使用到的工具:
CentOS7、VMare12虚拟机、hadoop-2.6.4、SecureCRT(远程连接虚拟机)、WinSCP(实现本机和虚拟机安装的CentOS7的文件互传)
安装好一个CentOS之后,使用克隆的方法在生产第二个、第三个系统。
从这里开始已经安装好了Centos7.
1. 修改系统名字,及三个系统的ip和名字的映射。
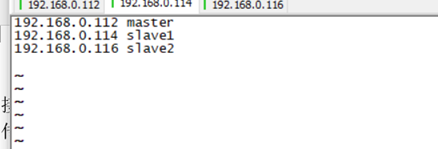
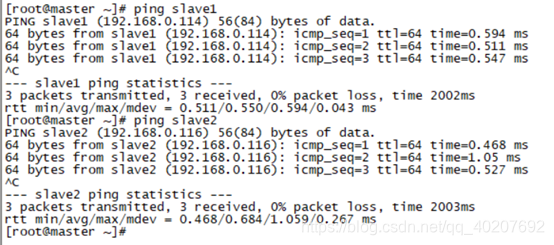
2. ping一下,看上面的修改生效没?
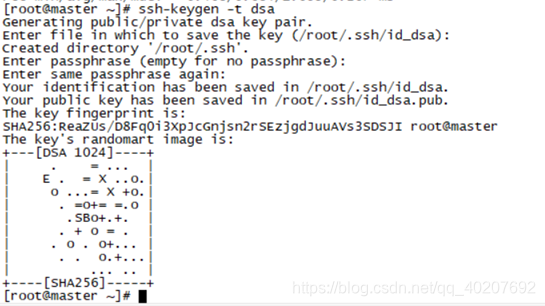
3. SSH实现三台机子的免密码登陆
ssh-keygen -t dsa
在命令执行过程中敲击两遍回车,然后在/root/.ssh文件下生成id_dsa id_dsa.pub,在该文件下建立一个authorized_keys文件,将id_dsa.pub文件内容拷贝到authorized_keys文件中
另外两个虚拟机也执行 #ssh-keygen -t dsa操作,并分别将id_dsa.pub内容拷贝到第一台虚拟机的authorized_keys文件中。将第一台的authorized_keys文件拷贝到另外两台虚拟机的/root/.ssh/ 下面。 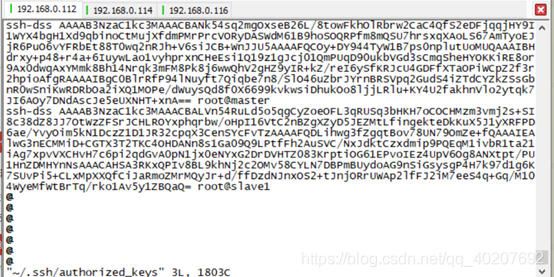
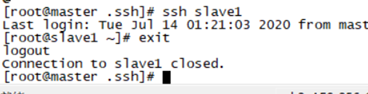
通过命令# ssh slave1 看是否可以免密互登。通过命令exit退出。
4. 给3台机器安装java环境
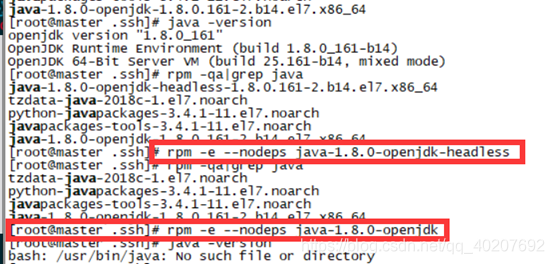
① 查看并卸载自带的jdk
rpm -qa|grep java

② 卸载自带的jdk
③ 安装jdk1.8
将jdk-8u191-linux-x64.tar.gz 上传至 /app目录下。

解压
tar -xvf jdk-8u191-linux-x64.tar.gz
将 解压后的文件夹移动到 /usr/local/ 下
mv jdk1.8.0_191 /usr/local/
配置环境变量
vim /etc/profile
加入

环境变量生效:
source /etc/profile
查看java
java -version

5. 安装hadoop和上面相同将hadoop使用WinSCP先上传到master,在master安装hadoop最后将安装好的文件传给其他机子。
(1)在opt目录下新建一个名为hadoop的目录,并将下载得到的hadoop-2.4.6.tar.gz解压到该目录。
(2)新建几个目录
在/root目录下新建几个目录,复制粘贴执行下面的命令:
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data
(3)修改etc/hadoop中的一系列配置文件
/opt/hadoop/hadoop-3.2.0/etc/hadoop/
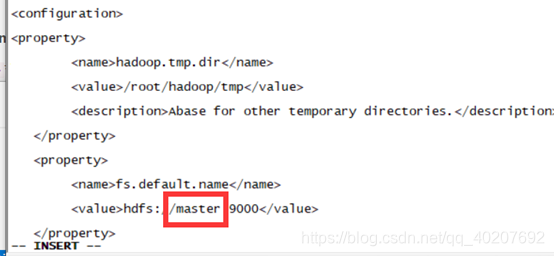
① 修改core-site.xml
在节点内加入配置:

<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
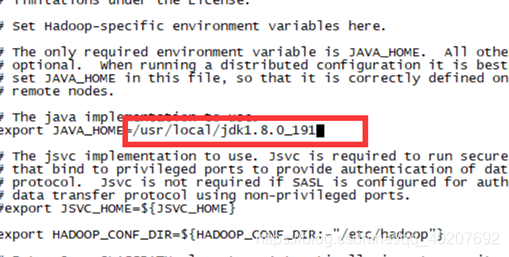
② 修改hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME}
修改为:
export JAVA_HOME=/usr/local/jdk1.8.0_191(实际情况)
③ 修改hdfs-site.xml
在节点内加入配置:
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
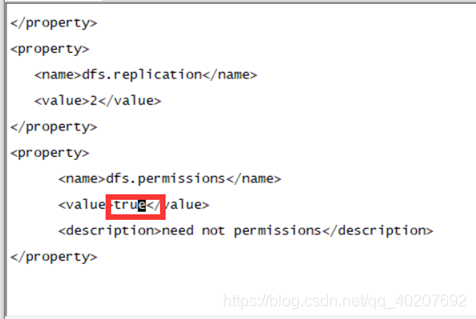
<property>
<name>dfs.permissions</name>
<value>ture</value>
<description>need not permissions</description>
</property>
④ 修改mapred-site.xml. template
在节点内加入配置:
<property>
<name>mapred.job.tracker</name>
<value>maaster:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
⑤ 修改yarn-site.xml文件
在节点内加入配置
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${
yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${
yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${
yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${
yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${
yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${
yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
⑥ 另外两台重复上述步骤,或者直接复制过去
scp -r /opt/Hadoop slave1:/opt
scp -r /opt/Hadoop slave2:/opt
⑦ 启动Hadoop
因为master是namenode,slave1和slave2都是datanode,所以只需要对master进行初始化操作,也就是对hdfs进行格式化。
1) 进入到master这台机器的/opt/hadoop/hadoop-2.6.4/bin目录,也就是执行命令:
cd /opt/hadoop/hadoop-2.6.4/bin
2) 执行初始化脚本,也就是执行命令:
./hadoop namenode -format
3) 等几秒没报错就是执行成功,格式化成功后,可以在看到在/root/hadoop/dfs/name/目录多了一个current目录,而且该目录内有一系列文件。

4) 在namenode上执行启动命令
因为master是namenode,slave1和slave2都是datanode,所以只需要再master上执行启动命令即可。
进入到master这台机器的/opt/hadoop/hadoop-2.6.4/sbin目录
执行初始化脚本,也就是执行命令:
./start-all.sh
第一次执行上面的启动命令,会需要我们进行交互操作,在问答界面上输入yes回车。
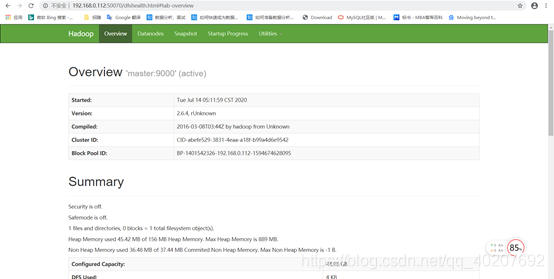
5) 在本地电脑访问如下地址:
http://192.168.0.112:50070/
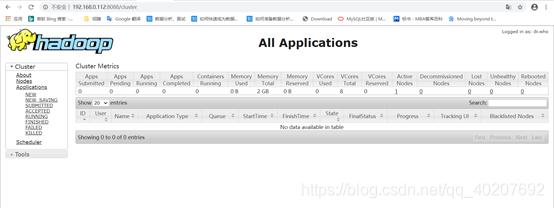
http://192.168.0.112:8088/
结束后一定要./stop-all.sh