLI 工具或是 FC SDK 开启,详细步骤参加镜像拉取加速文档
• 方式一:在函数计算控制台函数配置下选择“开启镜像加速”。


• 方式二:使用 Funcraft 工具部署
在已有的 CustomContainerConfig 配置下添加 AccelerationType: Default 如需关闭则配置 AccelerationType:
None
CustomContainerConfig:
Image: registry-vpc.cn-beijing.aliyuncs.com/fc-demo/python-flask:v0.1
AccelerationType: Default功能特点
FC 镜像加速具备以下特点:
- 使用简单:只需在函数上开启镜像加速,函数计算会自动制作加速镜像和缓存,转换完成后(5分钟以内),函数自动采用加速镜像缓存。
- 专注业务创新:开发者无需花费时间刻意精简优化镜像大小或严格区分 Serverless 和 Serverfull 应用镜像的构建方式,FC 负责按照应用实际使用数据拉取和解压。
- 加速免费,使用门槛低:镜像加速开启不产生额外费用,也不需要开发者额外购买或升级任何其他服务。事实上由于镜像拉取时间变短,相应的请求费用也随之降低。
- 极速弹性、缩容到 0、事件触发:FaaS 结合容器镜像已经极大简化了应用迁移至 Serverless,加速功能进一步解锁了实时、准实时工作负载,曾经需要分钟级别的容器启动现在可以几秒内快速启动,真正实现缩容到0。
镜像拉取为什么慢?
一个 OCI V1 容器镜像包含多个层(layer),每层都是一个压缩打包的文件系统(文件夹),通常以 tar.gz 格式存储在远端服务(如对象、文件存储)。拉取镜像时步骤如下:
- 将各个 layer 对应的 tar.gz 文件完整下载至本地
- 每层顺序解压
- 将各个层合并(如 Overlay)作为 rootfs 启动容器
上述步骤虽然简单,却是镜像拉取慢的主要原因:
• 文件格式缺陷、粗粒度数据分层、顺序解压:gzip 层导致无法细粒度随机读取应用实际需要的数据,且要求所有层单线程顺序解压。实际观察发现镜像层可以通过并发下载提高速度,然而解压环节在 gzip 格式下却很难优化。
• 低效的压缩/解压缩算法:镜像层采用的 gzip,benchmark gzip 解压速度对比 lz4 平均慢接近9倍。
• 全量数据下载:同样由于粗粒度的分层和 gzip 格式(不支持 seek),镜像数据不论是否实际有用,都要被完整下载至本地。
综上原理,镜像拉取时间和镜像大小成正比,而容器镜像构建过程中运行 apt/yum install, 无用的测试、数据文件,构建过程中执行 chmod/chown 等命令造成同一数据复制多份,极易引入大量应用不需要的数据。
加速原理
函数计算将阿里集团成熟的镜像加速技术应用在公共云服务中,加速技术围绕两个核心思路:
• 按需加载:仅读取应用真实需要的数据,极大减少数据传输量
• 更高效的存储和算法:相同大小的数据,更快地解压
按需加载
Benchmark 中包含镜像数据加载率在 12% - 84% 之间,除了镜像较小的 web 应用,大部分场景数据利用率低于 50%。以层(layer)作为数据分发单位的原始镜像被转换成支持细粒度按需读取的数据格式,并存放在延迟和吞吐都更优的存储中。

高效解压
除了按需加载带来的下载步骤延时节省,镜像加速技术在数据解压步骤也同样做了大量优化。下图可以看出即使在加载 70% 以上全量数据的情况下,优化效果仍然超过 60%。

未来规划
函数计算正式发布了容器镜像加速,通过按需读取和更高效的解压技术在不同场景下加速 50%-80%,即使 GB 级别的镜像也可以在几秒内完成端到端启动。加速功能结合函数计算极致弹性和事件触发的特点,解锁了更多对实时要求高的工作负载。容器应用可以更容易地享受 Serverless 特性,真正做到缩容到0以及快速大规模扩容。FC 在未来会持续优化冷启动各个环节提供极致弹性,承担更多用户责任,使开发者专注业务创新。
附录:实验场景数据
| Benchmark | 场景 | 镜像压缩大小 | 解压后大小 |
|---|---|---|---|
| python-flask | Web 应用 | 46MB | 118MB |
| ecommerce-nodejs | 电商, nodejs express | 130MB | 371MB |
| ml-small-import/;ml-large-import | 机器学习,使用 numpy, pandas, pystan 等库 | 728MB | 2.392GB |
| ai-cat-or-dog | 机器学习,人工智能,推理预测 tensorflow, keras 等库 | 790MB | 1.824GB |
| puppeteer-pdf | Headless chrome,网页转 PDF, 使用 puppeteer, nodejs express | 332MB | 894MB |
| cypress-chrome | 前端 UI 自动化,cypress, headless chrome | 980MB | 2.608GB |
参考
• 函数计算支持容器镜像-加速应用 Serverless 进程
• New for AWS Lambda – Container Image Support
• 函数计算镜像拉取加速文档
• Docker Slim: Minify and Secure Docker containers (free and open source!)
•christopher-talke/node-express-puppeteer-pdf-example
•awesome-fc/custom-container-docs
作者信息:Shuai Chang,阿里云云原生 Serverless 团队高级技术专家,主导了函数计算同容器技术生态融合以及 FaaS 云原生可观测。
本文为阿里云原创内容,未经允许不得转载。