文章目录
1.iNode:磁盘中块和扇区
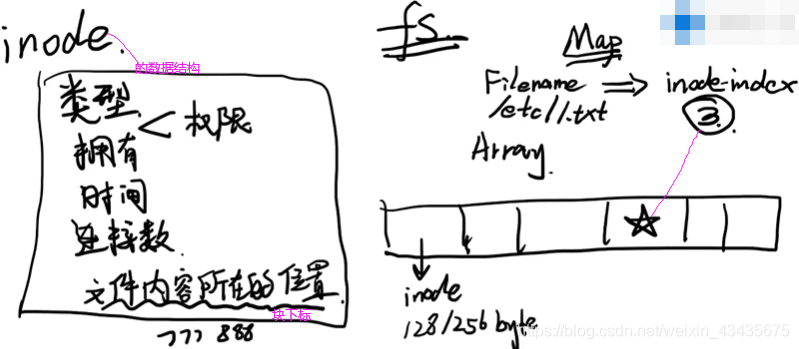
linux文件系统中iNode用来存储文件原数据信息,不存储文件内容,原数据信息包括:
类型:是个目录还是普通文件
拥有者:owner还是group owner。
时间:ctime:上次inode变动时间。atime:上次访问时间。mtime:上次文件内容发生变动时间。
连接数:有多少文件名同时指向inode。一个文件名只对应一个inode,但一个inode可能被多个文件名同时指向。
文件内容所在的位置:文件真正内容所在磁盘块的标号。
文件系统fs在格式化好后,inode以什么样格式存储的呢?整个inode以数组形式存储,每个元素是一个inode,每个inode大小根据当前文件系统以及磁盘大小,inode会有一个固定128/256字节大小。
除了inode数组,fs初始化好后还会生成一个Map映射关系表(存储filename和inode index)。现在要读取/ect/1.txt,整个过程怎么样的?先根据文件名到Map中找到inode index,找到下标为假如是3的inode后拿出来如下图左边。当前在读取/ect/1.txt,所以查看是否有读权限,如果有读权限就继续往下,找到文件内容所在位置(磁盘上块的下标)。
文件内容在磁盘中存储区域如下,以块进行分隔,每个块大小也是根据当前fs和整个磁盘大小决定,并不是一个特定大小。 扇区在磁盘生产时有多少个扇区,每个大小是定的,早期扇区512byte,现在4k。文件系统fs在文件访问过程中不可能直接使用扇区,扇区是硬件上的概念,所以抽象出一个概念:fs角度去看最小文件存储单元就是块,一个块可以有一个或多个扇区组成(2的幂次方即1,2,4…个扇区)。

一个块采用多少扇区也是有权衡的,比如一个文件块好几兆,存一个1k文件也要占一个文件块,造成磁盘空间浪费。块选择过小的话也不好,如果一个块大小1bit,导致一个文件假如是1kb,它所在的块由1千个块组成,在inode中存储文件内容所在位置这个字段时候造成存1千个块信息,一个inode不可能128/256字节大小了,一个inode会很大,进而导致inode数组会很大,整个inode区大,这样导致磁盘损耗大量空间存储inode信息,较少的空间存储真正文件内容了,最终是一个权衡过程。
即使进行了这样的权衡,目前存在问题,比如经常听到inode用完了即inode数组初始化大小,声明完数组大小后不能增加或减少了。inode数组用完了即使磁盘还有额外空间也不能存储文件了,常见特别零碎文件又特别多占据磁盘大量inode导致整个inode用完。如早期docker采用overlay文件存储格式导致镜像的碎文件很多,导致inode用尽这样问题,后面采用overlay2文件存储格式一定程度上解决了这问题。
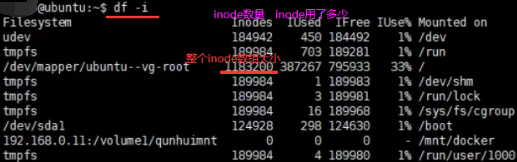
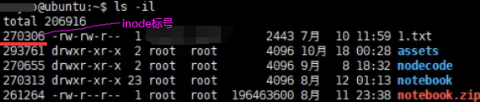
查看linux系统中inode数组以及每个文件所对应inode标号。df -i(inode),查看当前文件夹下文件所在的inode标号是什么ls -il。访问1.txt先查文件名和inode标号映射即Map,1.txt能找到270306这个标号。根据这个标号到1183200这个数组中拿取第270306个标号的inode。根据这个inode信息查看权限,最终找到1.txt在磁盘中存储位置,最后把这些磁盘块进行读取,最终读取到1.txt这个文件。
2.文件查找与读取命令:C语言中‘\0’表示的空字符,则其对应的ASCLL码值为0。
2.1 find:找文件
过滤一下看文件大小,-print0将如上三行打印为1行并用null即‘\0’隔开,再用xargs -0即用‘\0’再分开,原因是默认管道到下一个里面空格会出错。

如上/是整个系统搜索慢,如下当前路径搜索快。

日志文件没清空非常大,要找到删除,如下找系统中大文件,超过10M。

如下查找文件夹,文件夹有相应名字或大小属性。

如下基于修改时间,time是天。-1:今天一天之内。1:1天前这一天。+1:1天前。



如下指定最大文件深度

如下是find指令总结

2.2 grep:找文件中内容
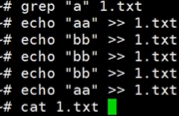

如下*可换成* .txt

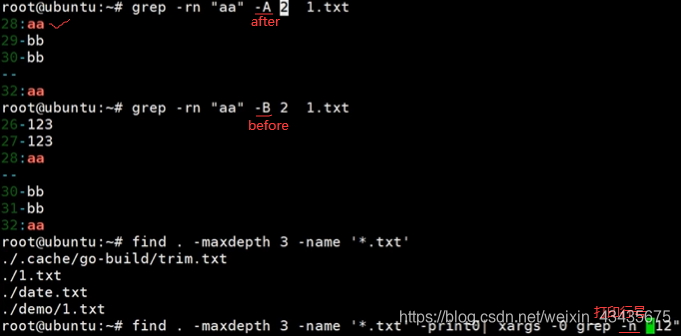
-r:递归子路径,-n:显示行号

如下用于java日志文件非常大,要grep出某个异常如ioexception,且需要打印出exception下面几行看什么出了错。
2.3 cat/more:查看文件全部内容
行号:number
cat的文件非常大,非常占用cpu和内存,这时候可以每次读取一小部分
如下通过空格往后翻页

如下指定从第四行开始读

如下查看前后10行
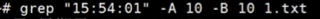

2.4 head/tail:查看文件部分内容

如下打印文件最后两行,tail -f 阻塞监控。

df -h查看磁盘使用,占用率太高就需要使用前面find,grep指令并进行删除。
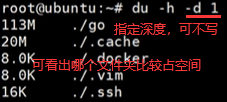
如上找出占空间的文件夹再去里面找。

题目:输出当前路径及当前路径子路径下所有.txt文件,要求大小超过1M,并且按照从大到小顺序进行排序输出前10个?
先通过find . -name '*.txt' -size +1M -type f查看是否有大于1M的txt文件,没有的话就不用继续了
再通过find . -name '*.txt' -size +1M -type f -print0|xargs -0 du -m|sort -nr|head -10
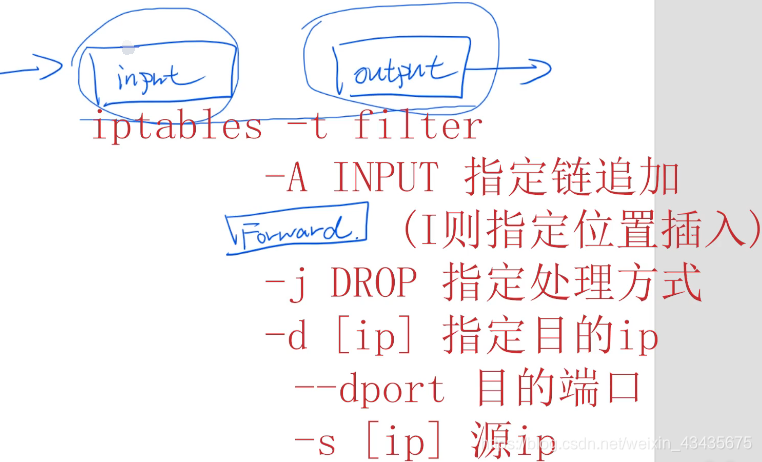
3.iptables:对网络上数据包通过表形式进行规则的修改
3.1 filter表:policy是默认意思
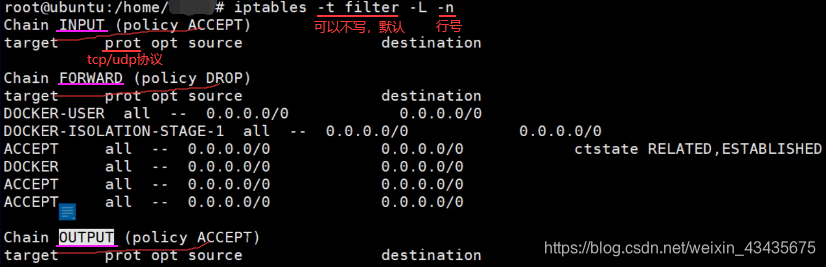
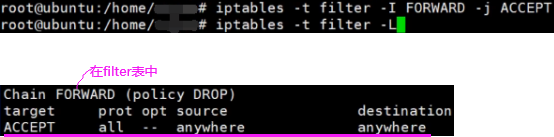
man iptables查看有哪些表。filter表会将进入当前机器数据包进行过滤,以及从机器出去的数据包,不符合条件不给发出去。nat表改变目的或源地址和端口。

表中有链构成,进入和出去配置规则放在链中,如下看filter表自带的三个链,FORWARD链和net表相关。

如下本机收到一个包,这个包目的地址是8081且是tcp包的话丢弃。-A:Append
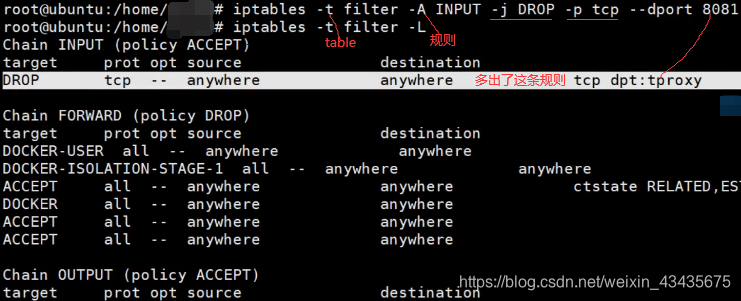

如下删除后又能访问了。

如上是在input链上进行的防火墙的设置,如下也可以设置output链。

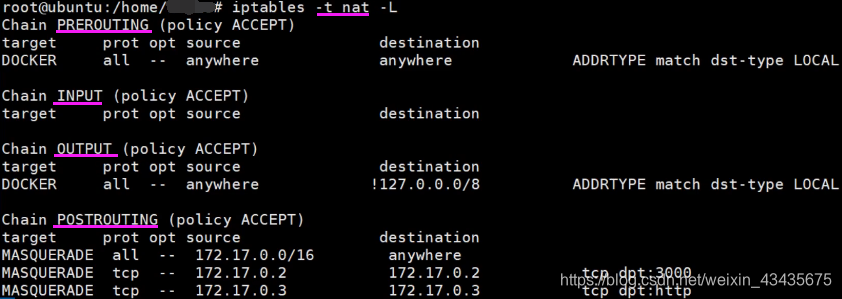
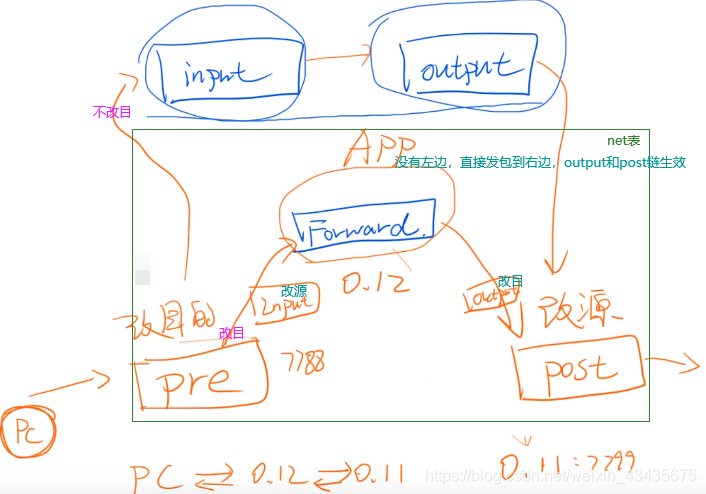
3.2 net表:4个链

下面做一件事情:把0.12的7788端口转发到0.11的7799端口,实现反向代理。这件事分为下面两步:如下第二条虽然请求通过第一条是转发过去了,但是响应要改为本机。
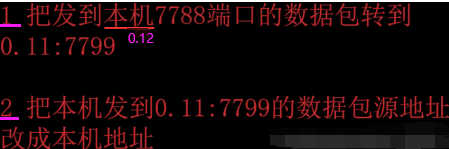
如下是在0.12机器shell上。

如下是上面一行命令执行结果。

重写FORWARD链为accept。
如上不是配置xx.conf的服务不需要重启,即时生效,如下都能访问了。


如下橙色方框是net表的链。两条路:改目或不改目。
4.hash:取余
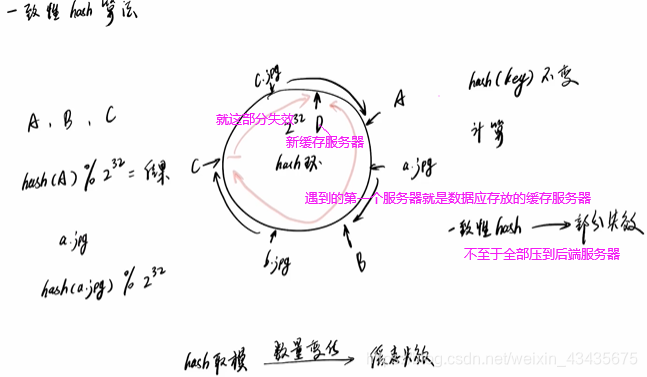
一致性hash算法:假设有三台缓存服务器S0,S1,S2,有三万张图片进行缓存,最好能均匀缓存到服务器上分担缓存压力。简单做法对缓存下来的键key(图片序号)进行哈希计算得到整数,再用缓存服务器数量对这个值取模计算,用取模产生的余数来决定数据应该缓存在哪台服务器上。
对同一个图片名称即key编号做相同哈希计算时得到hash值不变的,所以当需要访问图片时再次对图片名称进行hash计算和取模计算就能知道图片存放在哪台服务器上,只要在这台服务器上查找图片就行。

增加服务器时,图片之前存在S0上,S2服务器读不到,大量缓存失效导致缓存雪崩。所以要用到一致性哈希。

如下的圆有2的32次方个点组成,称为hash环。A,B,C三台缓存服务器的编号做hash计算即用2的32次方取模,得出的结果一定在0到2的32次方之间的整数对应hash环上一点。a.jpg找到图片的key,相同方法映射到hash环上。缓存服务器和图片都映射到了hash环上了,现在要确定图片应该被缓存在哪台服务器上?沿顺时针方向。。。加入新服务器D时,c.jpg会缓存到D上,不会到A上,但其他不变。
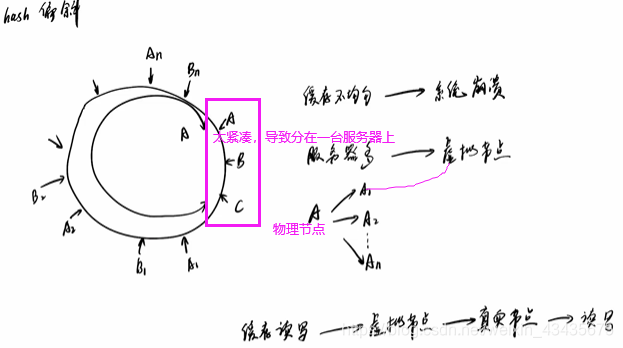
一致性hash算法有个问题就是hash偏斜即A,B,C三台服务器太靠一起,导致大量图会缓存到一台服务器上。解决:还是三台物理服务器,多加点虚拟节点进行分布。
B站/知乎/微信公众号:码农编程录
