进程线程练习Plus
1. 数据检索多进程
2. 求东方财富平均市值
3. 多线程统计平均市值
4. 多进程统计平均市值
5. 单线程爬取邮箱
6. 多线程爬取邮箱
7. 多线程简单文件归并
8. 多线程文件归并—多个文件交叉写入
++++++++++++++++++++++++++++++++++++++++++
1.数据检索多进程
昨天写了一个多线程的,逻辑差不太多,也是全部将数据载入内存先;
import multiprocessing
def finddata(datalist,istart,iend,searchstr,lastlist):
for i in range(istart,iend):
line=datalist[i].decode("gbk","ignore")
if line.find(searchstr)!=-1:
print(line)
lastlist.append(line)
def loaddata(datalist):
path = "D:\\Python代码\\class15\\图形化编程\\txm.txt" # 路径
file = open(path, "rb")
datalist.extend(file.readlines()) # 全部读入内存
if __name__=="__main__":
datalist = multiprocessing.Manager().list() #主进程有一份,读取文件
lastlist=multiprocessing.Manager().list() #保存结果
loaddata(datalist)
lines=len(datalist)
N=10
processlist=[]
findstr=input("请输入查询的人名:")
for i in range(0,N-1):
process=multiprocessing.Process(target=finddata,
args=(datalist,
i*(lines//(N-1)),
(i+1)*(lines//(N-1)),
findstr,
lastlist))
process.start()
processlist.append(process)
mylastp=multiprocessing.Process(target=finddata,
args=(datalist,
0,
lines,
findstr,
lastlist))
mylastp.start()
processlist.append(mylastp)
for process in processlist:
process.join() #主进程等待其他进程都干完活
file=open("last.txt","wb") #保存结果
for line in lastlist:
file.write(line.encode("utf-8"))
file.close()
运行效果:

2.求平均市值:
这是从东方财富网爬下来的股票历年数据(爬虫传送门:爬取东方财富历年股票数据),可以看出,市值在第14栏,因此代码如下

import csv
def gettotall(path):
reader=csv.reader(open(path,"r"))
num=0
alldata=0
for item in reader:
if num==0:
pass
else:
alldata+=eval(item[13]) #累加所有市值
num+=1
return alldata/num
path = r"D:\Python代码\class20\down\20201010\0600009.csv"
print(gettotall(path))
运行效果:
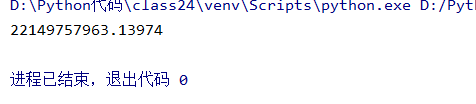
3.多线程统计平均市值:
主要用到队列共享数据,可以同时统计多个文件;
import csv
import threading
import queue
import os
myqueue=queue.Queue(0)#0表示无限容量
class getdatatotal(threading.Thread):
def __init__(self,path,queue):
threading.Thread.__init__(self)
self.path=path
self.queue=queue
def run(self):
print("start",self.getName())
reader = csv.reader(open(self.path, "r"))
num = 0
alldata = 0
for item in reader:
if num == 0:
pass
else:
alldata += eval(item[13]) # 累加所有市值
num += 1
print(alldata / num,self.getName())
self.queue.put(alldata / num) #保存结果到队列
path="D:\\Python代码\\class20\\down\\20201010"
filelist=os.listdir(path)
filepathlist=[]
for filename in filelist:
filename=path+"\\"+filename
filepathlist.append(filename)
threadlist=[]
for path in filepathlist:
mythread=getdatatotal(path,myqueue)
mythread.start()
threadlist.append(mythread) #创建线程加入列表
for thread in threadlist:
thread.join()
while not myqueue.empty():
data=myqueue.get()
print(data)
运行效果:
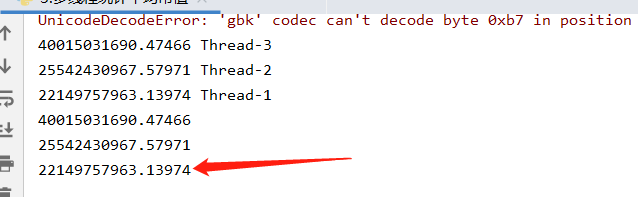
与上一题一致
4.多进程统计平均市值:
import csv
import multiprocessing
import os
def gettotall(path,queue):
reader=csv.reader(open(path,"r"))
num=0
alldata=0
for item in reader:
if num==0:
pass
else:
alldata+=eval(item[13]) #累加所有市值
num+=1
queue.put(alldata/num)
if __name__=="__main__":
queue = multiprocessing.Queue()
path="D:\\Python代码\\class20\\down\\20200201"
filelist=os.listdir(path)
filepathlist=[]
for filename in filelist:
filename=path+"\\"+filename
filepathlist.append(filename)
processlist=[]
for filepath in filepathlist:
p=multiprocessing.Process(target=gettotall,args=(filepath,queue))
p.start()
processlist.append(p)
for process in processlist:
process.join()
while not queue.empty():
data=queue.get()
print(data)
运行效果:

也是一致的
5.单线程爬取邮箱(BFS模式):
爬取天涯社区的邮箱信息,因为采用了BFS模式,理论上如果从百度爬起可以爬到世界尽头
import urllib.request
import urllib
import re
import queue
import threading
def getallyurl(data):
alllist=[]
mylist1=[]
mylist2=[]
mylist1=gethttp(data)
if len(mylist1)>0:
mylist2=getabsyurl(mylist1[0],data)
alllist.extend(mylist1)
alllist.extend(mylist2)
return alllist
def getabsyurl(url,data):
try:
regex=re.compile("href=\"(.*?)\"",re.IGNORECASE)
httplist=regex.findall(data)
newhttplist=httplist.copy() #深拷贝
for data in newhttplist:
if data.find("http://")!=-1:
httplist.remove(data)
if data.find("javascript")!=-1:
httplist.remove(data)
hostname=gethostname(url)
if hostname!=None:
for i in range(len(httplist)):
httplist[i]=hostname+httplist[i]
return httplist
except:
return ""
def gethostname(httpstr): #抓取主机名称
try:
mailregex = re.compile(r"(http://\S*?)/", re.IGNORECASE)
mylist = mailregex.findall(httpstr)
if len(mylist)==0:
return None
else:
return mylist[0]
except:
return None
def gethttp(data):
try:
mailregex = re.compile(r"(http://\S*?)[\"|>|)]", re.IGNORECASE)
mylist = mailregex.findall(data)
return mylist
except:
return ""
def getallemail(data):
try:
mailregex = re.compile(r"([A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4})", re.IGNORECASE)
mylist = mailregex.findall(data)
return mylist
except:
return ""
def getdata(url):
try:
data = urllib.request.urlopen(url).read().decode("utf-8")
return data
except:
return "" #发生异常返回空
def BFS(urlstr,myqueue):
with sem:
threading.Thread(target=BFSget,args=(urlstr,myqueue)).start()
def BFSget(urlstr,myqueue):
myqueue.put(urlstr)
while not myqueue.empty():
url=myqueue.get() #队列弹出数据
print(url) #打印url连接
pagedata=getdata(url) #获取网页源码
emaillist=getallemail(pagedata) #提取邮箱到列表
if len(emaillist)!=0: #邮箱不为空
for email in emaillist: #打印所有邮箱
print(email)
newurllist=getallyurl(pagedata) #抓取所有的url
if len(newurllist)!=0: #p判断长度
for urlstr in newurllist: #循环处理所有url
myqueue.put(urlstr) #插入
myqueue=queue.Queue(0)
sem = threading.Semaphore(5)
BFS("http://bbs.tianya.cn/post-140-393974-5.shtml",myqueue)
#BFS("http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&srcqid=4974407339122272475&tn=48020221_29_hao_pg&wd=%E5%B2%9B%E5%9B%BD%E5%A4%A7%E7%89%87%20%E7%95%99%E4%B8%8B%E9%82%AE%E7%AE%B1&oq=%25E5%25A4%25A9%25E6%25B6%25AF%25E5%25A4%25A7%25E5%25AD%25A6%25E8%2580%2581%25E5%25B8%2588%25E9%2582%25AE%25E7%25AE%25B1&rsv_pq=e1e17d5400093975&rsv_t=83fc1KipT0e6dU2l8G8651PAihzqMxhN1tT8Ue1JiKtvBGgKILwuquM4g7%2BKNKKKp6AkBxK7opGg&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=40&rsv_sug1=4&rsv_sug7=100&rsv_sug2=0&rsv_btype=t&inputT=11395&rsv_sug4=11395")
运行效果:


爬取到的第一个邮箱与网页一致
6.多线程爬取邮箱并保存:
import urllib.request
import urllib
import re
import queue
import threading
import time
def getallyurl(data):
alllist=[]
mylist1=[]
mylist2=[]
mylist1=gethttp(data)
if len(mylist1)>0:
mylist2=getabsyurl(mylist1[0],data)
alllist.extend(mylist1)
alllist.extend(mylist2)
return alllist
def getabsyurl(url,data):
try:
regex=re.compile("href=\"(.*?)\"",re.IGNORECASE)
httplist=regex.findall(data)
newhttplist=httplist.copy() #深拷贝
for data in newhttplist:
if data.find("http://")!=-1:
httplist.remove(data)
if data.find("javascript")!=-1:
httplist.remove(data)
hostname=gethostname(url)
if hostname!=None:
for i in range(len(httplist)):
httplist[i]=hostname+httplist[i]
return httplist
except:
return ""
def gethostname(httpstr): #抓取主机名称
try:
mailregex = re.compile(r"(http://\S*?)/", re.IGNORECASE)
mylist = mailregex.findall(httpstr)
if len(mylist)==0:
return None
else:
return mylist[0]
except:
return None
def gethttp(data):
try:
mailregex = re.compile(r"(http://\S*?)[\"|>|)]", re.IGNORECASE)
mylist = mailregex.findall(data)
return mylist
except:
return ""
def getallemail(data):
try:
mailregex = re.compile(r"([A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4})", re.IGNORECASE)
mylist = mailregex.findall(data)
return mylist
except:
return ""
def getdata(url):
try:
data = urllib.request.urlopen(url).read().decode("utf-8")
return data
except:
return "" #发生异常返回空
def BFS(urlstr,myqueue):
with sem:
threading.Thread(target=newBFS,args=(urlstr,myqueue)).start()
def newBFS(urlstr,myqueue):
#print(urlstr)
pagedata = getdata(urlstr) # 获取网页源码
emaillist = getallemail(pagedata) # 提取邮箱到列表
if len(emaillist) != 0: # 邮箱不为空
for email in emaillist: # 打印所有邮箱
print(email)
myqueue.put(email+'\r\n') #队列压入邮箱
newurllist = getallyurl(pagedata) # 抓取所有的url
if len(newurllist) != 0: # p判断长度
for urlstr in newurllist: # 循环处理所有url
with sem:
threading.Thread(target=newBFS, args=(urlstr, myqueue)).start()
def BFSget(urlstr,myqueue):
myqueue.put(urlstr)
while not myqueue.empty():
url=myqueue.get() #队列弹出数据
print(url) #打印url连接
pagedata=getdata(url) #获取网页源码
emaillist=getallemail(pagedata) #提取邮箱到列表
if len(emaillist)!=0: #邮箱不为空
for email in emaillist: #打印所有邮箱
print(email)
newurllist=getallyurl(pagedata) #抓取所有的url
if len(newurllist)!=0: #p判断长度
for urlstr in newurllist: #循环处理所有url
myqueue.put(urlstr) #插入
def saveemail():
global myqueue
file=open("email.txt","wb")
while True:
time.sleep(5)
while not myqueue.empty():
data=myqueue.get()
file.write(data.encode("utf-8")) #实时写入
file.flush()
file.close()
myqueue=queue.Queue(0)
sem = threading.Semaphore(10)
timethread=threading.Timer(5,saveemail)
timethread.start()
BFS("http://bbs.tianya.cn/post-140-393974-5.shtml",myqueue)
#BFS("http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&srcqid=4974407339122272475&tn=48020221_29_hao_pg&wd=%E5%B2%9B%E5%9B%BD%E5%A4%A7%E7%89%87%20%E7%95%99%E4%B8%8B%E9%82%AE%E7%AE%B1&oq=%25E5%25A4%25A9%25E6%25B6%25AF%25E5%25A4%25A7%25E5%25AD%25A6%25E8%2580%2581%25E5%25B8%2588%25E9%2582%25AE%25E7%25AE%25B1&rsv_pq=e1e17d5400093975&rsv_t=83fc1KipT0e6dU2l8G8651PAihzqMxhN1tT8Ue1JiKtvBGgKILwuquM4g7%2BKNKKKp6AkBxK7opGg&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=40&rsv_sug1=4&rsv_sug7=100&rsv_sug2=0&rsv_btype=t&inputT=11395&rsv_sug4=11395",myqueue)
7.多线程文件归并
归并之前爬取的三个股票信息csv文件,乱序的
import csv
import threading
#缓存,实时刷新
#
def getlist(path):
reader=csv.reader(open(path,"r")) #读取文件
alllist=[]
for item in reader:#读取每一行
alllist.append(item) #加入列表
return alllist
def thread1(csvw,e1,e2,alllist):
for line in alllist:
csvw.writerow(line)
e2.set() #通知e2干活
e1.wait() #e1等待
def thread2(csvw,e2,e3,alllist):
for line in alllist:
e2.wait() # 等待干活
csvw.writerow(line)
e3.set() # 通知e3干活
def thread3(csvw,e3,e1,alllist):
for line in alllist:
e3.wait()
csvw.writerow(line)
e1.set()
#with open("1.csv","w",newline="") as datacsv:
csvw=csv.writer(open("xyz.csv","w",newline=""),dialect=("excel")) #最常用格式excel格式
e1 = threading.Event() # 事件
e2 = threading.Event() # 事件
e3 = threading.Event() # 事件
mylist1=getlist(r"D:\Python代码\class20\down\20201010\0600009.csv")
mylist2=getlist(r"D:\Python代码\class20\down\20201010\0600010.csv")
mylist3=getlist(r"D:\Python代码\class20\down\20201010\0600011.csv")
threading.Thread(target=thread1,args=(csvw,e1,e2,mylist1)).start()
threading.Thread(target=thread2,args=(csvw,e2,e3,mylist2)).start()
threading.Thread(target=thread3,args=(csvw,e3,e1,mylist3)).start()
csvw.writerow([])
运行效果:

8.多线程文件归并-交叉写入
import csv
import threading
#缓存,实时刷新
def getlist(path):
reader=csv.reader(open(path,"r")) #读取文件
alllist=[]
for item in reader:#读取每一行
alllist.append(item) #加入列表
return alllist
def getfilelist(path):
file=open(path,"rb")
alllist=file.readlines()
return alllist
def thread1(alllist,csvw,e1,e2):
for line in alllist:
csvw.write(line)
print(line.decode("utf-8", "ignore"))
e2.set() #通知e2干活
e1.wait(5) #e1等待
e1.clear()
def thread2(alllist,csvw,e2,e3):
for line in alllist:
e2.wait(5) # 等待干活
csvw.write(line)
print(line.decode("utf-8","ignore"))
e2.clear()
e3.set() # 通知e3干活
def thread3(alllist,csvw,e3,e1):
for line in alllist:
e3.wait(5)
csvw.write(line)
print(line.decode("utf-8", "ignore"))
e3.clear()
e1.set()
#with open("1.csv","w",newline="") as datacsv:
#csvw=csv.writer(open("xyz.csv","w",newline=""),dialect=("excel")) #最常用格式excel格式
file=open("xyz.txt",'wb')
e1 = threading.Event() # 事件
e2 = threading.Event() # 事件
e3 = threading.Event() # 事件
mylist1=getfilelist(r"D:\Python代码\class20\down\20201010\1.txt")
mylist2=getfilelist(r"D:\Python代码\class20\down\20201010\2.txt")
mylist3=getfilelist(r"D:\Python代码\class20\down\20201010\3.txt")
myth1=threading.Thread(target=thread1,args=(mylist1,file,e1,e2))
myth2=threading.Thread(target=thread2,args=(mylist2,file,e2,e3))
myth3=threading.Thread(target=thread3,args=(mylist3,file,e3,e1))
myth1.start()
myth2.start()
myth3.start()
myth1.join()
myth2.join()
myth3.join()
print("over")
file.close()
运行效果:
三种股票信息交叉写入

总结
芜湖!!!!!!
