3.1.4 YARN资源调度、Apache Hadoop 核心源码剖析
文章目录
七、YARN资源调度
7.1 Yarn架构

- ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
- NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
- ApplicationMaster(am):数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
- Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
7.2 Yarn任务提交(工作机制)

- 作业提交过程之YARN
一、作业提交
第1步:Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。
第2步:Client向RM申请一个作业id。
第3步:RM给Client返回该job资源的提交路径和作业id。
第4步:Client提交jar包、切片信息和配置文件到指定的资源提交路径。
第5步:Client提交完资源后,向RM申请运行MrAppMaster。
二、作业初始化
第6步:当RM收到Client的请求后,将该job添加到容量调度器中。
第7步:某一个空闲的NM领取到该Job。
第8步:该NM创建Container,并产生MRAppmaster。
第9步:下载Client提交的资源到本地。
三、任务分配
第10步:MrAppMaster向RM申请运行多个MapTask任务资源。
第11步:RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
四、任务运行
第12步:MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager
分别启动MapTask,MapTask对数据分区排序。
第13步:MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
第14步:ReduceTask向MapTask获取相应分区的数据。
第15步:程序运行完毕后,MR会向RM申请注销自己。
五、进度和状态更新
YARN中的任务将其进度和状态返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
六、作业完成
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
7.3 Yarn调度策略
Hadoop作业调度器主要有三种:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop2.9.2默认的资源调度器是Capacity Scheduler。
可以查看yarn-default.xml

- FIFO(先进先出调度器)

- 容量调度器(Capacity Scheduler 默认的调度器)
Apache Hadoop默认使用的调度策略。Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。

- Fair Scheduler(公平调度器,CDH版本的hadoop默认使用的调度器)
Fair调度器的设计目标是为所有的应用分配公平的资源(对公平的定义可以通过参数来设置)。公平调度在也可以在多个队列间工作。举个例子,假设有两个用户A和B,他们分别拥有一个队列。
当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会用于四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享
7.4Yarn多租户资源隔离配置
Yarn集群资源设置为A,B两个队列,
- A队列设置占用资源70%主要用来运行常规的定时任务,
- B队列设置占用资源30%主要运行临时任务,
- 两个队列间可相互资源共享,假如A队列资源占满,B队列资源比较充裕,A队列可以使用B队列的资源,使总体做到资源利用最大化.
选择使用Fair Scheduler调度策略!!
具体配置
- yarn-site.xml
<!-- 指定我们的任务调度使用fairScheduler的调度方式 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>In case you do not want to use the defaultscheduler</description>
</property>
- 创建fair-scheduler.xml文件
在Hadoop安装目录/etc/hadoop创建该文件
<?xml version="1.0" encoding="utf-8"?>
<allocations>
<defaultQueueSchedulingPolicy>fair</defaultQueueSchedulingPolicy>
<queue name="root">
<queue name="default">
<aclAdministerApps>*</aclAdministerApps>
<aclSubmitApps>*</aclSubmitApps>
<maxResources>9216 mb,4 vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<minResources>1024 mb,1vcores</minResources>
<minSharePreemptionTimeout>1000</minSharePreemptionTimeout>
<schedulingPolicy>fair</schedulingPolicy>
<weight>7</weight>
</queue>
<queue name="queue1">
<aclAdministerApps>*</aclAdministerApps>
<aclSubmitApps>*</aclSubmitApps>
<maxResources>4096 mb,4vcores</maxResources>
<maxRunningApps>5</maxRunningApps>
<minResources>1024 mb, 1vcores</minResources>
<minSharePreemptionTimeout>1000</minSharePreemptionTimeout>
<schedulingPolicy>fair</schedulingPolicy>
<weight>3</weight>
</queue>
</queue>
<queuePlacementPolicy>
<rule create="false" name="specified"/>
<rule create="true" name="default"/>
</queuePlacementPolicy>
</allocations>
界面验证

八、Apache Hadoop 核心源码剖析
8.1 源码阅读准备
- 下载Apache Hadoop-2.9.2官方源码
- 将源码导入idea中








8.2 NameNode 启动流程
命令启动Hdfs集群
start-dfs.sh
该命令会启动Hdfs的NameNode以及DataNode,启动NameNode主要是通过org.apache.hadoop.hdfs.server.namenode.NameNode类。
我们重点关注NameNode在启动过程中做了哪些工作(偏离主线的技术细节不深究)
对于分析启动流程主要关注两部分代码:








namenode的主要责任是文件元信息与数据块映射的管理。相应的,namenode的启动流程需要关注与客户端、datanode通信的工作线程,文件元信息的管理机制,数据块的管理机制等。其中,RpcServer主要负责与客户端、datanode通信,FSDirectory主要负责管理文件元信息。
8.3 DataNode 启动流程
datanode的Main Class是DataNode,先找到DataNode.main()









8.4 NameNode如何支撑高并发访问(双缓冲机制)
高并发访问NameNode会遇到什么样的问题:
经过学习HDFS的元数据管理机制,Client每次请求NameNode修改一条元数据(比如说申请上传一个文件,都要写一条edits log,包括两个步骤:
- 写入本地磁盘–edits文件
- 通过网络传输给JournalNodes集群(Hadoop HA集群–结合zookeeper来学习)。
高并发的难点主要在于数据的多线程安全以及每个操作效率!!
对于多线程安全:
NameNode在写edits log时几个原则: - 写入数据到edits_log必须保证每条edits都有一个全局顺序递增的transactionId(简称为txid),这样才可以标识出来一条一条的edits的先后顺序。
- 如果要保证每条edits的txid都是递增的,就必须得加同步锁。也就是每个线程修改了元数据,要写一条edits 的时候,都必须按顺序排队获取锁后,才能生成一个递增的txid,代表这次要写的edits的序号。
产生的问题:
如果每次都是在一个加锁的代码块里,生成txid,然后写磁盘文件edits log,这种既有同步锁又有写磁盘操作非常耗时!!
HDFS优化解决方案
问题产生的原因主要是在于,写edits时串行化排队生成自增txid + 写磁盘操作费时,HDFS的解决方案- 串行化:使用分段锁
- 写磁盘:使用双缓冲
分段加锁机制
首先各个线程依次第一次获取锁,生成顺序递增的txid,然后将edits写入内存双缓冲的区域1,接着就立马第一次释放锁了。趁着这个空隙,后面的线程就可以再次立马第一次获取锁,然后立即写自己的
edits到内存缓冲。
双缓冲机制
程序中将会开辟两份一模一样的内存空间,一个为bufCurrent,产生的数据会直接写入到这个bufCurrent,而另一个叫bufReady,在bufCurrent数据写入(达到一定标准)后,两片内存就会exchange(交换)。直接交换双缓冲的区域1和区域2。保证接收客户端写入数据请求的都是操作内存而不是同步写磁盘。

双缓冲源码分析 找到FsEditLog.java

扩展 Hadoop 3.x 新特性概述
Hadoop3.x中增强了很多特性,在Hadoop3.x中,不再允许使用jdk1.7,要求jdk1.8以上版本。这是因为Hadoop 2.0是基于JDK 1.7开发的,而JDK 1.7在2015年4月已停止更新,这直接迫使Hadoop社区基于JDK 1.8重新发布一个新的Hadoop版本,而这正是Hadoop3.x。Hadoop3.x以后将会调整方案架构,将Mapreduce 基于内存+io+磁盘,共同处理数据。
Hadoop 3.x中引入了一些重要的功能和优化,包括HDFS 可擦除编码、多Namenode支持、MR NativeTask优化、YARN基于cgroup的内存和磁盘IO隔离、YARN container resizing等。
Hadoop3.x官方文档地址如下:
http://hadoop.apache.org/docs/r3.0.1/
第一节 Hadoop3.x新特性之Common改进

关于这两个特性的官方文档地址:
http://hadoop.apache.org/docs/r3.0.1/hadoop-project-dist/hadoop-
hdfs/HDFSErasureCoding.html
http://hadoop.apache.org/docs/r3.0.1/hadoop-project-dist/hadoop-
hdfs/HDFSHighAvailabilityWithQJM.html
第二节 Hadoop3.x新特性之YARN改进
- 基于cgroup的内存隔离和IO Disk隔离(https://issues.apache.org/jira/browse/YARN-2619)
- 用curator实现RM leader选举(https://issues.apache.org/jira/browse/YARN-4438)
- containerresizing(https://issues.apache.org/jira/browse/YARN-1197)
- Timelineserver next generation (https://issues.apache.org/jira/browse/YARN-2928)
官方文档地址:
http://hadoop.apache.org/docs/r3.0.1/hadoop-yarn/hadoop-yarn-
site/TimelineServiceV2.html
第三节 Hadoop3.x新特性之MapReduce改进
- Tasknative优化。为MapReduce增加了C/C++的map output collector实现(包括Spill,Sort和IFile等),通过作业级别参数调整就可切换到该实现上。对于shuffle密集型应用,其性能可提高
约30%。(https://issues.apache.org/jira/browse/MAPREDUCE-2841) - MapReduce内存参数自动推断。在Hadoop 2.0中,为MapReduce作业设置内存参数非常繁琐,涉及到两个参数:mapreduce。{map,reduce}.memory.mb和mapreduce.{map,reduce}.java.opts,一旦设置不合理,则会使得内存资源浪费严重,比如将前者设置为4096MB,但后者却是“-Xmx2g”,则剩余2g实际上无法让java heap使用到。(https://issues.apache.org/jira/browse/MAPREDUCE-5785)
Hadoop3.x新特性之其他 - 添加新的 hadoop-client-api 和 hadoop-client-runtime 组件到一个单独的jar包里,以此解决依赖不兼容的问题。 (https://issues.apache.org/jira/browse/HADOOP-11804)
- 支持微软的Azure分布式文件系统和阿里的aliyun分布式文件系统
九、调优及二次开发示例
9.1 Job执行三原则
- 充分利用集群资源
- reduce阶段尽量放在一轮
- 每个task的执行时间要合理
9.1.1 原则一 充分利用集群资源
Job运行时,尽量让所有的节点都有任务处理,这样能尽量保证集群资源被充分利用,任务的并发度达到最大。可以通过调整处理的数据量大小,以及调整map和reduce个数来实现。
- Reduce个数的控制使用“mapreduce.job.reduces”
- Map个数取决于使用了哪种InputFormat,默认的TextFileInputFormat将根据block的个数来分配map数(一个block一个map)。
9.1.2 原则二 ReduceTask并发调整
努力避免出现以下场景

9.1.3 原则三 Task执行时间要合理
一个job中,每个MapTask或ReduceTask的执行时间只有几秒钟,这就意味着这个job的大部分时间都消耗在task的调度和进程启停上了,因此可以考虑增加每个task处理的数据大小。建议一个task处理时间为1分钟。
9.2 Shuffle调优
Shuffle阶段是MapReduce性能的关键部分,包括了从MapTaskask将中间数据写到磁盘一直到ReduceTask拷贝数据并最终放到Reduce函数的全部过程。这一块Hadoop提供了大量的调优参数。

9.2.1 Map阶段
- 判断Map内存使用
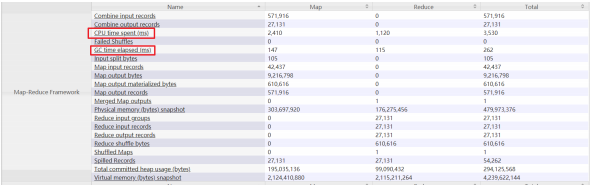
判断Map分配的内存是否够用,可以查看运行完成的job的Counters中(历史服务器),对应的task是否发生过多次GC,以及GC时间占总task运行时间之比。通常,GC时间不应超过task运行时间的10%, 即GC time elapsed (ms)/CPU time spent (ms)<10%。
Map需要的内存还需要随着环形缓冲区的调大而对应调整。可以通过如下参数进行调整。
mapreduce.map.memory.mb
Ma需要的CPU核数可以通过如下参数调整
mapreduce.map.cpu.vcores

可以看到内存默认是1G,CPU默认是1核。
如果集群资源充足建议调整:
mapreduce.map.memory.mb=3G(默认1G)mapreduce.map.cpu.vcores=1(默认也是1)
- 环形缓冲区

- Combiner

9.2.2 Copy阶段
- 对Map的中间结果进行压缩,当数据量大时,会显著减少网络传输的数据量,
- 但是也因为多了压缩和解压,带来了更多的CPU消耗。因此需要做好权衡。当任务属于网络瓶颈类型时,压缩Map中间结果效果明显。
- 在实际经验中Hadoop的运行的瓶颈一般都是IO而不是CPU,压缩一般可以10倍的减少IO操作
9.2.3 Reduce阶段
1、Reduce资源
每个Reduce资源
mapreduce.reduce.memory.mb=5G(默认1G) mapreduce.reduce.cpu.vcores=1(默认为1)。
2、Copy
ReduceTask在copy的过程中默认使用5(mapreduce.reduce.shuffle.parallelcopies参数控制)个
并行度进行复制数据。
该值在实际服务器上比较小,建议调整为50-100.
3、溢写归并
Copy过来的数据会先放入内存缓冲区中,然后当使用内存达到一定量的时候spill磁盘。这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置。这个内存大小的控制是通过mapreduce.reduce.shuffle.input.buffer.percent(default 0.7)控制的。
shuffile在reduce内存中的数据最多使用内存量为:0.7 × maxHeap of reduce task,内存到磁盘merge的启动可以通过mapreduce.reduce.shuffle.merge.percent(default0.66)配置。
copy完成后,reduce进入归并排序阶段,合并因子默认为10(mapreduce.task.io.sort.factor参数控制),如果map输出很多,则需要合并很多趟,所以可以提高此参数来减少合并次数。

9.3 Job调优
9.3.1 推测执行
集群规模很大时(几百上千台节点的集群),个别机器出现软硬件故障的概率就变大了,并且会因此延长整个任务的执行时间推测执行通过将一个task分给多台机器跑,取先运行完的那个,会很好的解决这个问题。对于小集群,可以将这个功能关闭。

建议:
- 大型集群建议开启,小集群建议关闭!
- 集群的推测执行都是关闭的。在需要推测执行的作业执行的时候开启
9.3.2 Slow Start
MapReduce的AM在申请资源的时候,会一次性申请所有的Map资源,延后申请reduce的资源,这样就能达到先执行完大部分Map再执行Reduce的目的。
mapreduce.job.reduce.slowstart.completedmaps
当多少占比的Map执行完后开始执行Reduce。默认5%的Map跑完后开始起Reduce。
如果想要Map完全结束后执行Reduce调整该值为1
9.3.3 小文件优化

9.3.4 数据倾斜

9.4 YARN调优
9.4.1 NM配置
- 可用内存
刨除分配给操作系统、其他服务的内存外,剩余的资源应尽量分配给YARN。
默认情况下,Map或Reduce container会使用1个虚拟CPU内核和1024MB内存,ApplicationMaster使用1536MB内存。
yarn.nodemanager.resource.memory-mb 默认是8192
- CPU虚拟核数
建议将此配置设定在逻辑核数的1.5~2倍之间。如果CPU的计算能力要求不高,可以配置为2倍的逻辑CPU。
yarn.nodemanager.resource.cpu-vcores
该节点上YARN可使用的虚拟CPU个数,默认是8。
目前推荐将该值设值为逻辑CPU核数的1.5~2倍之间
9.4.2 Container启动模式
YARN的NodeManager提供2种Container的启动模式。
默认,YARN为每一个Container启动一个JVM,JVM进程间不能实现资源共享,导致资源本地化的时间开销较大。针对启动时间较长的问题,新增了基于线程资源本地化启动模式,能够有效提升container
启动效率。
yarn.nodemanager.container-executor.class

9.4.3 AM调优
运行的一个大任务,map总数达到了上万的规模,任务失败,发现是ApplicationMaster(以下简称AM)反应缓慢,最终超时失败。
失败原因是Task数量变多时,AM管理的对象也线性增长,因此就需要更多的内存来管理。AM默认分配的内存大小是1.5GB。
建议:
任务数量多时增大AM内存
yarn.app.mapreduce.am.resource.mb
9.5 Namenode Full GC
JVM堆内存

- JVM内存划分为堆内存和非堆内存,堆内存分为年轻代(Young Generation)、老年代(OldGeneration),非堆内存就一个永久代(Permanent Generation)。
- 年轻代又分为Eden和Survivor区。Survivor区由FromSpace和ToSpace组成。Eden区占大容量,Survivor两个区占小容量,默认比例是8:1:1。
- 堆内存用途:存放的是对象,垃圾收集器就是收集这些对象,然后根据GC算法回收。
- 非堆内存用途:永久代,也称为方法区,存储程序运行时长期存活的对象,比如类的元数据、方法、常量、属性等。
补充:
JDK1.8版本废弃了永久代,替代的是元空间(MetaSpace),元空间与永久代上类似,都是方法区的实现,他们最大区别是:元空间并不在JVM中,而是使用本地内存。
1. 对象分代

2. Jstat
查看当前jvm内存使用以及垃圾回收情况

结果解释:


开启HDFS GC详细日志输出
编辑hadoop-env.sh
export HADOOP_LOG_DIR=/hadoop/logs/
增加JMX配置打印详细GC信息
指定一个日志输出目录;注释掉之前的ops
增加新的打印配置
#JMX配置
export HADOOP_JMX_OPTS="-Dcom.sun.management.jmxremote.authenticate=false - Dcom.sun.management.jmxremote.ssl=false"
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:- INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export NAMENODE_OPTS="-verbose:gc -XX:+PrintGCDetails - Xloggc:${HADOOP_LOG_DIR}/logs/hadoop-gc.log \ -XX:+PrintGCDateStamps -XX:+PrintGCApplicationConcurrentTime - XX:+PrintGCApplicationStoppedTime \ -server -Xms150g -Xmx150g -Xmn20g -XX:SurvivorRatio=8 - XX:MaxTenuringThreshold=15 \ -XX:ParallelGCThreads=18 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC - XX:+UseCMSCompactAtFullCollection -XX:+DisableExplicitGC - XX:+CMSParallelRemarkEnabled \ -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=70 - XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly - XX:CMSMaxAbortablePrecleanTime=5000 \ -XX:+UseGCLogFileRotation -XX:GCLogFileSize=20m - XX:ErrorFile=${HADOOP_LOG_DIR}/logs/hs_err.log.%p - XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${HADOOP_LOG_DIR}/logs/%p.hprof \"
export DATENODE_OPTS="-verbose:gc -XX:+PrintGCDetails - Xloggc:${HADOOP_LOG_DIR}/hadoop-gc.log \-XX:+PrintGCDateStamps -XX:+PrintGCApplicationConcurrentTime - XX:+PrintGCApplicationStoppedTime \ -server -Xms15g -Xmx15g -Xmn4g -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=15 \-XX:ParallelGCThreads=18 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC - XX:+UseCMSCompactAtFullCollection -XX:+DisableExplicitGC - XX:+CMSParallelRemarkEnabled \ -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=70 - XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly - XX:CMSMaxAbortablePrecleanTime=5000 \ -XX:+UseGCLogFileRotation -XX:GCLogFileSize=20m - XX:ErrorFile=${HADOOP_LOG_DIR}/logs/hs_err.log.%p - XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${HADOOP_LOG_DIR}/logs/%p.hprof \"
export HADOOP_NAMENODE_OPTS="$NAMENODE_OPTS $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="$DATENODE_OPTS $HADOOP_DATANODE_OPTS"
- -Xms150g -Xmx150g :堆内存大小最大和最小都是150g
- -Xmn20g :新生代大小为20g,等于eden+2*survivor,意味着老年代为150-20=130g。
- -XX:SurvivorRatio=8 :Eden和Survivor的大小比值为8,意味着两个Survivor区和一个Eden区的比值为2:8,一个Survivor占整个年轻代的1/10
- -XX:ParallelGCThreads=10 :设置ParNew GC的线程并行数,默认为 8 + (Runtime.availableProcessors - 8) * 5/8 ,24核机器为18。 -XX:MaxTenuringThreshold=15 :设置对象在年轻代的最大年龄,超过这个年龄则会晋升到老年代
- -XX:+UseParNewGC :设置新生代使用Parallel New GC
- -XX:+UseConcMarkSweepGC :设置老年代使用CMS GC,当此项设置时候自动设置新生代为ParNew GC
- -XX:CMSInitiatingOccupancyFraction=70 :
老年代第一次占用达到该百分比时候,就会引发CMS的第一次垃圾回收周期。后继CMS GC由HotSpot自动优化计算得到。
3. GC 日志解析
jstat命令输出

查看GC日志输出


总结:
在HDFS Namenode内存中的对象大都是文件,目录和blocks,这些数据只要不被程序或者数据的拥有者人为的删除,就会在Namenode的运 行生命期内一直存在,所以这些对象通常是存在在old区中,所以,如果整个hdfs文件和目录数多,blocks数也多,内存数据也会很大,如何降低Full GC的影响?
- 计算NN所需的内存大小,合理配置JVM

- 使用低卡顿G1收集器
为什么会有G1呢?
因为并发、并行和CMS垃圾收集器都有2个共同的问题:

G1垃圾收集器利用分而治之的思想将堆进行分区,划分为一个个的区域。
G1垃圾收集器将堆拆成一系列的分区,这样的话,大部分的垃圾收集操作就只在一个分区内执行,从而避免很多GC操作在整个Java堆或者整个年轻代进行。
编辑hadoop-env.sh
export HADOOP_NAMENODE_OPTS="-server -Xmx220G -Xms200G -XX:+UseG1GC - XX:MaxGCPauseMillis=200 -XX:+UnlockExperimentalVMOptions - XX:+ParallelRefProcEnabled -XX:-ResizePLAB -XX:+PerfDisableSharedMem -XX:- OmitStackTraceInFastThrow -XX:G1NewSizePercent=2 -XX:ParallelGCThreads=23 - XX:InitiatingHeapOccupancyPercent=40 -XX:G1HeapRegionSize=32M - XX:G1HeapWastePercent=10 -XX:G1MixedGCCountTarget=16 -verbose:gc - XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps - XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=100M - Xloggc:/var/log/hbase/gc.log -Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:- INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
注意:如果现在采用的垃圾收集器没有问题,就不要选择G1,如果追求低停顿,可以尝试使用G1
9.6 Hadoop二次开发环境搭建
系统环境
系统: CentOS-7_x86_64
protobuf: protoc-2.5.0
maven: maven-3.6.0
hadoop: hadoop-2.9.2
java: jdk1.8.0_131
cmake: cmake-2.8.12.2
OpenSSL: OpenSSL 1.0.2k-fips
findbugs: findbugs-1.3.9
准备工作
# 安装编译需要的依赖库
yum install -y lzo-devel zlib-devel autoconf automake libtool cmake openssl- devel cmake gcc gcc-c++
安装Maven
#上传maven安装包
# 解压缩
$ tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /usr/local/
# 配置到系统环境变量
$ vim /etc/profile
export MAVEN_HOME=/usr/local/apache-maven-3.6.3
export PATH=$PATH:$MAVEN_HOME/bin
# 刷新配置文件
$ source /etc/profile
# 验证maven安装是是否成功
$ mvn -version
[root@localhost ~]# mvn -version
Apache Maven 3.6.0 (ff8f5e7444045639af65f6095c62210b5713f426; 2018-10- 25T03:39:06+08:00) Maven home: /usr/local/apache-maven-3.6.3 Java version: 1.8.0_131, vendor: Oracle Corporation Java home: /usr/local/jdk1.8.0_131/jre Default locale: en_US, platform encoding: UTF-8 OS name: "linux", version: "4.20.13-1.el7.elrepo.x86_64", arch: "amd64", family: "unix"
安装protobuf
# 安装依赖环境
$ yum groupinstall Development tools -y
# 下载 $ https://github.com/protocolbuffers/protobuf/releases/download/v2.5.0/protobuf- 2.5.0.tar.gz
#上传protobuf安装包
# 解压缩
$ tar -zxvf protobuf-2.5.0.tar.gz cd protobuf-2.5.0
# 进入解压目录 配置安装路径(--prefix=/usr/local/protobuf-2.5.0)
$ ./configure --prefix=/usr/local/protobuf-2.5.0
# 编译
$ make
# 验证编译文件
$ make check
# 安装
$ make install
# 配置protobuf环境变量
$ vim /etc/profile
export PROTOCBUF_HOME=/usr/local/protobuf-2.5.0
export PATH=$PATH:$PROTOCBUF_HOME/bin
# 刷新配置文件
$ source /etc/profile
# 验证是否安装成功
$ protoc --version
[root@localhost ~]# protoc --version libprotoc 2.5.0
安装Findbugs
#下载
$https://jaist.dl.sourceforge.net/project/findbugs/findbugs/1.3.9/findbugs-1.3.9.tar.gz
#上传安装包
# 解压缩
$ tar -zxvf findbugs-1.3.9.tar.gz -C /usr/local/
# 配置系统环境变量
$ vim /etc/profile
export FINDBUGS_HOME=/usr/local/findbugs-1.3.9
export PATH=$PATH:$FINDBUGS_HOME/bin
# 刷新配置文件
$ source /etc/profile
# 验证是否安装成功
$ findbugs -version
[root@localhost ~]# findbugs -version 1.3.9
添加aliyun镜像
找到maven环境下的settings.xml文件,添加镜像代理
<mirror>
<id>nexus</id>
<mirrorOf>*</mirrorOf>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</mirror>
<mirror>
<id>nexus-public-snapshots</id>
<mirrorOf>public-snapshots</mirrorOf>
<url>http://maven.aliyun.com/nexus/content/repositories/snapshots/</url>
</mirror>
上传源码文件
进入代码文件目标路径
/root/hadoop-2.9.2-src/hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop- mapreduce-client-core/src/main/java/org/apache/hadoop/mapreduce/lib/input

编译
进入Hadoop源码目录
cd /root/hadoop-2.9.2-src
执行编译命令
mvn package -Pdist,native -DskipTests -Dtar
问题解决
hadoop-aws:jar时缺少依赖包DynamoDBLocal:jar
选择手动下载该Jar包,上传到本地maven仓库
cd /root/.m2/repository/com/amazonaws/DynamoDBLocal/1.11.86
