线性回归
案例分析
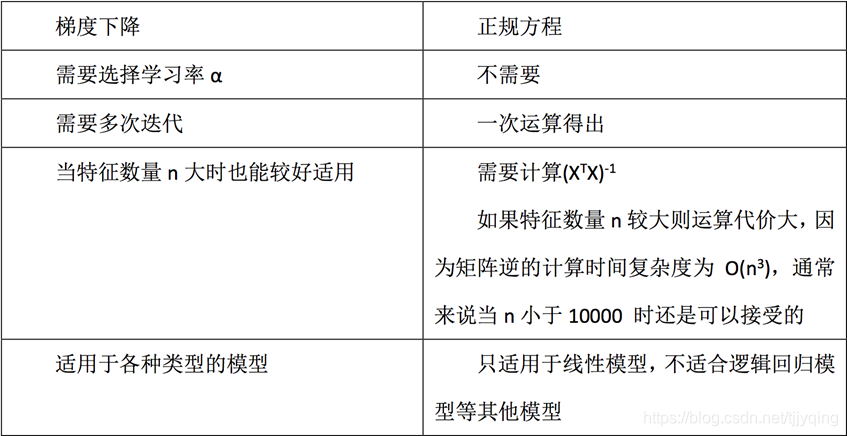
正规方程、梯度下降、岭回归
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
def lin():
# 加载数据
lb = load_boston()
# 分割数据
x_train, x_test, y_train, y_test = train_test_split(lb.data, lb.target, test_size=0.25)
# 标准化处理,实例化两个标准化API
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
std_y = StandardScaler()
y_train = std_y.fit_transform(y_train.reshape(-1, 1))
y_test = std_y.transform(y_test.reshape(-1, 1))
# 正规方程求解
lr = LinearRegression()
lr.fit(x_train, y_train)
print(lr.coef_) # 这个显示回归系数
y_lr_predict = std_y.inverse_transform(lr.predict(x_test))
print('预测的房价是', y_lr_predict)
print('正规方程均方误差:', mean_squared_error(std_y.inverse_transform(y_test), y_lr_predict))
# 梯度下降预测(这里数据太少,效果貌似很不好,建议大于10万样本)
sgd = SGDRegressor()
sgd.fit(x_train, y_train)
print(sgd.coef_)
y_sgd_predict = std_y.inverse_transform(sgd.predict(x_test))
print('预测的房价是', y_sgd_predict)
print('梯度下降均方误差:', mean_squared_error(std_y.inverse_transform(y_test), y_sgd_predict))
if __name__ == '__main__':
lin()
使用条件
过拟合和欠拟合
欠拟合
一般为模型过于简单
过拟合 overfitting
原始特征过多,存在一些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾各个测试数据点
过拟合的解决办法
正则化,岭回归
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
def lin():
# 岭回归
rd = Ridge(alpha=1)
rd.fit(x_train, y_train)
print(rd.coef_)
y_rd_predict = std_y.inverse_transform(rd.predict(x_test))
print('预测的房价是', y_rd_predict)
print('梯度下降均方误差:', mean_squared_error(std_y.inverse_transform(y_test), y_rd_predict))
return None