核心概念
在我们引用了Sharding-JDBC之后让我们对数据库的操作看起来就像是透明的,即使表变成了三个数据库里面的三张表,我们应用端在使用的时候就跟操作一张表是一样的感觉.也就是说Mybatis的Mapper映射器里面的SQL语句是不需要修改的.
即使你的真实表的表名变化了也能自动根据逻辑表的名字去生成真实表的名字,比如说你是根据月份分片的,你的真实表带个日期,我们应用在使用的时候依然只需要逻辑表的原名就行,Sharing-JDBC会自动组装出来真实表的表名.
1.逻辑表
水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。
2.真实表
在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。
比如说一张用户表我给它分成了三个数据库,每个数据库的用户表都是一个真实的表
3.数据节点
数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。
一个数据库里面的一张表就是一个数据节点
4.绑定表
指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
5.分片键

是我们用来做数据分片的一个依据,比如说我如果要取模的话我用用户的主键去取模,那么user_id就是分片键,如果我要是对日期去做日期范围的划分的话,那么日期就是分片键等等.
6.动态表

名字有可能会发生变化的
Sharding-JDBC可以实现不分库的分表,在一个数据库里面生成很多表名,当然也可以又分库又分表.
在应用中使用的是一个逻辑表t_order ,
7.广播表

有一些数据会被各个业务系统所使用到,可能会产生多个跨库关联查询的需求,广播表满足了两个条件:
1. 数据量不大
2. 更新很少
给所有的数据库或者所有的业务系统都去放一份儿相同的数据,这样就不用依赖于一个核心的数据
这种基础数据,或者字典数据表就可以设置为广播表.
广播表是一种冗余的思想,也是解决了跨库关联查询,避免跨库查询的一种重要的手段.
8.绑定表
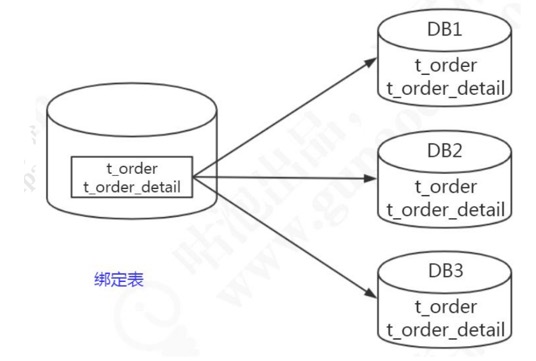
比如说orde表和order_detail表是有逻辑的主外键关系的 比如说order_detail表里面有个order_id 会和order表的id做对应关系,如果两个表在不同的DataNode的话,那么是没有办法实现关联查询的.