贝叶斯-新闻分类
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
news = fetch_20newsgroups(subset='all')
print(news.target_names)
print(len(news.data))
print(len(news.target))

print(len(news.target_names))
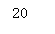
news.data[0]

print(news.target[0])
print(news.target_names[news.target[0]])

x_train,x_test,y_train,y_test = train_test_split(news.data,news.target)
# train = fetch_20newsgroups(subset='train')
# x_train = train.data
# y_train = train.target
# test = fetch_20newsgroups(subset='test')
# x_test = test.data
# y_test = test.target

from sklearn.feature_extraction.text import CountVectorizer
texts=["dog cat fish","dog cat cat","fish bird", 'bird']
cv = CountVectorizer()
cv_fit=cv.fit_transform(texts)
#
print(cv.get_feature_names())
print(cv_fit.toarray())
print(cv_fit.toarray().sum(axis=0))

from sklearn import model_selection
from sklearn.naive_bayes import MultinomialNB
cv = CountVectorizer()
cv_data = cv.fit_transform(x_train)
mul_nb = MultinomialNB()
scores = model_selection.cross_val_score(mul_nb, cv_data, y_train, cv=3, scoring='accuracy')
print("Accuracy: %0.3f" % (scores.mean()))

TfidfVectorizer使用了一个高级的计算方法,称为Term Frequency Inverse Document
Frequency (TF-IDF)。这是一个衡量一个词在文本或语料中重要性的统计方法。直觉上讲,该方法通过比较在整个语料库的词的频率,寻求在当前文档中频率较高的词。这是一种将结果进行标准化的方法,可以避免因为有些词出现太过频繁而对一个实例的特征化作用不大的情况(我猜测比如a和and在英语中出现的频率比较高,但是它们对于表征一个文本的作用没有什么作用)
from sklearn.feature_extraction.text import TfidfVectorizer
# 文本文档列表
text = ["The quick brown fox jumped over the lazy dog.",
"The dog.",
"The fox"]
# 创建变换函数
vectorizer = TfidfVectorizer()
# 词条化以及创建词汇表
vectorizer.fit(text)
# 总结
print(vectorizer.vocabulary_)
print(vectorizer.idf_)
# 编码文档
vector = vectorizer.transform([text[0]])
# 总结编码文档
print(vector.shape)
print(vector.toarray())

# 创建变换函数
vectorizer = TfidfVectorizer()
# 词条化以及创建词汇表
tfidf_train = vectorizer.fit_transform(x_train)
scores = model_selection.cross_val_score(mul_nb, tfidf_train, y_train, cv=3, scoring='accuracy')
print("Accuracy: %0.3f" % (scores.mean()))
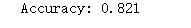
def get_stop_words():
result = set()
for line in open('stopwords_en.txt', 'r').readlines():
result.add(line.strip())
return result
# 加载停用词
stop_words = get_stop_words()
# 创建变换函数
vectorizer = TfidfVectorizer(stop_words=stop_words)
mul_nb = MultinomialNB(alpha=0.01)
# 词条化以及创建词汇表
tfidf_train = vectorizer.fit_transform(x_train)
scores = model_selection.cross_val_score(mul_nb, tfidf_train, y_train, cv=3, scoring='accuracy')
print("Accuracy: %0.3f" % (scores.mean()))

# 切分数据集
tfidf_data = vectorizer.fit_transform(news.data)
x_train,x_test,y_train,y_test = train_test_split(tfidf_data,news.target)
mul_nb.fit(x_train,y_train)
print(mul_nb.score(x_train, y_train))
print(mul_nb.score(x_test, y_test))
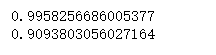
贝叶斯拼写检查器

拼写检查器原理
在所有正确的拼写词中, 我们想要找一个正确的词 c, 使得对于 w 的条件概率最大。求解:
P(c|w) -> P(w|c) P© / P(w)
比如:appla是条件w,apple和apply是正确的词c,对于apple和apply来说P(w)都是一样的,所以我们在上式中忽略它, 写成:
P(w|c) P©
P©, 文章中出现这个正确拼写的词 c 的概率, 也就是说, 在英语文章中, c 出现的概率有多大。
假设可以认为单词在文章中出现的概率越大,则正确拼写的概率就越大,可以用单词出现次数来代替这个量。好比说, 英语中出现 the 的概率 P(‘the’) 就相对高, 而出现 P(‘zxzxzxzyy’) 的概率接近0(假设后者也是一个词的话).
P(w|c), 在用户想键入 c 的情况下敲成 w 的概率。这个是代表用户会以多大的概率把 c 敲错成 w。
import re
# 读取内容
text = open('big.txt').read()
# 转小写,只保留a-z字符
text = re.findall('[a-z]+', text.lower())
dic_words = {
}
for t in text:
dic_words[t] = dic_words.get(t,0) + 1
dic_words

编辑距离:
两个词之间的编辑距离定义为使用了几次插入(在词中插入一个单字母), 删除(删除一个单字母), 交换(交换相邻两个字母), 替换(把一个字母换成另一个)的操作从一个词变到另一个词.
# 字母表
alphabet = 'abcdefghijklmnopqrstuvwxyz'
#返回所有与单词 word 编辑距离为 1 的集合
def edits1(word):
n = len(word)
return set([word[0:i]+word[i+1:] for i in range(n)] + # deletion
[word[0:i]+word[i+1]+word[i]+word[i+2:] for i in range(n-1)] + # transposition
[word[0:i]+c+word[i+1:] for i in range(n) for c in alphabet] + # alteration
[word[0:i]+c+word[i:] for i in range(n+1) for c in alphabet]) # insertion
apple = 'apple'
apple[0:0] + apple[1:]
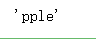

#返回所有与单词 word 编辑距离为 2 的集合
#在这些编辑距离小于2的词中间, 只把那些正确的词作为候选词
def edits2(word):
return set(e2 for e1 in edits1(word) for e2 in edits1(e1))
e1 = edits1('something')
e2 = edits2('something')
len(e1) + len(e2)

与 something 编辑距离为1或者2的单词居然达到了 114,818 个
优化:只把那些正确的词作为候选词,优化之后edits2只能返回 3 个单词: ‘smoothing’, ‘something’ 和 ‘soothing’
P(w|c)求解:正常来说把一个元音拼成另一个的概率要大于辅音 (因为人常常把 hello 打成 hallo 这样); 把单词的第一个字母拼错的概率会相对小, 等等。但是为了简单起见, 选择了一个简单的方法: 编辑距离为1的正确单词比编辑距离为2的优先级高, 而编辑距离为0的正确单词优先级比编辑距离为1的高.一般把hello打成hallo的可能性比把hello打成halo的可能性大。
def known(words):
w = set()
for word in words:
if word in dic_words:
w.add(word)
return w
# 先计算编辑距离,再根据编辑距离找到最匹配的单词
def correct(word):
# 获取候选单词
#如果known(set)非空, candidates 就会选取这个集合, 而不继续计算后面的
candidates = known([word]) or known(edits1(word)) or known(edits2(word)) or word
# 字典中不存在相近的词
if word == candidates:
return word
# 返回频率最高的词
max_num = 0
for c in candcidates:
if dic_words[c] >= max_num:
max_num = dic_words[c]
candidate = c
return candidate
