JS逆向之网抑云
许多人都喜欢网抑云,其一有歌曲,还有就是它的评论,上面的评论有些是鸡汤,有些直击心灵,反正许多给我的是一种丧的感觉,废话不多说,先来分析一波。
在这里我搜索的歌是天下,这还是那些老操作,就不多说了,在这里我们可以看到它的url,在它的headers中
https://music.163.com/weapi/cloudsearch/get/web?csrf_token=
同时你也会发现你不断刷新,它的Form Data中的encSecKey与
params是在不断变化,并且是被加密过的,那我们就要找到它的加密过程了
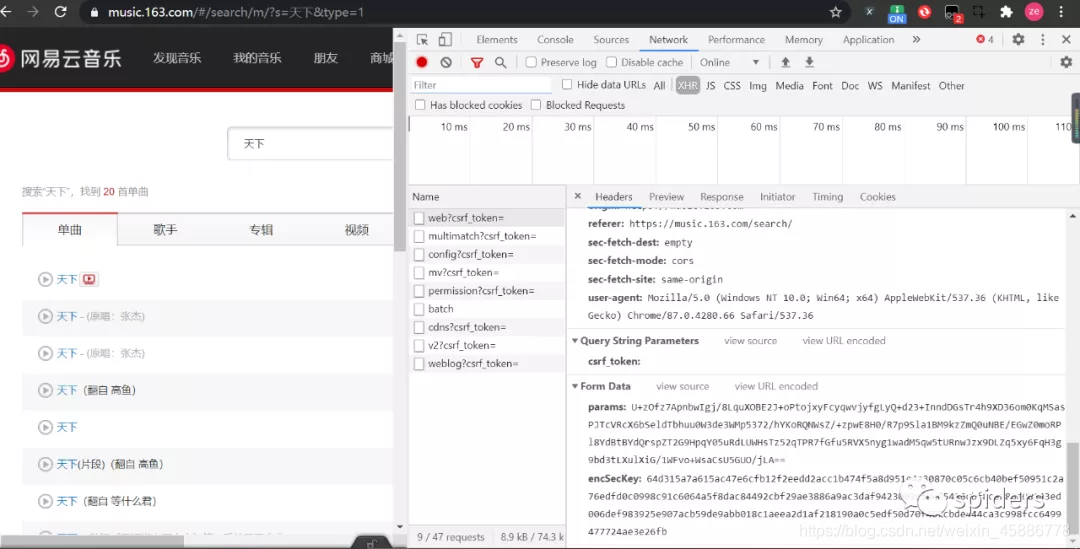
在这里我们复制一下encSeckey,当然也可以选择params,但会发现encSeckey是更简单的。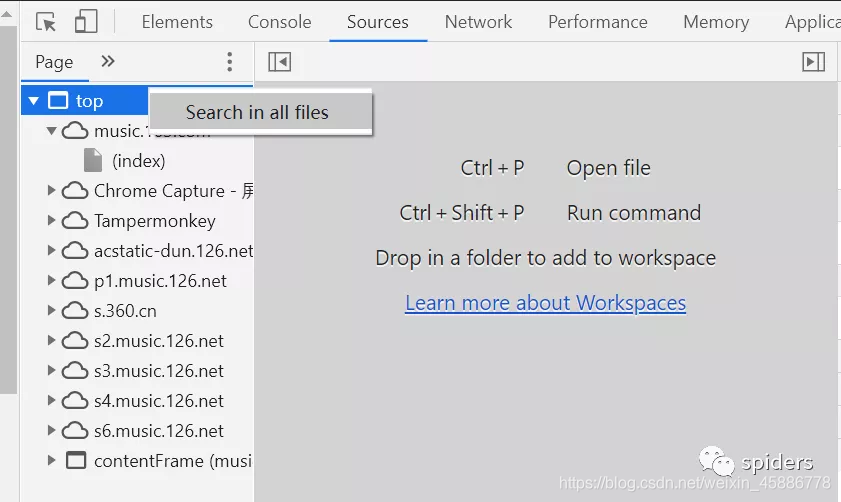
我们点击Sources,右击top进行全局搜索就好了。不要复制我这里的,复制浏览器里的。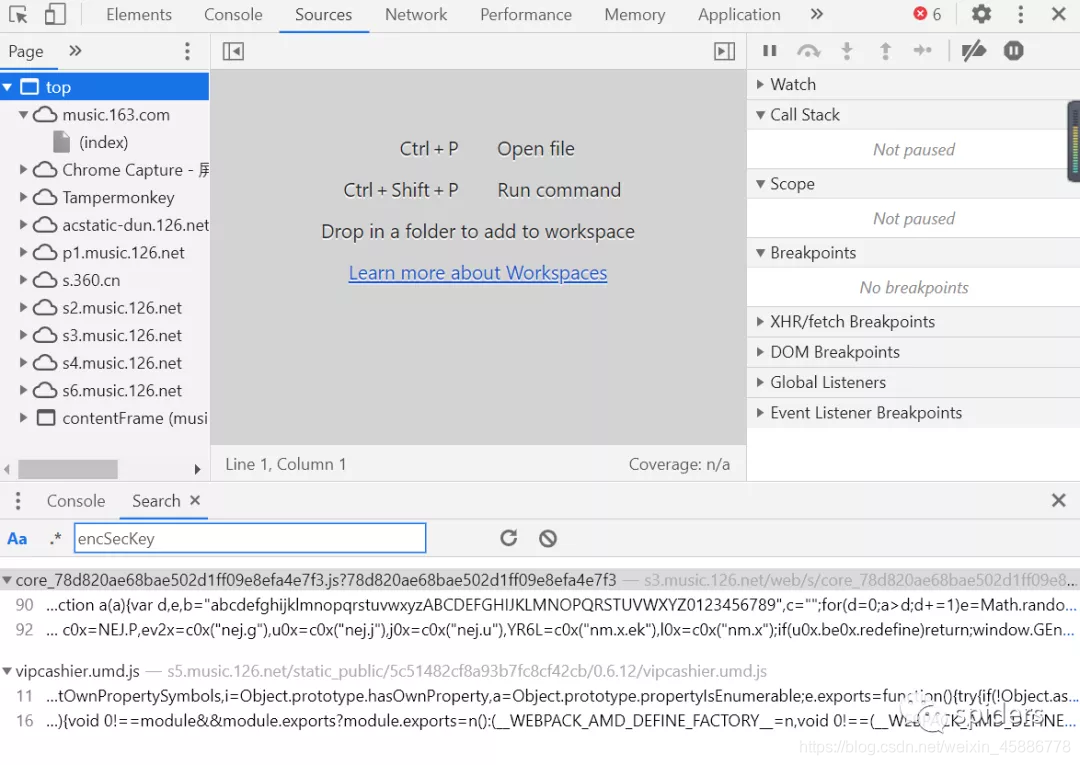
我们点92那个就好了,你也可以点90那个,其实都一样,不过不要点vip…那个文件里的,
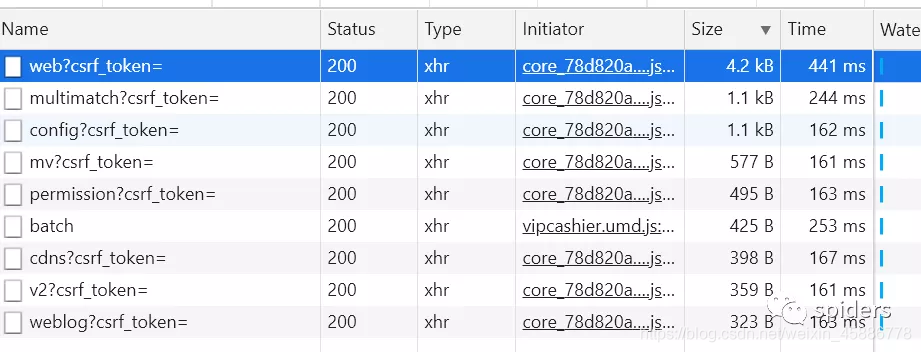
可以看到inittiator中文件都是core…,所以我们这里点core…文件中的,然后我们会看到这样的界面

我们点一下那个红色里面的括号,然后会看到下面的图,然后我们就crtl+f一下,再把encSecKey复制就会自动搜索我们想要的字符
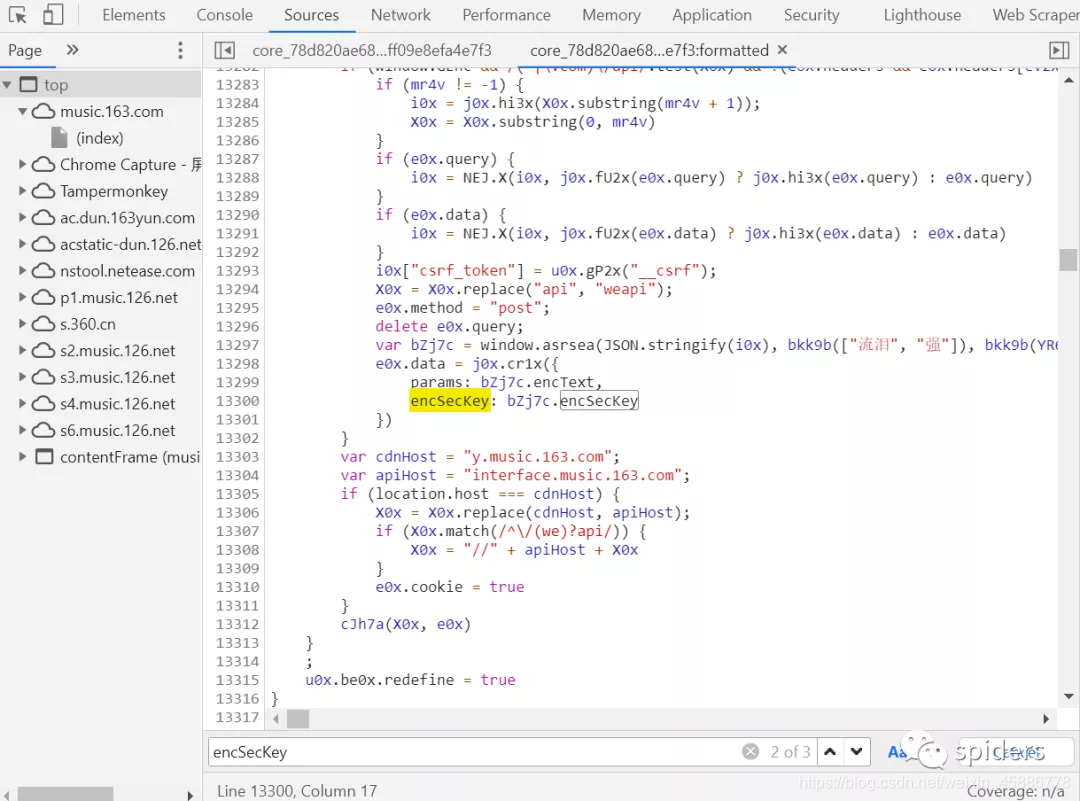
我们可以看到有3个该字符,那个2 of 3中3代表有几个,2代表是第二个,在这里我们可以看到params与enseckey两个参数。
var bZj7c = window.asrsea(JSON.stringify(i0x), bkk9b(["流泪", "强"]), bkk9b(YR6L.md), bkk9b(["爱心", "女孩", "惊恐", "大笑"]));
e0x.data = j0x.cr1x({
params: bZj7c.encText,
encSecKey: bZj7c.encSecKey
})
}
我们可以看到它是由下面代码传入参数,加密出来的,我们继续找。
var bZj7c = window.asrsea(JSON.stringify(i0x), bkk9b(["流泪", "强"]), bkk9b(YR6L.md), bkk9b(["爱心", "女孩", "惊恐", "大笑"]));
这里我们可以找window.asrsea这个参数,然后用上面那个crtl+f查找。会发现 window.asrsea = d

那个function d里面有4个参数,window.asrsea也有4个参数,这是对应的,我们可以看到里面有a(16),b(h.encText, i),b(d,g),c(i,e,f),这里b函数用了2次
我们再找一下这些函数,我们往上一拉,可以看到a,b,c3个函数,它们的参数数量是对应的。
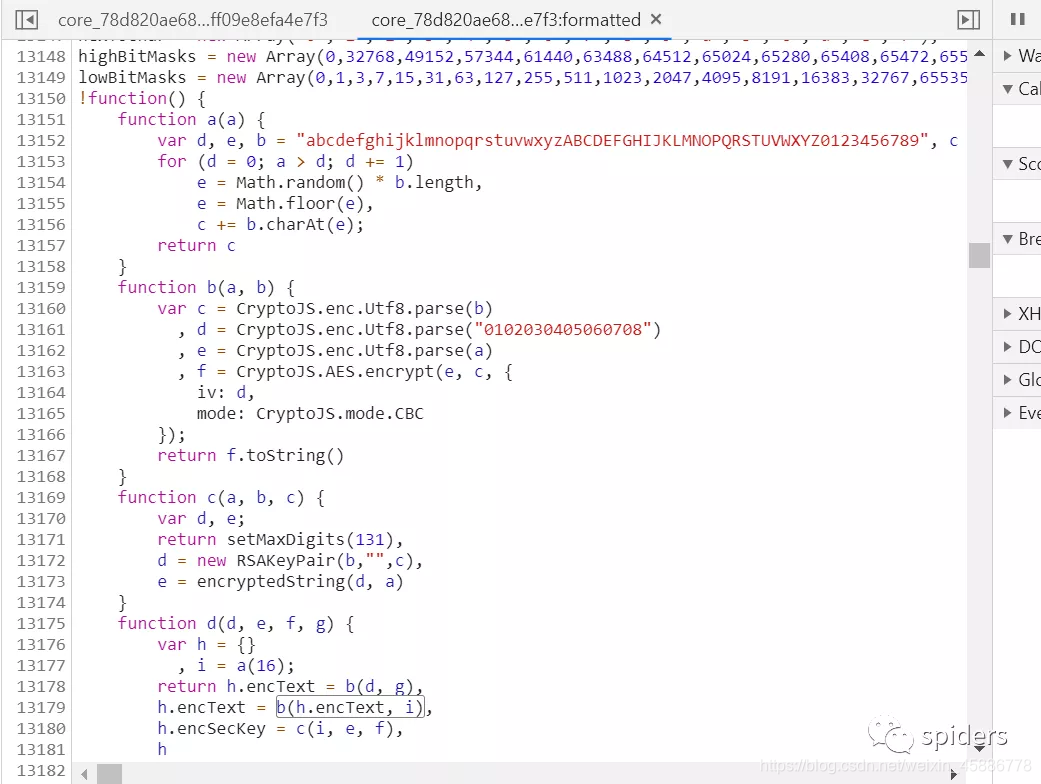
我们可以看出a函数是随机获取16位的值,并且在b,c函数中会用到,b函数是用AES中的CBC加密的,d位偏移量,e与c分别对应明文与秘钥了,下面会详讲。
对应c函数其实是RSA加密,相对好分析,代码里详细讲解
(JSON.stringify(i0x), bkk9b(["流泪", "强"]), bkk9b(YR6L.md)
, bkk9b(["爱心", "女孩", "惊恐", "大笑"]))
我们看一下d函数中四个参数会发现后面3个参数是固定的

红圈中的就是下面的东东
YR6L.emj = {
"色": "00e0b",
"流感": "509f6",
"这边": "259df",
"弱": "8642d",
"嘴唇": "bc356",
"亲": "62901",
"开心": "477df",
"呲牙": "22677",
"憨笑": "ec152",
"猫": "b5ff6",
"皱眉": "8ace6",
"幽灵": "15bb7",
"蛋糕": "b7251",
"发怒": "52b3a",
"大哭": "b17a8",
"兔子": "76aea",
"星星": "8a5aa",
"钟情": "76d2e",
"牵手": "41762",
"公鸡": "9ec4e",
"爱意": "e341f",
"禁止": "56135",
"狗": "fccf6",
"亲亲": "95280",
"叉": "104e0",
"礼物": "312ec",
"晕": "bda92",
"呆": "557c9",
"生病": "38701",
"钻石": "14af6",
"拜": "c9d05",
"怒": "c4f7f",
"示爱": "0c368",
"汗": "5b7a4",
"小鸡": "6bee2",
"痛苦": "55932",
"撇嘴": "575cc",
"惶恐": "e10b4",
"口罩": "24d81",
"吐舌": "3cfe4",
"心碎": "875d3",
"生气": "e8204",
"可爱": "7b97d",
"鬼脸": "def52",
"跳舞": "741d5",
"男孩": "46b8e",
"奸笑": "289dc",
"猪": "6935b",
"圈": "3ece0",
"便便": "462db",
"外星": "0a22b",
"圣诞": "8e7",
"流泪": "01000",
"强": "1",
"爱心": "0CoJU",
"女孩": "m6Qyw",
"惊恐": "8W8ju",
"大笑": "d"
};
YR6L.md = ["色", "流感", "这边", "弱", "嘴唇", "亲", "开心", "呲牙", "憨笑", "猫", "皱眉", "幽灵", "蛋糕", "发怒", "大哭", "兔子", "星星", "钟情", "牵手", "公鸡", "爱意", "禁止", "狗", "亲亲", "叉", "礼物", "晕", "呆", "生病", "钻石", "拜", "怒", "示爱", "汗", "小鸡", "痛苦", "撇嘴", "惶恐", "口罩", "吐舌", "心碎", "生气", "可爱", "鬼脸", "跳舞", "男孩", "奸笑", "猪", "圈", "便便", "外星", "圣诞"]
}
我们发现后面3个参数都用到bkk9b这个函数,我发现了这个函数
var bkk9b = function(cJj7c) {
var m0x = [];
j0x.bf0x(cJj7c, function(cJi7b) {
m0x.push(YR6L.emj[cJi7b])
});
return m0x.join("")
};
其实就是遍历然后,把它们叠合在一起。很容易实现
代码实现:
这里我是仅仅分析a,b,c,d函数,里面用到的一些其他自定义函数看全部代码
在这里我们要用到pycryptodomex库,用一下下面指令就好
pip install pycryptodomex
首先是a函数,这个根据js文件中还原就好,没有什么难度
def a(slef, n=16):
b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
c = ""
for i in range(n):
e = random.random() * len(b)
e = math.floor(e)
c += b[e]
return c
对于b函数,这里的明文要转换为16字节,并且那个秘钥(key)与偏移量(iv)要变成16位数的,想知道更具体可以百度
def AES_encrypt(self, text, key, iv):
# 需要将data转换为byte再来做填充,否则中文特殊字符等会报错
pad = lambda data: data + (16 - len(data.encode('utf-8')) % 16) * chr(16 - len(data.encode('utf-8')) % 16)
data = pad(text)
encryptor = AES.new(key=self.to_16(key), mode=AES.MODE_CBC, iv=self.to_16(iv))
encrypt_aes = encryptor.encrypt(data.encode('utf-8'))
encrypt_text = base64.encodebytes(encrypt_aes)
enctext = encrypt_text.decode('utf-8')
return enctext
对于c函数,没有什么好说的,百度一下就知道了,用的是RSA加密。
def RSA_encrypt(self, text, pubKey, modulus):
text = text[::-1]
rs = int(codecs.encode(text.encode('utf-8'), 'hex_codec'), 16) ** int(pubKey, 16) % int(modulus, 16)
return format(rs, 'x').zfill(256)
对于c函数
def d(self):
data = {
}
iv = "0102030405060708" # 偏移量
g = self.fixed_parameter(["爱心", "女孩", "惊恐", "大笑"]) # key
i = self.a()
#h获取params
encText = str(self.dict)
encText = self.AES_encrypt(encText, g, iv)
params = self.AES_encrypt(encText, i, iv)
data['params'] = params
#获取encSecKey
b = self.fixed_parameter(["流泪", "强"])
c = self.fixed_parameter(
["色", "流感", "这边", "弱", "嘴唇", "亲", "开心", "呲牙", "憨笑", "猫", "皱眉", "幽灵", "蛋糕", "发怒", "大哭", "兔子", "星星", "钟情",
"牵手", "公鸡", "爱意", "禁止", "狗", "亲亲", "叉", "礼物", "晕", "呆", "生病", "钻石", "拜", "怒", "示爱", "汗", "小鸡", "痛苦", "撇嘴",
"惶恐", "口罩", "吐舌", "心碎", "生气", "可爱", "鬼脸", "跳舞", "男孩", "奸笑", "猪", "圈", "便便", "外星", "圣诞"])
encSecKey = self.RSA_encrypt(i, b, c)
data['encSecKey'] = encSecKey
return data
这个就是encSecKey与params的加密。这里的encSecKey其实一直是256位,而params位数会因为请求的东西不同而位数不同。我们可以用我们解析出来的python函数进行模拟加密对比,看输出的看位数以及形式,我感觉是很有效的。我用的是pycharm,可能输出的位数多4到8,那是因为换行符占位。
你会发现我d函数中有这样一个代码
encText = str(self.dict)
这个self.dict是什么呢,其实这个我们可以打断点调试出来,下面是我做的1视频,可以看一下怎么搞,因为电脑无录屏软件,我就用手机录的视频。
(这里没法看,可以在https://mp.weixin.qq.com/s/3AQUfcGk3fICWH60Popxiw
看)
csrf_token: ""
hlposttag: "</span>"
hlpretag: "<span class="s-fc7">"
limit: "30"
offset: "0"
s: "天下"
total: "true"
type: "1
经过多次寻找,dict就是它了,这里我说一下,在寻找评论,歌词时的dict也是这样找的,慢慢调试,它们可以调试出来的。但是对于评论爬取多页时会发现找到了dict,但是一直print重复的,那是因为offset这个也存在变化,这个我们可以用Fiddler进行输出,会用到浏览器中的console,这个我暂时没空搞,想知道的可以百度。
全部代码:
import base64
import codecs
import math
import time
import wordcloud
import random
from Cryptodome.Cipher import AES
import requests
class GetArgs():
def __init__(self, dict):
self.dict = dict
def fixed_parameter(self, list):
dic = {
"色": "00e0b",
"流感": "509f6",
"这边": "259df",
"弱": "8642d",
"嘴唇": "bc356",
"亲": "62901",
"开心": "477df",
"呲牙": "22677",
"憨笑": "ec152",
"猫": "b5ff6",
"皱眉": "8ace6",
"幽灵": "15bb7",
"蛋糕": "b7251",
"发怒": "52b3a",
"大哭": "b17a8",
"兔子": "76aea",
"星星": "8a5aa",
"钟情": "76d2e",
"牵手": "41762",
"公鸡": "9ec4e",
"爱意": "e341f",
"禁止": "56135",
"狗": "fccf6",
"亲亲": "95280",
"叉": "104e0",
"礼物": "312ec",
"晕": "bda92",
"呆": "557c9",
"生病": "38701",
"钻石": "14af6",
"拜": "c9d05",
"怒": "c4f7f",
"示爱": "0c368",
"汗": "5b7a4",
"小鸡": "6bee2",
"痛苦": "55932",
"撇嘴": "575cc",
"惶恐": "e10b4",
"口罩": "24d81",
"吐舌": "3cfe4",
"心碎": "875d3",
"生气": "e8204",
"可爱": "7b97d",
"鬼脸": "def52",
"跳舞": "741d5",
"男孩": "46b8e",
"奸笑": "289dc",
"猪": "6935b",
"圈": "3ece0",
"便便": "462db",
"外星": "0a22b",
"圣诞": "8e7",
"流泪": "01000",
"强": "1",
"爱心": "0CoJU",
"女孩": "m6Qyw",
"惊恐": "8W8ju",
"大笑": "d"
}
c = ""
for key in list:
c = c + dic[key]
return c
# 转成16位数
def to_16(self, key):
while len(key) % 16 != 0:
key += '\0'
return key.encode('utf-8')
# 对应a函数
def a(slef, n=16):
b = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
c = ""
for i in range(n):
e = random.random() * len(b)
e = math.floor(e)
c += b[e]
return c
# 对应js函数的b函数
def AES_encrypt(self, text, key, iv):
# 需要将data转换为byte再来做填充,否则中文特殊字符等会报错
pad = lambda data: data + (16 - len(data.encode('utf-8')) % 16) * chr(16 - len(data.encode('utf-8')) % 16)
data = pad(text)
encryptor = AES.new(key=self.to_16(key), mode=AES.MODE_CBC, iv=self.to_16(iv))
encrypt_aes = encryptor.encrypt(data.encode('utf-8'))
encrypt_text = base64.encodebytes(encrypt_aes)
enctext = encrypt_text.decode('utf-8')
return enctext
# 对应js函数中的c函数
def RSA_encrypt(self, text, pubKey, modulus):
text = text[::-1]
rs = int(codecs.encode(text.encode('utf-8'), 'hex_codec'), 16) ** int(pubKey, 16) % int(modulus, 16)
return format(rs, 'x').zfill(256)
#d函数
def d(self):
data = {
}
iv = "0102030405060708" # 偏移量
g = self.fixed_parameter(["爱心", "女孩", "惊恐", "大笑"]) # key
i = self.a()
encText = str(self.dict)
encText = self.AES_encrypt(encText, g, iv)
params = self.AES_encrypt(encText, i, iv)
data['params'] = params
b = self.fixed_parameter(["流泪", "强"])
c = self.fixed_parameter(
["色", "流感", "这边", "弱", "嘴唇", "亲", "开心", "呲牙", "憨笑", "猫", "皱眉", "幽灵", "蛋糕", "发怒", "大哭", "兔子", "星星", "钟情",
"牵手", "公鸡", "爱意", "禁止", "狗", "亲亲", "叉", "礼物", "晕", "呆", "生病", "钻石", "拜", "怒", "示爱", "汗", "小鸡", "痛苦", "撇嘴",
"惶恐", "口罩", "吐舌", "心碎", "生气", "可爱", "鬼脸", "跳舞", "男孩", "奸笑", "猪", "圈", "便便", "外星", "圣诞"])
encSecKey = self.RSA_encrypt(i, b, c)
data['encSecKey'] = encSecKey
return data
class Music():
def __init__(self):
self.url = 'https://music.163.com/weapi/cloudsearch/get/web?csrf_token='
self.headers = {
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36',
'Accept': '*/*',
'Referer': 'https://music.163.com/search/',
'Connection': 'keep-alive',
'cookie': '_iuqxldmzr_=32; _ntes_nnid=2c2050b762a20bec42d44b4ec9570db2,1596545803404; _ntes_nuid=2c2050b762a20bec42d44b4ec9570db2; WM_TID=P%2B9S%2BGxp32pBVAVRRQZqCt7Cgd%2BGver%2B; NMTID=00OeaJw_6w3Xsbamkk4mtz6A4aQ648AAAF0w8UCbA; WM_NI=uJgfo1tpOzmOzCi1zZbOYbXBDNPDlNewZXU3yQ3iumqfEggri%2BRhKdTEiIHOU2SXI3IuFjOG%2FKSi%2FAeBDlsY02AdcF3eDGC7oT5jbtTM7WD72FNddwZuZ8YelJFmI76NRXY%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eeb6f0659a86fca5cc6093928fa6d14e968e9eaeb547898f8190d24686b7a0a7cb2af0fea7c3b92ab796a987ee3bb8b0819bf045ba9da7d2f952a2919783db4a8892a0a5ef46a7a996b9d839bb8ffd8af867b3ba8b88e67aabf59e89ca70989ba7aacb4597ee9db9cc398bab8a8bce4ded959d8aae4ba79e8c8df253f4ee8f85e24ef1bb8ca8c23dad8cfb8be1809893f9b8c73df29a8285e77d9aab96d9dc6fb0968a8ecc3df6929eb9dc37e2a3; JSESSIONID-WYYY=C1rSDXpSvPOpS%2FNHFyKe%5Cw3yY4%2F5bq5ntcfQ2QEqxSCJxkrD1%5CYeJdAGWIQmJpUIY5%5CtjA3S%2FrCedOHlKjFkPy5X4Eje7wt%2BHzgrcVRV%2BmXMRO8G%5CsxeUd9MBwwvqzIuEbuJkpv9mv6bCvQBzI9bI1qQl8WnFzFvy5Z0SqVeIAGYexqB%3A1601034012504'
}
def search(self):
song_name = input("请输入歌曲名:")
song_dict = {
'csrf_token': "", 'hlposttag': '<span class="s-fc7">', 'limit': '30', 'offset': '0',
's': '{}'.format(song_name),
'total': 'true', 'type': '1'}
d = GetArgs(song_dict)
data = d.d()
reponse = requests.post(url=self.url, headers=self.headers, data=data)
dict = reponse.json()
music_list = dict['result']['songs']
self.select(music_list,song_name)
def select(self, music_list,song_name):
i = 0
for music in music_list:
print(i, music['name'], music['ar'][0]['name'], end='\n')
i += 1
num = int(input('请输入序号:'))
id = music_list[num]['id']
ids = music_list[num]['privilege']['id']
singer_name = music_list[num]['ar'][0]['name']
self.get_lyric(id,singer_name,song_name)
print('正在爬取评论')
self.get_comments(id,singer_name,song_name)
print('评论爬取成功')
print('正在下载歌曲')
self.download_song(ids,singer_name,song_name)
print('全部完成')
def download_song(self,ids,singer_name,song_name):
url='https://music.163.com/weapi/song/enhance/player/url/v1?csrf_token='
dict = {
'csrf_token': "", 'encodeType': "aac", 'ids': "[{}]".format(ids), 'level': "standard"}
d = GetArgs(dict)
data = d.d()
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36',
'origin': 'https://music.163.com',
'referer':'https://music.163.com/',
}
download_headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36',
}
#获取下载链接
response = requests.post(url=url,headers=headers,data=data)
json = response.json()
download_url = json['data'][0]['url']
#下载歌曲
download_response = requests.get(url=download_url,headers=download_headers)
content = download_response.content
name = song_name+'+'+singer_name+'.m4a'
with open(name, 'wb') as f:
f.write(content)
print("歌曲下载成功!")
def get_comments(self, id,singer_name,song_name):
def save_png():
name = song_name + ' ' + singer_name
path = name+'.text'
with open(path,'r',encoding='UTF-8') as f:
c=f.read()
w = wordcloud.WordCloud(width=1000,height=700,background_color='white',font_path='msyh.ttc')
png_path = name+'.png'
w.generate(c)
w.to_file(png_path)
def save_text(c):
name = song_name + ' ' + singer_name
text_path = name+'.text'
with open(text_path,mode='a', encoding='UTF-8') as f:
f.write(c)
url = 'https://music.163.com/weapi/comment/resource/comments/get?csrf_token='
headers = {
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36',
'Accept': '*/*',
'Referer': 'https://music.163.com/song?id={}'.format(id),
'Connection': 'keep-alive',
'cookie': '_iuqxldmzr_=32; _ntes_nnid=2c2050b762a20bec42d44b4ec9570db2,1596545803404; _ntes_nuid=2c2050b762a20bec42d44b4ec9570db2; WM_TID=P%2B9S%2BGxp32pBVAVRRQZqCt7Cgd%2BGver%2B; NMTID=00OeaJw_6w3Xsbamkk4mtz6A4aQ648AAAF0w8UCbA; WM_NI=uJgfo1tpOzmOzCi1zZbOYbXBDNPDlNewZXU3yQ3iumqfEggri%2BRhKdTEiIHOU2SXI3IuFjOG%2FKSi%2FAeBDlsY02AdcF3eDGC7oT5jbtTM7WD72FNddwZuZ8YelJFmI76NRXY%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eeb6f0659a86fca5cc6093928fa6d14e968e9eaeb547898f8190d24686b7a0a7cb2af0fea7c3b92ab796a987ee3bb8b0819bf045ba9da7d2f952a2919783db4a8892a0a5ef46a7a996b9d839bb8ffd8af867b3ba8b88e67aabf59e89ca70989ba7aacb4597ee9db9cc398bab8a8bce4ded959d8aae4ba79e8c8df253f4ee8f85e24ef1bb8ca8c23dad8cfb8be1809893f9b8c73df29a8285e77d9aab96d9dc6fb0968a8ecc3df6929eb9dc37e2a3; JSESSIONID-WYYY=C1rSDXpSvPOpS%2FNHFyKe%5Cw3yY4%2F5bq5ntcfQ2QEqxSCJxkrD1%5CYeJdAGWIQmJpUIY5%5CtjA3S%2FrCedOHlKjFkPy5X4Eje7wt%2BHzgrcVRV%2BmXMRO8G%5CsxeUd9MBwwvqzIuEbuJkpv9mv6bCvQBzI9bI1qQl8WnFzFvy5Z0SqVeIAGYexqB%3A1601034012504'
}
dict = {
'csrf_token': "", 'cursor': "-1", 'offset': "0", 'orderType': "1", 'pageNo': "1",
'pageSize': "20", 'rid': "R_SO_4_{}".format(id), 'threadId': "R_SO_4_{}".format(id)}
for page in range(1, 9):
d = GetArgs(dict)
data = d.d()
c=''
if page != 1:
cursor = self.timestamp_13() #13位时间戳
dict['cursor'] = cursor
dict['offset'] = str((page - 1) * 20)
dict['pageNo'] = str(page)
response = requests.post(url=url, headers=headers, data=data)
json = response.json()
if page == 1:
print('正在爬取第{}页评论'.format(page))
try:
comments_list = json['data']['hotComments']
# print(comments_list)
for i in comments_list:
c=i['content']
save_text(c)
print(i['content'])
except:
print('无评论!!!!!!!')
else:
print('正在爬取第{}页评论'.format(page))
try:
comments_list = json['data']['comments']
# print(comments_list)
for i in comments_list:
c=i['content']
save_text(c)
print(i['content'])
except:
print('无评论')
save_png()
def get_lyric(self, id,song_name,singer_name):
def save_text(c):
name = song_name + ' ' + singer_name
text_path = name+'lyric.text'
with open(text_path,mode='a', encoding='UTF-8') as f:
f.write(c)
url = 'https://music.163.com/weapi/song/lyric?csrf_token='
headers = {
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36',
'Accept': '*/*',
'Referer': 'https://music.163.com/song?id={}'.format(id),
'origin': 'https://music.163.com',
'Connection': 'keep-alive',
'cookie': '_iuqxldmzr_=32; _ntes_nnid=2c2050b762a20bec42d44b4ec9570db2,1596545803404; _ntes_nuid=2c2050b762a20bec42d44b4ec9570db2; WM_TID=P%2B9S%2BGxp32pBVAVRRQZqCt7Cgd%2BGver%2B; NMTID=00OeaJw_6w3Xsbamkk4mtz6A4aQ648AAAF0w8UCbA; WM_NI=uJgfo1tpOzmOzCi1zZbOYbXBDNPDlNewZXU3yQ3iumqfEggri%2BRhKdTEiIHOU2SXI3IuFjOG%2FKSi%2FAeBDlsY02AdcF3eDGC7oT5jbtTM7WD72FNddwZuZ8YelJFmI76NRXY%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eeb6f0659a86fca5cc6093928fa6d14e968e9eaeb547898f8190d24686b7a0a7cb2af0fea7c3b92ab796a987ee3bb8b0819bf045ba9da7d2f952a2919783db4a8892a0a5ef46a7a996b9d839bb8ffd8af867b3ba8b88e67aabf59e89ca70989ba7aacb4597ee9db9cc398bab8a8bce4ded959d8aae4ba79e8c8df253f4ee8f85e24ef1bb8ca8c23dad8cfb8be1809893f9b8c73df29a8285e77d9aab96d9dc6fb0968a8ecc3df6929eb9dc37e2a3; JSESSIONID-WYYY=C1rSDXpSvPOpS%2FNHFyKe%5Cw3yY4%2F5bq5ntcfQ2QEqxSCJxkrD1%5CYeJdAGWIQmJpUIY5%5CtjA3S%2FrCedOHlKjFkPy5X4Eje7wt%2BHzgrcVRV%2BmXMRO8G%5CsxeUd9MBwwvqzIuEbuJkpv9mv6bCvQBzI9bI1qQl8WnFzFvy5Z0SqVeIAGYexqB%3A1601034012504'
}
dict = {
"id": "{}".format(id), "lv": -1, "tv": -1, "csrf_token": ""}
d = GetArgs(dict)
data = d.d()
response = requests.post(url=url, headers=headers, data=data)
json = response.json()
try:
lrc = json['lrc']
lyric = lrc['lyric']
save_text(lyric)
print(lyric)
except:
print('该歌曲为纯音乐!')
def timestamp_13(self):
timestamp_13 = round(time.time() * 1000)
return str(timestamp_13)
music = Music()
music.search()
我展示一下我爬取的一个歌曲-------绿色:
词云图:

部分评论:
歌词:这里我说一下,这个括号的是歌词对应时间,我优酷想搞个播放器,让对时间显示对应歌词。
本文章仅仅用于学习,不得商业。