瞎掰HTTP
HTTP(HyperText Transfer Protocol)超文本传输协议,一个应用层协议,定义了客户端和服务端的请求-响应方式。
简单聊聊HTTP历程
- HTTP 0.9
作为HTTP协议的一代目,稍微不太成熟(完善),本来没有版本号加冕的,为了区别后面版本的协议,就划分了个0.9给它。
其方式如下,由单行指令构成的请求,以唯一可用方法GET开头,其后跟目标资源的路径(一旦连接到服务器,协议、服务器、端口号这些都不是必须的)。
GET /hello.html
响应也略显简陋,没有HTTP头、状态码或者错误码,只包含响应文档本身。
<HTML>
你好,世界!
</HTML
- HTTP 1.0
1996年,一个更健壮的HTTP协议二代目诞生了, 引入了请求(响应)头+请求(响应)体的概念,而且也可以传输除纯文本HTML文件以外其他类型的文档。(感谢Content-Type头)
然而HTTP1.0缺陷也很明显。每次请求都需要新建TCP连接,然后关闭,下次请求再新建关闭,即TCP连接不能复用。
- HTTP 1.1
1997年,开始修订HTTP的第一个标准化版本,即HTTP 1.1。它做了如下的改进:
- 复用TCP连接,节省多次新建-断开连接的时间。(感谢 connection keeplive)
- 增加管线化技术。
- 支持响应分块。(感谢Transfer-Encoding)
- 引入额外的缓存控制机制。
- 引入内容协商机制,包括语言,编码,类型等,并允许客户端和服务器之间约定以最合适的内容进行交换。
- 感谢Host头,能够使不同域名配置在同一个IP地址的服务器上。
关于管线化技术。它可以让客户端在发送第一个请请求后不必等待应答即可发送第二、三…请求。但为了遵循HTTP1.1协议,服务器还是需要按请求的顺序有序的返回结果,这样整个连接还是先进先出,队头阻塞还是会发生,在该协议下,浏览器一般也是默认关闭该技术的。(只不过把原来客户端的FIFO搬到服务器端)

关于响应分块。一般情况下,HTTP的响应消息体是作为整包发送到客户端的,并用Content-Length 来表示消息体的长度。在TCP连接可以服用的情况下,这个长度可以让客户端知道响应消息是从哪里开始和结束的。

而响应分块,通过在响应头里添加Transfer-Encoding: chunked,告诉浏览器我使用的是分块传输编码,然后把响应数据分解成一系列数据块,一个完整的消息体由n个块组成,并以最后一个大小为0的块为结束,服务器发送数据时不再需要预先告诉客户端发送内容的总大小。
- HTTP 2.0
尽管HTTP1.1看起来挺好的了,但还是有遗憾之处:
- 管线化技术有队头阻塞问题
- 单个TCP连接真正实现复用多个请求
- 当HTTP header很长时,影响网页加载延迟
针对上述问题,HTTP 2.0做了改进:
- HTTP 2.0是二进制协议而不再是文本协议,并行的请求能在同一个链接中处理,移除了HTTP/1.x中顺序和阻塞的约束,便于多路服用的实现。
- HTTP 2.0消除了这些限制后,通过允许客户端和服务器将HTTP消息分解为独立的帧,进行交织,然后在另一端重新组装,从而实现了完整的请求和响应多路复用。(想象你下载一部电视剧合集,不再是第一集下载完后再下载第二、三。。。)
- HTTP 2.0中,标头字段被压缩并以二进制代码传输,而不再是明文传输。
其允许服务器在客户端缓存中填充数据,通过一个叫服务器推送的机制来提前请求。- 服务器推送。HTTP 1.1中,请求一个页面后,如果它包括了CSS、JS等资源,浏览器会再发起请求,获取这些资源文件。在HTTP 2.0中,除了响应于原始请求,服务器还可以向一个客户端请求发送多个响应,而客户端不必显式地请求每个请求。
注意,HTTP 2.0的使用有HTTPS要求。
- HTTP 3.0
- 关于HTTP3.0,虽然有人起草案了,不过截至到2021年1月18号,还没正式应用起来。
- 它基于QUIC协议,旨在将HTTP协议应用到UDP的基础上,并实现多路复用、0-RTT、TLS加密、流量控制、丢包重传等功能。
从HTTP到HTTPS
HTTP在基本的TCP/IP协议栈上发送信息,网景公司在此基础上创建了一个额外的加密传输层:SSL(安全套接字层,Secure Sockets Layer) 。而SSL又在标准化道路上最终成为TLS(传输层安全性,Transport Layer Security)。HTTPS协议也被称为HTTP通过TLS或基于SSL的HTTP(参考维基百科)。2016年,电子前沿基金会(EFF)在网络浏览器开发人员的支持下发起了一项运动,导致该协议变得越来越普遍。
扫描二维码关注公众号,回复: 12665084 查看本文章
关于HTTPS的加密算法,它采用了对称加密算法+非对称加密算法的加密方式。为啥?
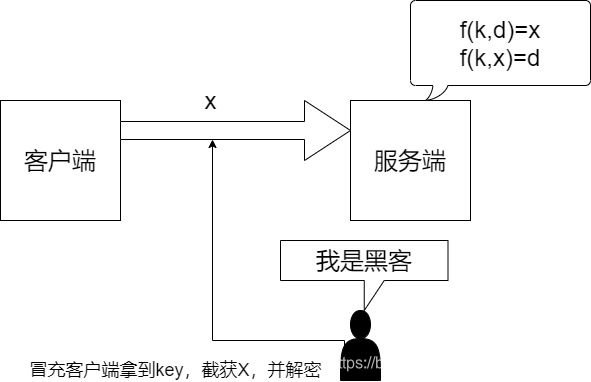
- 假设采用对称加密算法,如图所示,有个密钥k,可以对数据d加密成密文X,又可以将密文X解密成数据d。
- 当有黑客冒充客户端,拿到密钥k后,拦截到其他客户端发送的密文X时,将轻易破解。
- 当然了,不同的客户端也可以不同的密钥k,但如果有一亿个客户端,服务器也要保存一亿个密钥吗~似乎不太现实。
- 假设采用非对称加密。有一个公钥pk和私钥sk,公钥可以将数据d加密成密文x,私钥sk则将密文x解密成数据d。同理,私钥也可以将数据d加密成密文x(这个x跟公钥加密x的不一样),公钥也可以将密文还原成数据d。
- 接着,客户端索要公钥pk,然后客户端发送密文X。这个过程,虽然黑客可以获取到公钥pk,但由于没有私钥,黑客没能破解,密文x是安全的。
- 但是,对于服务端发送到客户端的数据Y来说,由于黑客也有公钥,所以Y能被黑客破解,这个过程则不安全了。

而采用了对称加密算法+非对称加密算法如何实现加密内容不被破解勒~
- 从上图可以知道,采用非对称加密的方式,客户端发往服务端方向的密文是安全的,那么,我们可以先通过非对称加密的方式协商出一个k(这个k可以简单的先理解为就是用来进行对称加密用的密钥)
- 对于客户端来说,这个k会被保存在本地,而发送到服务器上的密文x,由于黑客没有私钥没法破解,就不能知道客户端想要的密钥k是什么内容了。
- 服务端因为有私钥,它可以解出k,就知道客户端是用哪个密钥进行加密了。后边和客户端交互的数据就用这个密钥k进行对称加密。
其实,如果有列文虎克的朋友会发现,其实不需要对称加密也可以,即第二个阶段,协商出密钥k,变成协商出公钥和私钥,客户端本地保存一份,后面和服务端进行数据交互时,就可以全部采用非对称加密的方式了。
其实,在《图解HTTP》一书中有这样一段描述,加密过程就是对离散对数求值,这并非而易举就能办到的。如果传输内容使用非对称加密进行加密与解密的话,速度会慢到2~100倍。而通过非对称加密,服务器与客户端协定一个共享密钥进行对称加密,即保证安全又兼顾速度。
中间人
采用了对称加密算法+非对称加密算法看似完美了,但道高一尺,魔高一丈。如图所示。
- 当黑客拦截请求,并在客户端和服务端之间伪造了一个看似目标服务器的中间服务器,从而欺骗了客户端。
- 客户端请求的公钥其实是中间服务器伪造的,而且,中间服务器代替了客户端向真正的服务器进行请求,获取到了公钥pk*。
- 后面进行对称加密时,客户端的私钥也是中间服务器伪造的,客户端请求的内容对于中间服务器来说,是一个“裸奔”的状态。

CA
如何解决这个中间人问题勒。其实分析中间人的入侵步骤,我们可以知道,在客户端第一步获取公钥的过程中就已经不对劲了,因为客户端拿到的公钥是中间人伪造的。如果有一个可以证明公钥PK是安全的方式,不就没有后边的事情了吗~
于是就有了CA机构(Catificate Authority,证书颁发机构)了,任何个体/组织都可以扮演 CA 的角色,只不过难以得到客户端的信任(有时候访问一些网站经常会弹框提示该网站的证书不受信任)。
理解CA如何增加HTTPS的安全性的问题上,需要先了解一哈:
- OS保证给你加好了世界上公认可信的CA,并且把修改内核这个操作加上权限限制,除非用户作死。当然了,一些浏览器也有内置自己信任的CA列表。
- CA也是有自己的公钥和私钥的。
- 当你申请一个证书时, CA 判明申请者的身份后,便为他分配一个公钥,并且 CA 将该公钥与申请者的身份信息绑在一起,并为之签字后,便形成证书发给申请者。
于是有如下图,Cpk、Csk代表CA机构的公钥和私钥:

- 中间人的问题是在一开始申请pk的时候就出错了的,那么现在客户端不申请pk了,改为申请证书。
- 假设现在的证书是中间人伪造的,那么当客户端通过本地的Cpk进行校验后就会发现不对劲,从而弹窗提示该网站的证书不受信任。
其他
上文说到了HTTPS采用的是对称加密和非对称加密的加密方式,而在协商出对称加密用的私钥k时,流程其实太过简单粗暴,详细点的步骤如下:
- 客户端请求服务端时,会携带随机数、支持SSL版本及采用的非对称算法的信息。
- 服务端向客户端发送随机数、采用的SSL版本、对称算法、证书信息。
- 客户端CA认证成功。
- 客户端向服务端发送随机数、并将1、2步骤产生的随机数进行哈希的结果一同携带上去。(这个过程是非堆成加密,其密文只有服务器上的私钥能解)
- 服务端也将1、2步骤产生的随机数进行哈希,与客户端上传的哈希值进行比较。
- 服务端根据1、2、4步骤产生的随机数生成用于对称加密的私钥k,然后再次将根据1、2、4步骤产生的随机数通过哈希,将哈希结果发送到客户端。
- 客户端也将1、2、4步骤产生的随机数进行哈希,并将结果和服务端发送的哈希值进行比较,若一致,也根据1、2、4步骤产生的随机数生成用于对称加密的私钥k私钥k。
- 后面就可以用私钥k进行内容的对称加密了。