手写代码主要原因就是为了面试,可以不用把所有的分类模型手写一遍,写个10个左右就差不多了,之后再手写一两个检测代码分割代码,差不多就对整体有个概念了.
完整代码在我github上面
GoogLeNet主要有inceveption块组成,GoogLeNet跟VGG一样,在主体卷积部分中使用5个模块(block),每个模块之间使用步幅为2的3×3最大池化层来减小输出高宽,其基本inception块如下图所示:
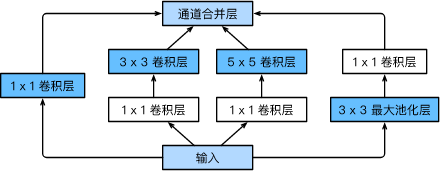
inception主要由4条并行路线组成,前三条路线主要用来提取不同不同尺寸下信息,中间两个路径为了减小模型参数,所以输出通道数小
这个部分对应的代码为:(代码很简单)
class Inception(nn.Module):
def __init__(self, in_c, out_1, out_2, out_3, out_4):
super(Inception, self).__init__()#子类继承父类时,重写init函数要调用suoer()方法
self.p_1 = nn.Conv2d(in_c, out_1, kernel_size=1)#padding默认为0,stride默认为1,这里所以没写
self.p_21 = nn.Conv2d(in_c, out_2[0], kernel_size=1)
self.p_22 = nn.Conv2d(out_2[0], out_2[1], kernel_size=3, padding=1)#注意padding
self.p_31 = nn.Conv2d(in_c, out_3[0], kernel_size=1)
self.p_32 = nn.Conv2d(out_3[0], out_3[1], kernel_size=5, padding=2)#注意padding
self.p_41 = nn.MaxPool2d(kernel_size=3, padding=1, stride=1)#这里写参数stride=1,是因为源码中maxpool2d的stride默认为None
self.p_42 = nn.Conv2d(in_c, out_4, kernel_size=1)
def forword(self, x):
p1 = F.relu(self.p_1(x))#因为当时还没有提出bn,所以这里没有bn
p2 = F.relu(self.p_22(F.relu(self.p_21(x))))
p3 = F.relu(self.p_32(F.relu(self.p_31(x))))
p4 = F.relu(self.p_42(F.relu(self.p_41(x))))
return torch.cat((p1, p2, p3, p4), dim=1)
然后先定义2个类,一个是全局平均池化,全局平均池化接在最后一个block后面;一个是展平操作,用来将全局平均池化后的tensor进行展平,以连接全连接层
#这和是b5最后接的全局平均池化层,将hxw的特征图变为1x1
class GlobalAvgPool2d(nn.Module):
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
#这里是将最后得到的(b,c,1,1)的特征图展平,和全连接层进行连接
class FlattenLayer(nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x):
return x.view(x.shape[0], -1)
最后就是完整的网络代码
#GoogLeNet和VGG一样,有5个block块,每个block块由步幅为2的3x3最大池化层减小输出宽度
b1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride= 2, padding=3),
nn.ReLU(), ##这里用到了nn.ReLU,前面定义inception块时用了F.relu,其实没啥差别
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
b2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=1),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
#前2个模块为普通的卷积,从第三个模块开始引入了inception块
b3 = nn.Sequential(
Inception(192, 64, [96, 128], [16, 32], 32),
Inception(256, 128, [128, 192], [32, 96], 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
b4 = nn.Sequential(
Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
b5 = nn.Sequential(
Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
GlobalAvgPool2d()
)
net = nn.Sequential(b1, b2, b3, b4, b5, FlattenLayer(), nn.Linear(1024, 10))
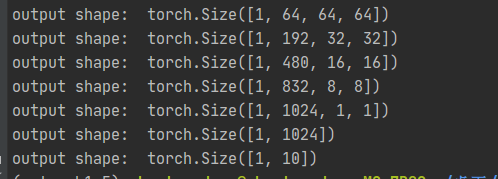
输出看一下每层的结果:
X = torch.rand(1, 3, 256, 256)
for blk in net.children():
X = blk(X)
print('output shape: ', X.shape)
好的,到这里GoogLeNet就写完了,明天就写一下resnet