B树
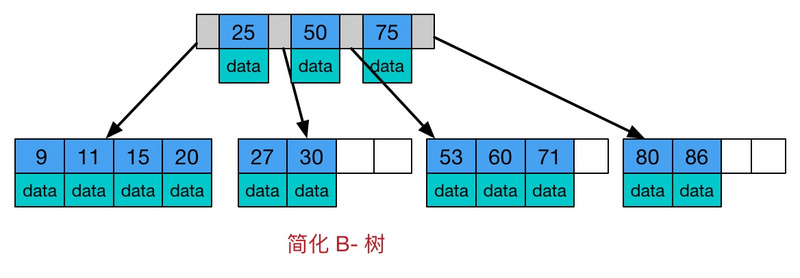 B树是一种多路自平衡搜索树,它类似普通的二叉树,但是B书允许每个节点有更多的子节点。B树示意图如下:
B树是一种多路自平衡搜索树,它类似普通的二叉树,但是B书允许每个节点有更多的子节点。B树示意图如下:
B树的特点:
(1)所有键值分布在整个树中
(2)任何关键字出现且只出现在一个节点中
(3)搜索有可能在非叶子节点结束
(4)在关键字全集内做一次查找,性能逼近二分查找算法
3:所有叶子节点都出现在同一层,且叶子节点不包含任何关键字信息(可以看做是外部接点或查询失败的接点,实际上这些结点不存在,指向这些结点的指针都为null)
4:每个非叶子节点包含有n个关键字信息(n,P0,K1,P1,K2,P2,......,Kn,Pn),其中:
a) Ki (i=1...n)为关键字,且关键字按顺序升序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: [ceil(m / 2)-1]<= n <= m-1。
这三天摘抄自文末参考,大致理解一下就行。
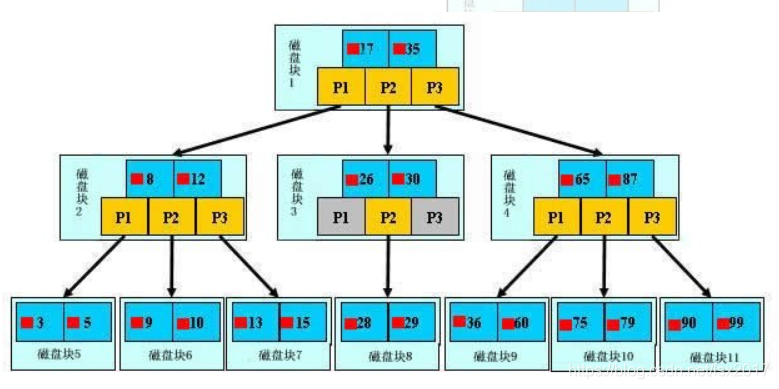
来模拟下查找文件29的过程:
(1) 根据根结点指针找到文件目录的根磁盘块1,将其中的信息导入内存。【磁盘IO操作1次】
(2) 此时内存中有两个文件名17,35和三个存储其他磁盘页面地址的数据。根据算法我们发现17<29<35,因此我们找到指针p2。
(3) 根据p2指针,我们定位到磁盘块3,并将其中的信息导入内存。【磁盘IO操作2次】
(4) 此时内存中有两个文件名26,30和三个存储其他磁盘页面地址的数据。根据算法我们发现26<29<30,因此我们找到指针p2。
(5) 根据p2指针,我们定位到磁盘块8,并将其中的信息导入内存。【磁盘IO操作3次】
(6) 此时内存中有两个文件名28,29。根据算法我们查找到文件29,并定位了该文件内存的磁盘地址。
B+Tree
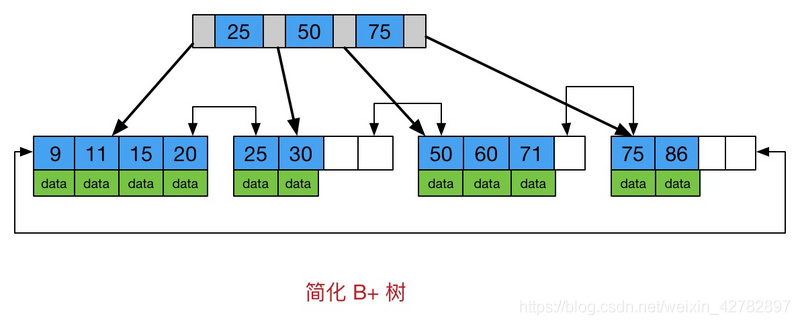
从图中也可以看到,B+树与B树的不同在于:
(1)所有关键字存储在叶子节点,非叶子节点不存储真正的data
(2)为所有叶子节点增加了一个链指针
那么问题来了,为什么用B/B+树这种结构来实现索引呢??
答:红黑树等结构也可以用来实现索引,但是文件系统及数据库系统普遍使用B/B+树结构来实现索引。mysql是基于磁盘的数据库,索引是以索引文件的形式存在于磁盘中的,索引的查找过程就会涉及到磁盘IO(为什么涉及到磁盘IO请看文章后面的附加理解部分)消耗,磁盘IO的消耗相比较于内存IO的消耗要高好几个数量级,所以索引的组织结构要设计得在查找关键字时要尽量减少磁盘IO的次数。为什么要使用B/B+树,跟磁盘的存储原理有关。
局部性原理与磁盘预读
为了提升效率,要尽量减少磁盘IO的次数。实际过程中,磁盘并不是每次严格按需读取,而是每次都会预读。磁盘读取完需要的数据后,会按顺序再多读一部分数据到内存中,这样做的理论依据是计算机科学中注明的局部性原理:
-
当一个数据被用到时,其附近的数据也通常会马上被使用 -
程序运行期间所需要的数据通常比较集中
(1)由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),
因此对于具有局部性的程序来说,预读可以提高I/O效率.预读的长度一般为页(page)的整倍数。
(2)MySQL(默认使用InnoDB引擎),将记录按照页的方式进行管理,每页大小默认为16K(这个值可以修改)。linux 默认页大小为4K。
B-Tree借助计算机磁盘预读的机制,并使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个结点只需一次I/O。
假设 B-Tree 的高度为 h,B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logdN)O(h)=O(logdN)。一般实际应用中,出度d是非常大的数字,通常超过100,因此h非常小(通常不超过3,也即索引的B+树层次一般不超过三层,所以查找效率很高)。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
为什么mysql的索引使用B+树而不是B树呢??
(1)B+树更适合外部存储(一般指磁盘存储),由于内节点(非叶子节点)不存储data,所以一个节点可以存储更多的内节点,每个节点能索引的范围更大更精确。也就是说使用B+树单次磁盘IO的信息量相比较B树更大,IO效率更高。
(2)mysql是关系型数据库,经常会按照区间来访问某个索引列,B+树的叶子节点间按顺序建立了链指针,加强了区间访问性,所以B+树对索引列上的区间范围查询很友好。而B树每个节点的key和data在一起,无法进行区间查找。