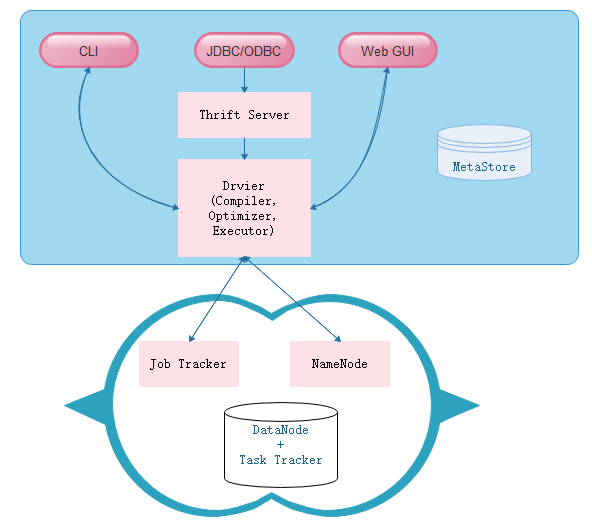
- hive基础架构图解
作为Hadoop的主要数据仓库解决方案,底层存储依赖于HDFS,而Hive SQL是主要交互接口,而真正的计算和执行则由MapReduce完成,它们之间的桥梁是Hive引擎。接下来,具体看下HIVE的引擎架构:
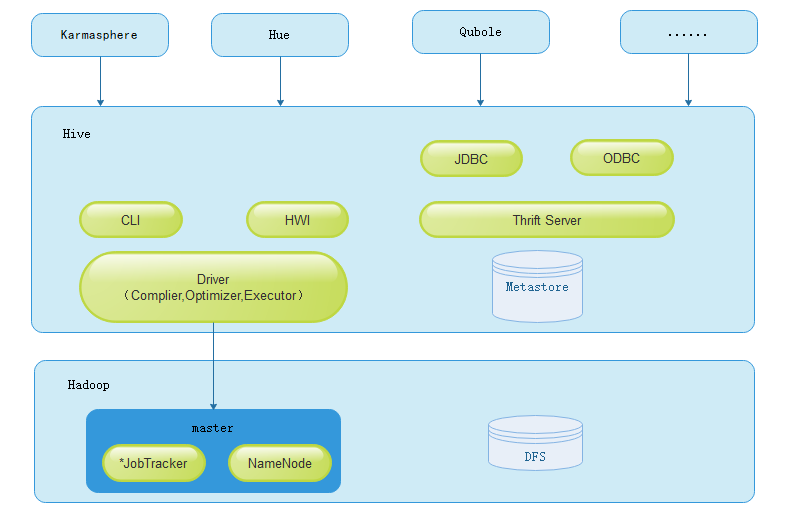
- hive组件介绍
Hive的主要组件包括UI组件、Driver组件(Complier、Optimizer和Executor)、Metastore组件、CLI(Command Line Interface,命令行接口)、JDBC/ODBC、Thrift Server和Hive Web Interface(HWI)等。,接下来分别对这几个组件进行介绍。
- Drvier组件
该组件是Hive的核心组件,该组件包括Complier(编译器)、Optimizer(优化器)和Executor(执行器),它们的作用是对Hive SQL语句进行解析、编译优化、生成执行计划,然后调用底层MR计算框架。- MetaStore组件
该组件是Hive用来负责管理元数据的组件。Hive的元数据存储在关系型数据库中,其支持的关系型数据库有Derby和mysql,其中Derby是Hive默认情况下使用的数据库,它内嵌在Hive中,但是该数据库只支持单会话,也就是说只允许一个会话链接,所以在生产中并不适用,其实其实在平时我们的测试环境中也很少使用。在我们日常的团队开发中,需要支持多会话,所以需要一个独立的元数据库,用的最多的也就是Mysql,而且Hive内部对Mysql提供了很好的支持。
连接到数据库的模式:有三种模式可以连接到数据库:
a). 单用户模式。此模式连接到一个In-memory 的数据库Derby,一般用于Unit Test。
b). 多用户模式。通过网络连接到一个数据库中,是最经常使用到的模式。
c). 远程服务器模式。用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。
对于数据存储,Hive没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。
Hive中所有的数据都存储在HDFS中,存储结构主要包括数据库、文件、表和视图。Hive中包含以下数据模型:Table内部表,External Table外部表,Partition分区,Bucket桶。
Hive默认可以直接加载文本文件,还支持sequence file 、RCFile。- CLI
Hive的命令行接口- Thrift Server
该组件提供JDBC和ODBC接入的能力,用来进行可扩展且跨语言的服务开发。Hive集成了该服务,能让不同的编程语言调用Hive的接口- Hive Web Interface
该组件是Hive客户端提供的一种通过网页方式访问Hive所提供的服务。这个接口对应Hive的HWI组件
Hive通过CLI,JDBC/ODBC或HWI接受相关的Hive SQL查询,并通过Driver组件进行编译,分析优化,最后编程可执行的MapReduce任务,但是具体里面是怎么执行的,