前言导读
基本上cpu缓存知识是进入大厂的一个基本知识点了,而且也相当看重,这部分的知识掌握的比较好的话,会很加分的!
说下历史:
在计算的前几十年中,主内存非常慢且昂贵得令人难以置信,但是CPU也不是特别快。从1980年代开始,差距开始迅速扩大。微处理器的时钟速度飞速发展,但是内存访问时间的改善远没有那么明显。随着这种差距的扩大,越来越明显的是需要一种新型的快速存储器来弥合这种差距。
1980及以前:cpu没有cache
1980~1995: cpu开始有2级缓存
至今:有过L4,有些有L0,普遍有L1、L2、L3

图片
实战演练
CPU缓存基础知识
寄存器(Register)是中央处理器内用来暂存指令、数据和地址的电脑存储器。寄存器的存贮容量有限,读写速度非常快。在计算机体系结构里,寄存器存储在已知时间点所作计算的中间结果,通过快速地访问数据来加速计算机程序的运行。
寄存器位于存储器层次结构的最顶端,也是CPU可以读写的最快的存储器。寄存器通常都是以他们可以保存的比特数量来计量,举例来说,一个8位寄存器或32位寄存器。在中央处理器中,包含寄存器的部件有指令寄存器(IR)、程序计数器和累加器。寄存器现在都以寄存器数组的方式来实现,但是他们也可能使用单独的触发器、高速的核心存储器、薄膜存储器以及在数种机器上的其他方式来实现出来。
寄存器也可以指代由一个指令之输出或输入可以直接索引到的寄存器组群,这些寄存器的更确切的名称为“架构寄存器”。例如,x86指令集定义八个32位寄存器的集合,但一个实现x86指令集的CPU内部可能会有八个以上的寄存器。
CPU 缓存
在计算机系统中,CPU高速缓存(英语:CPU Cache,在本文中简称缓存)是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处理器的频率。
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。有效利用这种局部性,缓存可以达到极高的命中率。
在处理器看来,缓存是一个透明部件。因此,程序员通常无法直接干预对缓存的操作。但是,确实可以根据缓存的特点对程序代码实施特定优化,从而更好地利用缓存。
目前的计算机普遍都有3级缓存(L1、L2、L3),来看看结构:

图片
其中:
- L1缓分成两种,一种是指令缓存,一种是数据缓存。L2缓存和L3缓存不分指令和数据。
- L1和L2缓存在每一个CPU核中,L3则是所有CPU核心共享的内存。
- L1、L2、L3的越离CPU近就越小,速度也越快,越离CPU远,速度也越慢。
- 再往后面就是内存,内存的后面就是硬盘
再来看看它们的速度:

图片
看下我工作用的处理器吧,虽然有点垃圾~

图片
具体的信息我们可以看到:
L1的速度是主存的约27~36倍,L1、L2都是KB级别的,L3是M级别的,L1分为数据和指令缓存分别为32KB。想一想为什么没有L4?
下面来看一张图
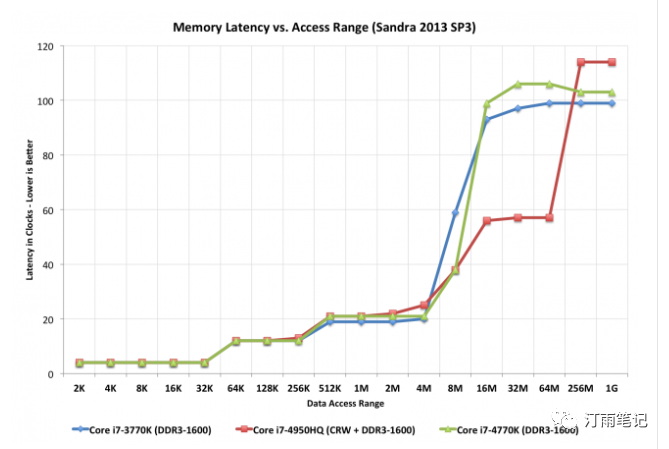
图片
来自Anandtech的Haswell评论的这张图表很有用,因为它说明了添加巨大的(128MB)L4缓存以及常规L1 / L2 / L3结构对性能的影响。每个阶梯代表一个新的缓存级别。红线是带有L4的芯片-请注意,对于大文件,它的速度仍然几乎是其他两块英特尔芯片的两倍。但是较大的缓存需要更多的晶体管既慢又昂贵,而且还要增加芯片的尺寸。
那有没有L0呢?
答案是:有的。现代CPU通常还具有非常小的“ L0”高速缓存,其大小通常只有几KB,用于存储微操作。AMD和Intel都使用这种缓存。Zen的缓存为2,048 µOP,而Zen 2的缓存为4,096 µOP。这些微小的缓存池在与L1和L2相同的通用原则下运行,但是代表的是甚至更小的内存池,CPU可以以比L1更低的延迟来访问它们。通常,公司会相互调整这些功能。Zen 1和Zen +(Ryzen 1xxx,2xxx,3xxx APU)具有一个64KB L1指令高速缓存,该指令高速缓存是4路关联的,并具有一个2,048 µOP L0高速缓存。Zen 2(Ryzen 3xxx台式机CPU,Ryzen Mobile 4xxx)具有一个32KB L1指令高速缓存,该指令高速缓存是8路关联的,并且具有4,096 µOP高速缓存。将设置的关联性和µOP缓存的大小加倍,可以使AMD将L1缓存的大小减少一半。
说了这么多,cpu缓存到底是怎么工作的嘛?
cpu缓存存在的目的:我cpu这么快,我每次去主存去取数据那代价也太大了,我就在我自己开辟一个内存池,来存我最想要的一些数据。那哪些数据可以被加载到cpu缓存道中来呢?复杂的计算和编程代码呗。
如果我在L1的内存池当中没有找到我想要的数据呢?就是缓存未命中
还能怎么办,去L2找呗,一些处理器使用包含性缓存设计(意味着存储在L1缓存中的数据也将在L2缓存中重复),而其他处理器则是互斥的(意味着两个缓存永不共享数据)。如果在L2高速缓存中找不到数据,则CPU会继续沿链条向下移动到L3(通常仍在裸片上),然后是L4(如果存在)和主内存(DRAM)。
又引出一个问题:怎么找才是比较高效的呢?cpu不可能挨着挨着遍历吧
CPU 缓存命中
cache line
缓存行也叫缓存块,就是说cpu加载数据是一块一块加载的。一般来说,一个cache line最小加载的数据是64Bytes=16个32位的整型(也有其他cpu32Bytes和128Bytes的),如下是我的计算机处理器的一条Cache line size.

图片
在上图我的处理器的L1的数据缓存有32KBytes:
32KBytes/64Bytes=512 Cache line
cacheline与内存之间的映射策略 :
-
Hash: (内存地址 % 缓存行) * 64 容易出现Hash冲突
-
N-Way Set Associative : 简单的说就是将N个cacheline分为一组,每个cacheline中,根据偏移进行寻址
从上图可以看出L1的数据缓存32KBytes分为了8-way,那么每一路就是4KBytes.
怎么寻址呢?
前面我们知道:大部分的Cache line一条为64Bytes
- Tag : 每条Cache line 前都会有一个独立分配的24bits=3Bytes来存的tag,也就是内存地址的前24bits.
- Index : 内存地址的后面的6bits=3/4Bytes存的是这一路(way)Cache line的索引,通过6bits我们可以索引2^6=64条Cache line。
- Offset : 在索引后面的6bits存的事Cache line的偏移量。
具体流程:
- 用索引定位到相应的缓存块。
- 用标签尝试匹配该缓存块的对应标签值。其结果为命中或未命中。
- 如命中,用块内偏移定位此块内的目标字。然后直接改写这个字。
- 如未命中,依系统设计不同可有两种处理策略,分别称为按写分配(Write allocate)和不按写分配(No-write allocate)。如果是按写分配,则先如处理读未命中一样,将未命中数据读入缓****存,然后再将数据写到被读入的字单元。如果是不按写分配,则直接将数据写回内存。
如果某一路的缓存写满了怎么办呢?
替换一些最晚访问的字节呗,也就是常说的LRU(最久未使用)
分析了L1的数据缓存,大家也可以照着分析其他L2、L3缓存,这里就不再分析了。
缓存一致性
部分来自维基百科:
为了和下级存储(如内存)保持数据一致性,就必须把数据更新适时传播下去。这种传播通过回写来完成。一般有两种回写策略:写回(Write back)和写通(Write through)。
根据回写策略和上面提到的未命中的分配策略,请看下表
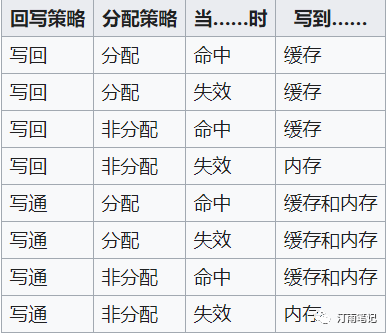
图片
通过上图,我们知道:
写回时:如果缓存命中,不用更新内存,为的就是减少内存写操作,通常分配策略是分配
-
怎么标记缓存在被其他cpu加载时被更新过?每个Cache line提供了一个脏位(dirty bit)来标识被加载后是否发生过更新。(cpu在加载时是一块一块加载的不是一个字节一个字节加载的,前面说过)
-

图片
写通:
-
写通是指,每当缓存接收到写数据指令,都直接将数据写回到内存。如果此数据地址也在缓存中,则必须同时更新缓存。由于这种设计会引发造成大量写内存操作,有必要设置一个缓冲来减少硬件冲突。这个缓冲称作写缓冲器(Write buffer),通常不超过4个缓存块大小。不过,出于同样的目的,写缓冲器也可以用于写回型缓存。
-
写通较写回易于实现,并且能更简单地维持数据一致性。
-
通常分配策略是非分配
对于一个两级缓存系统,一级缓存可能会使用写通来简化实现,而二级缓存使用写回确保数据一致性
MESI协议:
这里有一个网页(MESI Interactive Animations),这个地址太6x了,参考了很多资料,还是不如动画嗄。。。。https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm
建议先玩一玩上面网址的动图,可以了解下,各个cpu的缓存和主存的读、写数据。
这里简单阐述一下:我们主存有个x=0的值,处理器有两个cpu0,cpu1
-
cpu0读x的值,cpu0先在cpu0缓存找,找不到,有一个地址总线,就是路由cpu的和主存,同时去cpu和主存找,比较版本,去主存拿x,拿到x的值通过数据总线将值赋值cpu0的缓存
-

图片
-
cpu0对x+1写,直接获取cpu0的x=0,进行加1(这里不会更新主存,也不会更新cpu1的缓存,cpu1缓存还没有x的值)
-

图片
-
cpu1读x的值,首先在cpu1的缓存中找,找不到,根据地址总线,同时去cpu和主存找,比较版本(如果版本一样,会优先去主存的值),找到cpu0的x值,cpu0通过数据总线将数据优先更新cpu1的缓存x的值,在更新主存x的值
-

图片
-
cpu1对x+1,直接获取cpu1的x=1,进行加1(这里会更新主存,也不会更新cpu0的缓存,但是会通过RFO通知其他cpu
-

图片
其他情况可以自己去试一下。
通知协议:
Snoopy 协议。这种协议更像是一种数据通知的总线型的技术。CPU Cache通过这个协议可以识别其它Cache上的数据状态。如果有数据共享的话,可以通过广播机制将共享数据的状态通知给其它CPU Cache。这个协议要求每个CPU Cache 都可以“窥探”数据事件的通知并做出相应的反应。
MESI协议的状态:
Modified(已修改), Exclusive(独占的),Shared(共享的),Invalid(无效的)。
跟着动画走一遍,其实也不是很复杂。
扩展一下:
MOESI: MOESI是一个完整的缓存一致性协议,其中包含其他协议中常用的所有可能状态。除了四个常见的MESI协议状态外,还有第五个“拥有”状态,表示已修改和共享的数据。这样避免了在共享之前将修改后的数据写回主存储器的需要。尽管最终仍必须回写数据,但可以推迟回写。
MOESF: Forward状态下的数据是clean的,可以丢弃而不用另行通知
AMD用MOESI,Intel用MESIF
这里就不继续深入下去啦~
用例走一波
用例1:
public class CpuCache {
static int LEN = 64 * 1024 * 1024;
static int arr[] = new int[LEN]; // 64M
public static void main(String[] args) {
long currAddTwo = System.currentTimeMillis();
addTwo();
System.out.println(System.currentTimeMillis() - currAddTwo);
long currAddEight = System.currentTimeMillis();
addEight();
System.out.println(System.currentTimeMillis() - currAddEight);
}
private static void addTwo() {
for (int i = 0;i<LEN;i += 2) {
arr[i]*=i;
}
}
private static void addEight() {
for (int i = 0;i<LEN;i += 8) {
arr[i]*=i;
}
}
}
复制代码
大家可以猜一猜,打印出来的时间可能会相差多少,或者相差几倍
分析一下时间复杂度:addTwo如果4n,那么addEight就是n
但是别忘记了CPU加载时一个Cache line 64Bytes来加载的,所以他们无论加2还是加8他们的消耗的时间都是差不多的,我的机器耗时是:
48
36
复制代码
伪共享:
引用Martin的例子, 稍做修改,代码如下:
public class FalseShare implements Runnable {
public static int NUM_THREADS = 2; // change
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs;
public FalseShare(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
Thread.sleep(1000);
System.out.println("starting....");
if (args.length == 1) {
NUM_THREADS = Integer.parseInt(args[0]);
}
longs = new VolatileLong[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
final long start = System.currentTimeMillis();
runTest();
System.out.println("duration = " + (System.currentTimeMillis() - start));
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseShare(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
// System.out.println(t);
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong {
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6;//, p7, p8, p9;
}
}
复制代码
代码的逻辑是默认4个线程修改一数组不同元素的内容. 元素的类型是VolatileLong, 只有一个长整型成员value和6个没用到的长整型成员. value设为volatile是为了让value的修改所有线程都可见
当我线程设置为4时:第50行代码,有6个长整型,运行了13s,反而在只有4个长整型是只有9s,当注释掉第50行时,运行了24s。发现这个测试结果有点蹊跷。
先来梳理一下伪共享的定义:
在Java程序中,数组的成员在缓存中也是连续的. 其实从Java对象的相邻成员变量也会加载到同一缓存行中. 如果多个线程操作不同的成员变量, 如果是相同的缓存行, 伪共享(False Sharing)就可能发生。
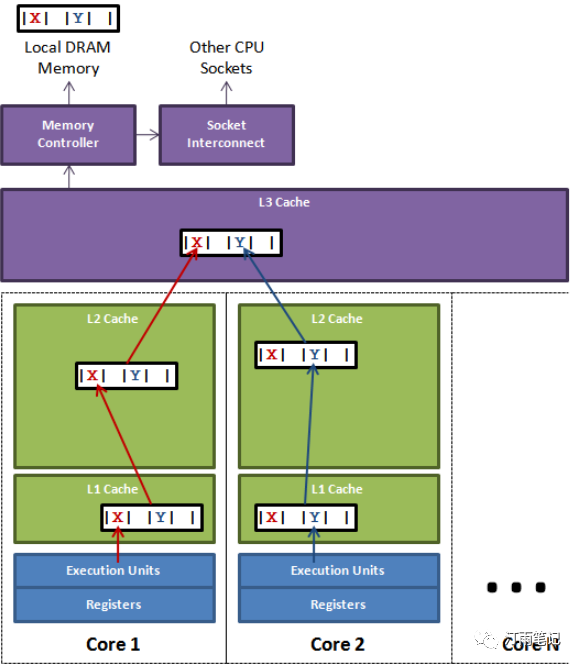
下面引用Disruptor项目(https://github.com/LMAX-Exchange/disruptor)Lead的博文(https://mechanical-sympathy.blogspot.com/2011/07/false-sharing.html)中的示例图和实验例子
图片
一个运行在处理器core 1上的线程想要更新变量X的值, 同时另外一个运行在处理器core 2上的线程想要更新变量Y的值. 但是, 这两个频繁改动的变量都处于同一条缓存行. 两个线程就会轮番发送RFO消息, 占得此缓存行的拥有权.
表面上X和Y都是被独立线程操作的, 而且两操作之间也没有任何关系.只不过它们共享了一个缓存行, 但所有竞争冲突都是来源于共享.
根据上面代码实例,简单的说,我们对数组操作时,一个对象8字节(32位系统)或12字节(64位系统),如果加了6个long整型=48个字节,这样就可以让不同对象都用一个缓存行,就可以避免缓存行频繁发送RFO消息共享缓存行,减少竞争,那为什么我们测试出来的数据有问题?当有6个long反而比4个long还消耗时间。
原因是咱们的机器是2核的,当线程设置为2时,6个long就变成了4s,注释掉第50行变成了10s.
这样通过缓存行填充(padding),让一个对象尽量用一个缓存行,减少缓存行的同步。
队列伪共享
在JDK的LinkedBlockingQueue中, 存在指向队列头的引用head和指向队列尾的引用last. 而这种队列经常在异步编程中使有,这两个引用的值经常的被不同的线程修改, 但它们却很可能在同一个缓存行, 于是就产生了伪共享. 线程越多, 核越多,对性能产生的负面效果就越大.
但是: 伪共享也不要为了优化而优化,在Grizzly中,自带了LinkedTransferQueue,和JDK 7自带的LinkedTransferQueue有所不同,不同之处就是使用PaddedAtomicReference来提升并发性能,其实这是一种错误的编码技巧,没有意义。
Netty之前使用了PaddedAtomicReference来代替原来的Node, 使用了补齐的办法解决了队列伪共享的问题,但是后来也取消了。
AtomicReference和LinkedTransferQueue的本质是乐观锁,乐观锁的在激烈竞争的时候性能都很糟糕,乐观锁应使用在非激烈竞争的场景,为乐观锁优化激烈竞争下的性能,是错误的方向,因为如果需要激烈竞争,就应该使用悲观锁。
Padded-AtomicReference也是一个伪命题,如果激励竞争,为什么不使用Lock + volatile,如果非激烈竞争,使用PaddedAtomicReference对于AtomicReference又没有优势。所以使用Padded-AtomicReference是一个错误的编码技巧。
所以在1.8去掉了LinkedTransferQueue相关的pad逻辑,贴一个1.7的代码吧--
public class FalseShare implements Runnable {
public static int NUM_THREADS = 2; // change
public final static long ITERATIONS = 500L * 1000L * 1000L;
private final int arrayIndex;
private static VolatileLong[] longs;
public FalseShare(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
Thread.sleep(1000);
System.out.println("starting....");
if (args.length == 1) {
NUM_THREADS = Integer.parseInt(args[0]);
}
longs = new VolatileLong[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new VolatileLong();
}
final long start = System.currentTimeMillis();
runTest();
System.out.println("duration = " + (System.currentTimeMillis() - start));
}
private static void runTest() throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseShare(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
// System.out.println(t);
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = i;
}
}
public final static class VolatileLong {
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6;//, p7, p8, p9;
}
}
复制代码
50个线程争抢10个对象,LinkedBlockingQueue比LinkedTransferQueue
在1.7是要快几倍的,但是在1.8运行速度就差不多了。
最后在讲讲Disruptor
- 环形数组结构
为了避免垃圾回收,采用数组而非链表。同时,数组对处理器的缓存机制更加友好。
- 元素位置定位
数组长度2^n,通过位运算,加快定位的速度。下标采取递增的形式。不用担心index溢出的问题。index是long类型,即使100万QPS的处理速度,也需要30万年才能用完。
- 无锁设计
每个生产者或者消费者线程,会先申请可以操作的元素在数组中的位置,申请到之后,直接在该位置写入或者读取数据。
下面忽略数组的环形结构,介绍一下如何实现无锁设计。整个过程通过原子变量CAS,保证操作的线程安全。
消费者等待策略:
- BlockingWaitStrategy:加锁 CPU资源紧缺,吞吐量和延迟并不重要的场景
- BusySpinWaitStrategy:自旋 通过不断重试,减少切换线程导致的系统调用,而降低延迟。推荐在线程绑定到固定的CPU的场景下使用
- PhasedBackoffWaitStrategy:自旋 + yield + 自定义策略,CPU资源紧缺,吞吐量和延迟并不重要的场景
- SleepingWaitStrategy:自旋 + yield + sleep,性能和CPU资源之间有很好的折中。延迟不均匀
- TimeoutBlockingWaitStrategy:加锁,有超时限制,CPU资源紧缺,吞吐量和延迟并不重要的场景(logfj2默认使用此策略)
- YieldingWaitStrategy:自旋 + yield + 自旋,性能和CPU资源之间有很好的折中。延迟比较均匀
import com.lmax.disruptor.*;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;
import java.util.concurrent.ThreadFactory;
public class DisruptorMain
{
public static void main(String[] args) throws Exception
{
// 队列中的元素
class Element {
private String value;
public String get(){
return value;
}
public void set(String value){
this.value= value;
}
}
// 生产者的线程工厂
ThreadFactory threadFactory = new ThreadFactory(){
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "simpleThread");
}
};
// RingBuffer生产工厂,初始化RingBuffer的时候使用
EventFactory<Element> factory = new EventFactory<Element>() {
@Override
public Element newInstance() {
return new Element();
}
};
// 处理Event的handler
EventHandler<Element> handler = new EventHandler<Element>(){
@Override
public void onEvent(Element element, long sequence, boolean endOfBatch)
{
System.out.println("Element: " + element.get());
}
};
// 阻塞策略
BlockingWaitStrategy strategy = new BlockingWaitStrategy();
// 指定RingBuffer的大小
int bufferSize = 16;
// 创建disruptor,采用单生产者模式
Disruptor<Element> disruptor = new Disruptor(factory, bufferSize, threadFactory, ProducerType.SINGLE, strategy);
// 设置EventHandler
disruptor.handleEventsWith(handler);
// 启动disruptor的线程
disruptor.start();
RingBuffer<Element> ringBuffer = disruptor.getRingBuffer();
for (int l = 0; true; l++)
{
// 获取下一个可用位置的下标
long sequence = ringBuffer.next();
try
{
// 返回可用位置的元素
Element event = ringBuffer.get(sequence);
// 设置该位置元素的值
event.set(l+"rs");
}
finally
{
System.out.println("push" + sequence);
ringBuffer.publish(sequence);
}
Thread.sleep(10);
}
}
}
复制代码
贴一下测试用例!等下一篇在深入讲解吧!下下一篇在讲讲Volatile,让我休息一下~~
作者:汀雨笔记
链接:https://juejin.cn/post/6932243675653095438
来源:掘金