文章目录
前言
文本特征提取CountVectorizer属于机器学习特征工程中特征提取的一个tip,如果我们对一篇文章进行分类,用什么特征比较好呢(不单看文章的标题的话)?句子、短语、单词、字母中哪个合适一点呢,比较一下单词好一点。句子本身也是单词排列组合起来的,情况太多了,用句子作为特征提取不太现实,太多了不好处理;同理短语也是,单词就更不必说了不合适的。那怎么把单词作为特征词转换成数值形式呢?本文先介绍一种方法CountVectorizer。
一、CountVectorizer使用举例
1.sklearn官网API
网址:https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.CountVectorizer.html#sklearn.feature_extraction.text.CountVectorizer
截图:

这里我红框标记了两个,因为我觉得这两个超参数比较常用。
老板说了:不可能每一个参数都记得一清二楚,工作不是上学,不是闭卷考试,会查会用就OK!哈哈。
2.CountVectorizer()提取英文文本举例
代码如下(默认参数):
from sklearn.feature_extraction.text import CountVectorizer #导包
#准备数据
data=['Life is short short dislike,i like like like python','Life is too long Life,i dislike python','i like you also']
#实例化一个转换器类
transfer=CountVectorizer()
#将data喂入实例化好的transfer的fit-transform()方法之中
new_data=transfer.fit_transform(data)#此时返回一个sparse稀疏矩阵
print('看一下new_data的值:\n{}'.format(new_data))
print('看一下new_data的类型:{}'.format(type(new_data)))
print("特征名字:{}".format(transfer.get_feature_names()))
print('看一下new_data的shape:{}'.format(new_data.shape))
#将sparse矩阵转换成数组,统计每一个样本出现的特征值的个数
print('new_data转换成数组:\n{}'.format(new_data.toarray()))
运行结果如下:
看一下new_data的值:
(0, 3) 1
(0, 2) 1
(0, 7) 2
(0, 1) 1
(0, 4) 3
(0, 6) 1
(1, 3) 2
(1, 2) 1
(1, 1) 1
(1, 6) 1
(1, 8) 1
(1, 5) 1
(2, 4) 1
(2, 9) 1
(2, 0) 1
看一下new_data的类型:<class ‘scipy.sparse.csr.csr_matrix’>(从这里可以看出是一个稀疏矩阵)
特征名字:[‘also’, ‘dislike’, ‘is’, ‘life’, ‘like’, ‘long’, ‘python’, ‘short’, ‘too’, ‘you’]
看一下new_data的shape:(3, 10)
new_data转换成数组:
[[0 1 1 1 3 0 1 2 0 0]
[0 1 1 2 0 1 1 0 1 0]
[1 0 0 0 1 0 0 0 0 1]] (稀疏矩阵用toarray()方法转换成了矩阵)
是将英文单词转换成了稀疏矩阵,统计样本特征词出现的个数。但是光看运行结果的代码好像不是那么直观,下图分析可以看的更直观一点,它是怎么转换的:
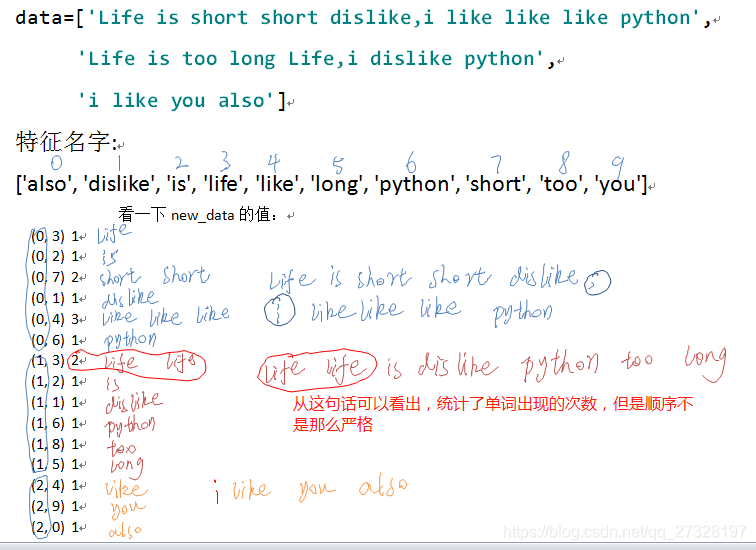
像逗号,i,a这样的标点符号和字母API在设计的时候,自动的就不统计了。
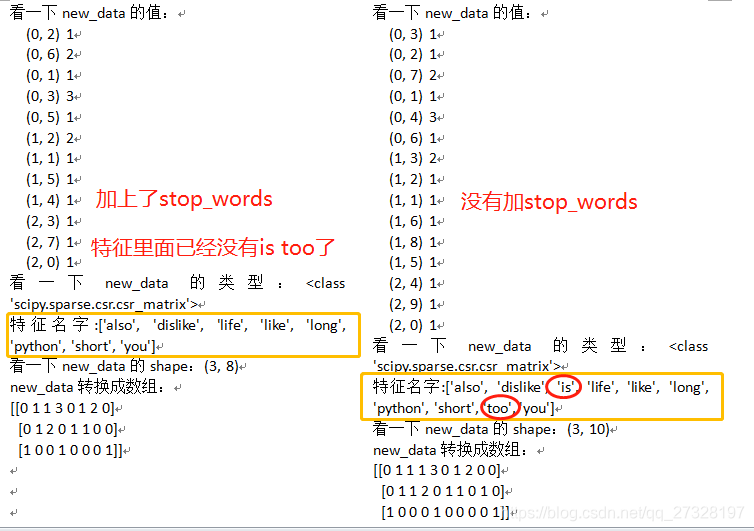
设置一下停用词stop_words(以list的方式把想停用的词给放进去)
from sklearn.feature_extraction.text import CountVectorizer #导包
#准备数据
data=['Life is short short dislike,i like like like python','Life is too long Life,i dislike python','i like you also']
#实例化一个转换器类,
# 这里用一下停用词参数stop_words=['is','too'],is和too感觉不是很重要
transfer=CountVectorizer(stop_words=['is','too'])
#将data喂入实例化好的transfer的fit-transform()方法之中
new_data=transfer.fit_transform(data)#此时返回一个sparse稀疏矩阵
print('看一下new_data的值:\n{}'.format(new_data))
print('看一下new_data的类型:{}'.format(type(new_data)))
print("特征名字:{}".format(transfer.get_feature_names()))
print('看一下new_data的shape:{}'.format(new_data.shape))
#将sparse矩阵转换成数组,统计每一个样本出现的特征值的个数
print('new_data转换成数组:\n{}'.format(new_data.toarray()))
2.CountVectorizer()提取中文文本不合适
上面提取了英文句子,但是对于中文适合不适合呢?可以将上面例子中的代码更改一下,只改data部分,将英文改成中文试试:
#文本特征提取CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer #导包
#将数据改成中文试试看结果
data=['艾斯梅拉达爱上了弗比斯','听说我有王牌']
#实例化一个转换器类
transfer=CountVectorizer()
#将data喂入实例化好的transfer的fit-transform()方法之中
new_data=transfer.fit_transform(data)#此时返回一个sparse稀疏矩阵
print('看一下new_data的值:\n{}'.format(new_data))
print('看一下new_data的类型:{}'.format(type(new_data)))
print("特征名字:{}".format(transfer.get_feature_names()))
print('看一下new_data的shape:{}'.format(new_data.shape))
#将sparse矩阵转换成数组,统计每一个样本出现的特征值的个数
print('new_data转换成数组:\n{}'.format(new_data.toarray()))
运行结果如下:
看一下new_data的值:
(0, 1) 1
(1, 0) 1
看一下new_data的类型:<class ‘scipy.sparse.csr.csr_matrix’>
特征名字:[‘听说我有王牌’, ‘艾斯梅拉达爱上了弗比斯’]
看一下new_data的shape:(2, 2)
new_data转换成数组:
[[0 1]
[1 0]]
运行结果表明直接把一句短语作为特征了,这样是不太合适的。因为英文一句话中单词之间是有空格隔开的,中文字之间没有空格隔开,所以当成一个整体了,本例中提取出来特征就只有两个。
可以把上述代码再更改一下,中文字之间加入一些空格,看看效果:
from sklearn.feature_extraction.text import CountVectorizer #导包
#中文之间手动加入一些空格看看效果
data=['艾斯梅拉达 爱上 了 弗比斯','听说 我 有 王牌']
#实例化一个转换器类
transfer=CountVectorizer()
#将data喂入实例化好的transfer的fit-transform()方法之中
new_data=transfer.fit_transform(data)#此时返回一个sparse稀疏矩阵
print('看一下new_data的值:\n{}'.format(new_data))
print('看一下new_data的类型:{}'.format(type(new_data)))
print("特征名字:{}".format(transfer.get_feature_names()))
print('看一下new_data的shape:{}'.format(new_data.shape))
#将sparse矩阵转换成数组,统计每一个样本出现的特征值的个数
print('new_data转换成数组:\n{}'.format(new_data.toarray()))
运行结果如下:
看一下new_data的值:
(0, 4) 1
(0, 2) 1
(0, 1) 1
(1, 0) 1
(1, 3) 1
看一下new_data的类型:<class ‘scipy.sparse.csr.csr_matrix’>
特征名字:[‘听说’, ‘弗比斯’, ‘爱上’, ‘王牌’, ‘艾斯梅拉达’]
看一下new_data的shape:(2, 5)
new_data转换成数组:
[[0 1 1 0 1]
[1 0 0 1 0]]
这样貌似可以完成对中文文本特征的提取,但是实际运用过程中,对所有的中文都这样手动的去加空格的话,就得不偿失了。所以要用到一些专门的中文分词工具比如Jieba分词(本文暂不介绍),或者更为专业的分词工具,或者公司自己研发的专门的工具了。
总结
本文介绍了一下怎么使用CountVectorizer使用,CountVectorizer提取英文还可以,提取中文不太合适。(如果您发现我写的有错误,欢迎在评论区批评指正)