前言
本文是介绍的是开发spark极其核心的地方,可以说懂得解决spark数据倾斜是区分一个spark工程师是否足够专业的标准,在面试中以及实际开发中,几乎天天面临的都是这个问题。
原理以及现象
先来解释一下,出现什么现象的时候我们认定他为数据倾斜,以及他数据倾斜发生的原理是什么?
比如一个spark任务中,绝多数task任务运行速度很快,但是就是有那么几个task任务运行极其缓慢,慢慢的可能就接着报内存溢出的问题了,那么这个时候我们就可以认定他是数据倾斜了。
接下来说一下发生数据倾斜的底层理论,其实可以非常肯定的说,数据倾斜就是发生在shuffle类的算子中,在进行shuffle的时候,必须将各个节点的相同的key拉到某个节点上的一个task来进行处理,比如按照key进行聚合和join操作等,这个时候其中某一个key数量量特别大,于是就发生了数据倾斜了。
定位数据倾斜的代码
上面我们知道了数据倾斜的底层原理,那么就好定位代码了,所以我就可以改写这段代码,让spark任务来正常运行了。
我们知道了导致数据倾斜的问题就是shuffle算子,所以我们先去找到代码中的shuffle的算子,比如distinct、groupBYkey、reduceBykey、aggergateBykey、join、cogroup、repartition等,那么问题一定就出现在这里。
找到shuffle类的算子之后,我们知道一个application分为job,那么一个job又划分为多个stage,stage的划分就是根据shuffle类的算子,也可以说是宽依赖来划分的,所以这个时候我们在spark UI界面上点击查看stage,如下图:
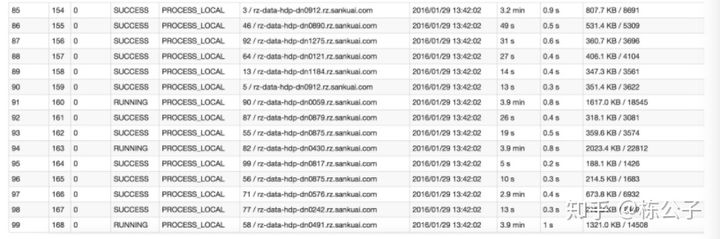
可以看到94这一行和91这一行,执行时间明显比其他的执行时间要长太多了,我们就可以肯定一定是这里发生了数据倾斜,然后我们就找到了发生数据倾斜的stage了,然后根据stage划分原理,我们就可以推算出来发生倾斜的那个stage对应的代码中的哪一部分了。
这个时候我们找到了数据倾斜发生的地方了,但是我们还需要知道到底是哪个key数据量特别大导致的数据倾斜,于是接下来来聊一聊这个问题。
找到这个key的算法,我们可以使用采样的方式,对,就是当初虐了我们千百遍的概率论与数理统计的课上讲的采样算法。
代码如下:
val sampledPairs = pairs.sample(false, 0.1)
val sampledWordCounts = sampledPairs.countByKey()
sampledWordCounts.foreach(println(_))现在我来简单说一下他的原理,他就是从所有key中,把其中每一个key随机取出来一部分,然后进行一个百分比的推算,学过采样算法的都知道,这是用局部取推算整体,虽然有点不准确,但是在整体概率上来说,我们只需要大概之久可以定位那个最多的key了。
解决数据倾斜的方案
上面我们聊了数据倾斜发生的原理以及如何定位是哪个key发生了数据倾斜,这个时候我们就开始着手解决这个问题了,我把分为七中解决方案,每个方案都有对应的情况,读者可以针对自己的情况来灵活运用。
解决方案一:使用hive ETL预处理数据
先来说一说发生的一个场景:你的业务中有一个需要实时的页面,但是这个页面的数据是基于昨天的数据来进行统计,我们深入到代码中来说就是两个rdd需要先join操作,然后才能进行统计,这个时候,因为其中有rdd的某个key数据量特别大,于是在前端页面需要展示的时候统计一次需要大量的时候,如果你的产品经理就跟你说了,能不能把速度提升一下,我都到外面抽了好几颗烟了,你还没跑出来,这是要让我抽死啊,耗费烟钱啊,你能怎么办?你难道还上去说这是数据倾斜了,我没办法啊,你只能等等吗?这样怕是你脑子瓦特了,于是我们就来注意其中的一个描述,他需要的两个rdd是昨日的数据,所以解决方案就是在晚上12点的时候,我们让spark去先join操作,然后等第二天的时候,你的产品经理去统计的时候,这个时候直接用join好的数据来处理,就不会发生数据倾斜了,因为根本就已经避免了数据倾斜,所以时间非常快。
解决方案二:过滤少数导致清晰的key
上面我们聊了一下用提前先join的办法来解决数据倾斜,但是还是不够完美,因为其实依旧是发生了数据倾斜,只是我们提前就把他运行好了,所以在实时页面的展示的时候可以避免,但是从根本上来说,我们根本没有解决数据清晰的问题,数据倾斜问题依旧存贮。
这个时候我们就来聊下更深一步的解决方案。
这个方案也是有业务场景的,我们继上面那个实时统计的例子来说,假如我们发现两个rdd进行join的中key是毫无用处的,也就是跟我们的业务没有关系,但是我们之前没有注意到,这个时候我们经过深入的分析之后发现确实没啥用,而且还数量巨大,这个时候就简单了,我们就直接用filter算子来过滤掉这些key,然后再入join,这个时候我们就发现了,一下子把数据清晰的key给过滤掉了,我们就不用考虑数据倾斜的问题了。
可以说这个情况也是时常发生的,比如在系统出现异常的情况下,会有大批量固定格式的日志出来,而且都是报错的,对与我们的实际业务其实根本没啥用,我们就可以过滤掉了,再比如在一个业务场景中,有些key对于我们的业务并没有用,我们留着他干啥呢,直接过滤掉,数据越少,计算越快。
但是这种情况并不是所有的情况都有,我们还需要继续深入探究解决方案。
解决方案三:提高shuffle操作的并行度
可以说解决办法要一步一步的来说,我们上面的两种方案都有他极其特殊的地方,并不是特别普遍的,于是,我们来找一个普遍的解决方案,那就是提高shuffle 的并行度。
他的原理很简单,我们知道在rduceBykey中有一个shuffle read task的值默认为200,也就是说用两百个task来处理任务,对于我们一个很大的集群来说,每个task的任务中需要处理的key也是比较多的,这个时候我们把这个数量给提高以爱,比如我么设置reduceBYkey(1000),这个时候task的数量就多了,然后分配到每个task中的key就少了,于是说并行度就提高了。但是总体来说,这种解决办法对于某一个数量特别大的key来说效果甚为,只能说key多的时候,我们可以有一定的程度上环境数据倾斜的问题,所以这种方法也不是我们要找到的最好的办法,他也是有一定的局限性。
任重而道远,我们还需要继续寻找。
解决方案四:两阶段聚合(局部聚合+全局聚合)
看过了上面哪些方法,局限性都太大,我们还需要寻找。那么解决方案四就比较专业了。
用这个方法就可以解决大部分场景的数据倾斜。
因为这个方法比较重要,所以我把写的详细一些。
这个时候我们有一个rdd,他的其中某一个key数量比较大,我们要进行shuffle的时候,速度比较慢。
比如这个key就是hello,他的条数已经有1万条。
单一的进行shuffle肯定是耗时非常长。所以我们给他打上10以内的随机前缀,例如下面这种形式。
0_hello,1
1_hello,1
2_hello,1
3_hello,1
0_hello,1
2_hello,1
3_hello,1
.....然后这个时候进行局部的预聚合,比如reduceBykey,上面我是给了三以内的预聚合。于是经过局部的语句和,我们得到了下面这种
0_hello,3000
1_hello,2000
2_hello,2500
3_hello,2500 然后在去掉之前加的随机前缀,在进行聚合,reduceBykey
hello,10000于是通过这种把key进行拆分的方式,我们把key分配给了一些task去执行任务,经过实验数据表明,这种方法可以提高数倍效率,不知道您看明白了没?
这里我给出具体的一些代码,可以参考:
object WordCountAggTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
val array = Array("you you","you you","you you",
"you you",
"you you",
"you you",
"you you",
"jump jump")
val rdd = sc.parallelize(array,8)
rdd.flatMap( line => line.split(" "))
.map(word =>{
val prefix = (new util.Random).nextInt(3)
(prefix+"_"+word,1)
}).reduceByKey(_+_)
.map( wc =>{
val newWord=wc._1.split("_")(1)
val count=wc._2
(newWord,count)
}).reduceByKey(_+_)
.foreach( wc =>{
println("单词:"+wc._1 + " 次数:"+wc._2)
})
}
}当然了,这种方法也是有局限性的,他适用于聚合类的shuffle操作,如果对于join操作,还是不行的,所以我们接着探究更深入的方法。
解决方案五:将reduce join转整map join
这种方法是有假定的前提的条件的,比如有两个rdd进行join操作,其中一个rdd的数据量不是很大,比如低于1个G的情况。
具体操作是就是选择两个rdd中那个比较数据量小的,然后我们把它拉到driver端,再然后通过广播变量的方式给他广播出去,这个时候再进行join 的话,因为数据都是在同一Executor中,所以shuffle 中不会有数据的传输,也就避免了数据倾斜,所以这种方式很好。
给出参考代码:
object MapJoinTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(conf)
val lista=Array(
Tuple2("001","令狐冲"),
Tuple2("002","任盈盈")
)
//数据量小一点
val listb=Array(
Tuple2("001","一班"),
Tuple2("002","二班")
)
val listaRDD = sc.parallelize(lista)
val listbRDD = sc.parallelize(listb)
//val result: RDD[(String, (String, String))] = listaRDD.join(listbRDD)
//设置广播变量
val listbBoradcast = sc.broadcast(listbRDD.collect())
listaRDD.map( tuple =>{
val key = tuple._1
val name = tuple._2
val map = listbBoradcast.value.toMap
val className = map.get(key)
(key,(name,className))
}).foreach( tuple =>{
println("班级号"+tuple._1 + " 姓名:"+tuple._2._1 + " 班级名:"+tuple._2._2.get)
})
}
}当然了,这种方法也是有缺陷的,比如两个rdd都非常大,比如超过了10个G,这个时候我们就不能用这种方法了,因为数据量太大了,广播变量还是需要太大的消耗,我们还需要继续探索更深层次的解决办法。于是就有下面这种不可思议的解决办法。
解决方案六:采样倾斜key并分拆join操作
注意:再讲解本方法之前,我还需要说明一点,如果您没看懂就多看一次,因为这种法方法太不可思议了,真的要明白还是需要一点想想力的,我尽量把它表达的明白些。
在方法五中,我们通过广播的方式可以解决低于5个G以下的两个rdd的操作,但是这个方法是解决超过10个G以上的数据,比如50个G的数据都可以。
实现思路:
1.对包含少数几个数据量过大的key的那个Rdd,通过sample算子采样出一份样本来,然后统计以下每个key的数量,计算出来数据量最大的是哪几个key。
2.然后将这几个key对应的数据从原来的rdd中拆分出来,形成一个单独的rdd,并给每个key都打上n以内的随机数作为前缀,而不会导致倾斜的大部分key形成另外一个rdd。
3.接着将需要join的另外一个rdd,也过滤出来那几个倾斜的key对应的数据并形成一个单独的rdd,将每条数据膨胀成n条数据,这n条数据都按顺序附加一个0~n的前缀,不会导致倾斜的大部分key也形成另外一个rdd。
4.再将附加了随机前缀的独立rdd与另外一个膨胀n倍的独立rdd进行join,此时就可以将原先相同的key打算成n份,分散到多个task中去进行join了。
5.而另外两个普通的rdd就照常join即可。
6.最后将两次join的结果使用union算子合并起来即可,就是最终join结果。
不知道您看懂了没有?确实比较复杂,但是下面这个更加复杂,如果参透了这一招,下面的一招就很简单了。
解决方案七:谁用随机前缀和扩容rdd进行join
这个方法其实和第六种方法是相同的,但是在解决方案六中,是只有少量的key有数据倾斜,在这个方法中是绝大部分的key都是有数据倾斜的,所以我们这个方法就是不区分那少量key了,直接全部数据加随机前缀,然后扩容进行join。