NameNode原理
1、磁盘与内存
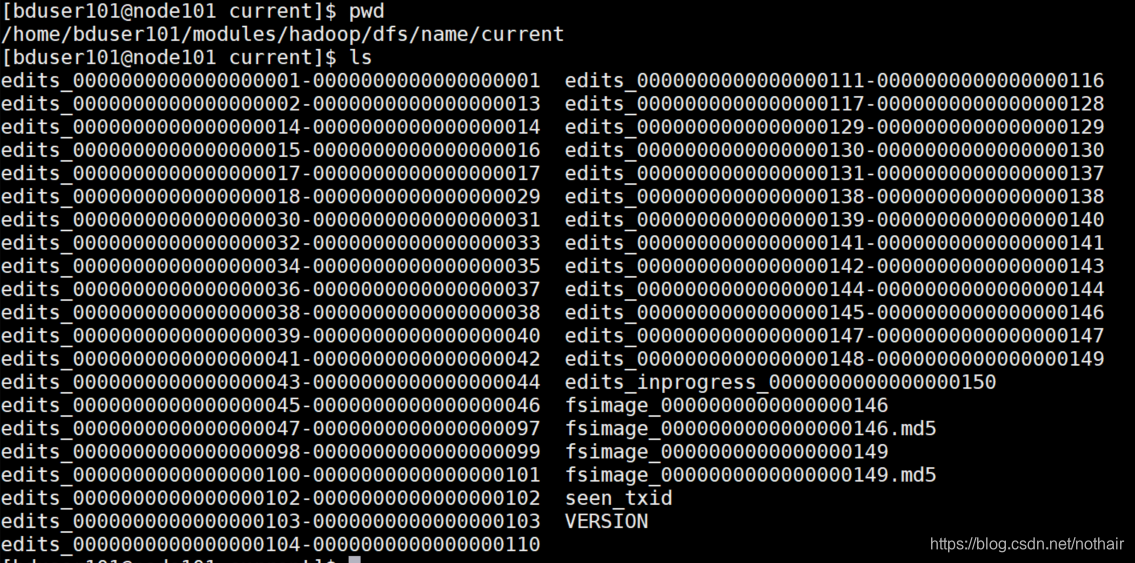
在NameNode开始服务时,将会读取磁盘上的edits,fsimage文件,在内存(缓存)使用这些数据
读到内存中使用的原因:和磁盘多次交互会导致效率变低,从内存增删改查则是高效的选择(例:对文件进行2000000次相同内容的删除增加,在内存中执行此操作,到最后到磁盘上的结果就是什么都没发生)
2、NameNode运行原理
- edits:编辑日志(操作过程数据)
- fsimages:镜像文件(某一时刻的完整状态,HDFS只会保存最新的两个镜像文件)
2.1、在hdfs第一次启动时,会在name目录下创建edits和fsimage文件。在之后的启动过程中,HDFS会把磁盘中最新的fsimage文件和edits文件加载到内存中,并且同时创建edits.inprogress文件。
2.2、edits文件分为两种,正在运行的文件系统将操作存储至edits_improgressxxx文件,在集群关闭或者进行滚动日志时该文件将转化为edits_xxx文件,如果是日志滚动将会生成新的edits_improgressxxx文件
2.3、例2:有一家公司的财务需要每两个月清算一下账单,清算结束后将结果布告。在这两个月中公司的所有进出账都会进行记录,并且浮动资金超过30%就要清算一次变成小账本,所以这两个月中可能只有一个小账本也可能有多个小账本。到了两个月就将所有小账本其合并至总账单中。如果工商局在一个半月的时候突然要求查看所有账单,那么进行合并将会是上次结算的总账单,所有已经总结好的小账本,以及还没来得及整理成小账本的财务明细
在本例中:
- 财务的总账单—>fsimage文件
- 小账本—>edits日志文件
- 没来的及整理成小账本的财务明细—>edits.inprogress文件
- 每两个月总结一次—>HDFS运行时间为一小时
- 浮动资金超过30%—>HDFS的操作记录数达到100万条
3、NameNode工作原理、checkpoint合并机制
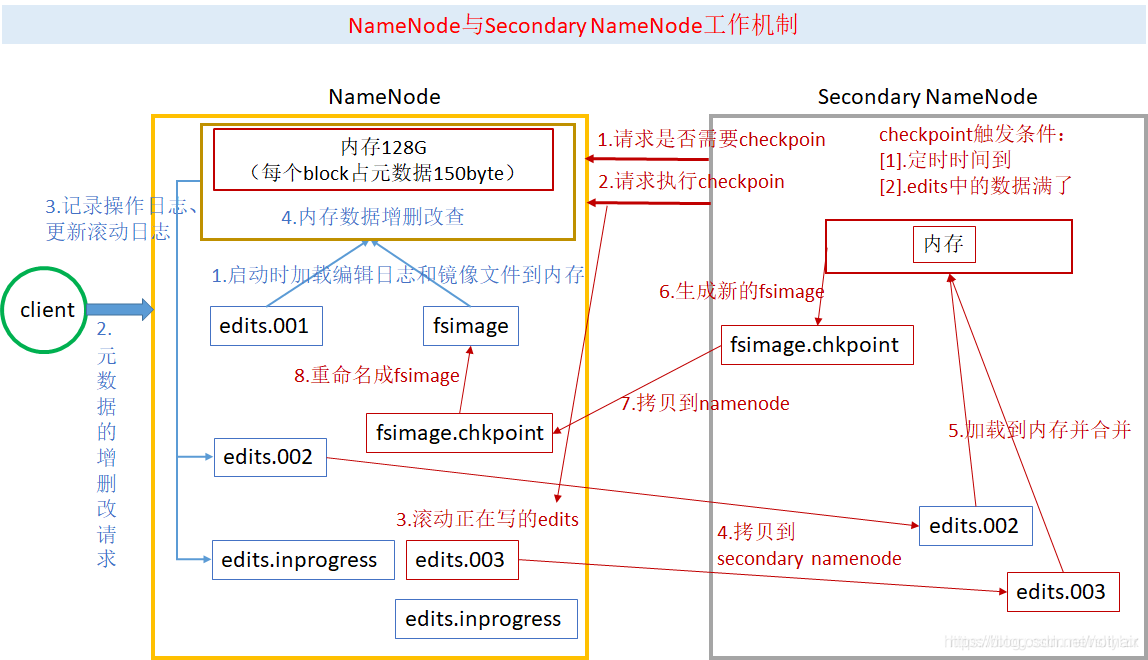
那么合并的工作由谁来做,什么时间做?
- SecondryNameNode将会执行这个操作
- 每隔一分钟SNN将会询问NN是否需要合并
- 触发两个条件之一将会合并
- 记录数达到100万条
- 集群运行时间达到了一小时
每次合并fsimage文件与edits文件都相当于合并 存储的最后一个fsimage文件和最后一段edits文件,以及当前集群的edits.inprogress滚动而来的文件
- 一次完整的checkpoint
- 1、 NameNode将最新的fsimage001文件和edits001文件读取到内存中,以此来保证文件系统是最新的状态
- 2、客户端发起对文件系统上的内容进行修改
- 3、最新的edits001文件进行一次滚动生成下一个edits02文件,并且生成edits.inprogress001文件,用来存储本次集群开启将进行的所有操作
- 4、用户提出的请求将会在内存中进行修改,并将操作记录记录至edits.inprogress001文件中
- 5、SNN向NN询问是否需要checkpoint(当文件系统运行了1小时或者操作记录达到100万次)
- 6、请求执行checkpoint操作
- 7、滚动正在记录的edits.inprogress001文件为edits003文件,并生成新的edits.inprogress002文件,记录在合并过程中对文件系统的操作
- 8、将edits002、edits003、fsimage001拷贝至SNN加载至内存进行合并
- 9、生成新的fsimage.chkpoint001文件
- 10、将新生成的fsimage.chkpoint001文件拷贝至NameNode中
- 11、将拷贝过来的fsimage.chkpoint001重命名为fsimage002文件,
- 12、下一次合并的应为由edits.inprogress002转化而来的edits文件、fsimage002文件、以及新生成的edits.inprogress滚动而来的文件,共同合并。
DataNode原理
1、两种文件
一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件
- 数据本身
- 元数据:包括数据块的长度,块数据的校验和,以及时间戳。
2、DataNode工作机制
- 2.1、DataNode启动后向NameNode注册,通过后,周期性(1小时)的向namenode上报所有的块信息。
- 2.2、NameNode每隔三秒向DataNode发送一次请求,达到确认该DataNode节点仍在服务,将指令发给DataNode节点
- 2.3、十分钟之内,DataNode向NameNode发送回执请求,确认DataNode仍在服务
- 2.4、如果超过十分钟DataNode仍没有发送回执请求,NameNode则认为该节点已经不可用。
3、动态服役、退役DataNode节点
在实际生产环境下,集群可能关闭或者启动将耗费很长时间,所以是不能够随意关闭启动的。在此状态下我们也能向集群中添加、删除DataNode节点
- 3.1、服役新节点
- 准备一台虚拟机
- 修改IP地址,主机名称
- 删除hadoop相关所有文件
- 在namenode的hadoop-2.7.6/etc/hadoop目录下创建dfs.hosts文件(文件内容为所有正在服役的Datanode节点名称以及将要服役的节点名称,用主机名,每行一个不允许空格)
- 在namenode的hdfs-site.xml配置文件中增加dfs.hosts属性

- 刷新NameNode
hdfs dfsadmin -refreshNodes - 更新resourcemanager节点
yarn rmadmin -refreshNodes - 在namenode节点的slaves文件中增加新服役的主机名
- 将hadoop/etc/hadoop的整个文件夹分发至集群中
- 在新服役的机器上启动DataNode服务
- [bduser@node105 hadoop-2.7.6]$ sbin/hadoop-daemon.sh start datanode
- [bduser@node105 hadoop-2.7.6]$ sbin/yarn-daemon.sh start nodemanager
- 在webUI上查看是否有新节点服务信息
- 3.2、退役旧节点
- 在/hadoop-2.7.6/etc/hadoop目录下创建dfs.hosts.exclude文件,文件内容为即将退役的节点主机名
- 在NameNode上把刚才在hdfs-site.xml中增加的属性注释,添加新的属性

- 将/hadoop2.7.3/etc/hadoop同步到所有节点上
- 同样刷新namenode和resourcemanager
- 等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役
- 在退役节点上运行
[bduser@node105 hadoop-2.7.6]$ sbin/hadoop-daemon.sh stop datanode[bduser@node105 hadoop-2.7.6]$ sbin/yarn-daemon.sh stop nodemanager
- 从namenode的slave文件中删除退役节点