MapReduce框架
一 MapReduce概述
优点:1.海量数据离线处理 2.易开发 3.易运行
缺点:实时流计算
MapReduce计算框架,基于磁盘(硬盘)IO输入输出
我从磁盘上读取数据到内存中,计算,得出结果放到磁盘
spark计算框架 ,基于内存的(内存条) 很短的时间内,数据是直接到内存的,计算,结果返回
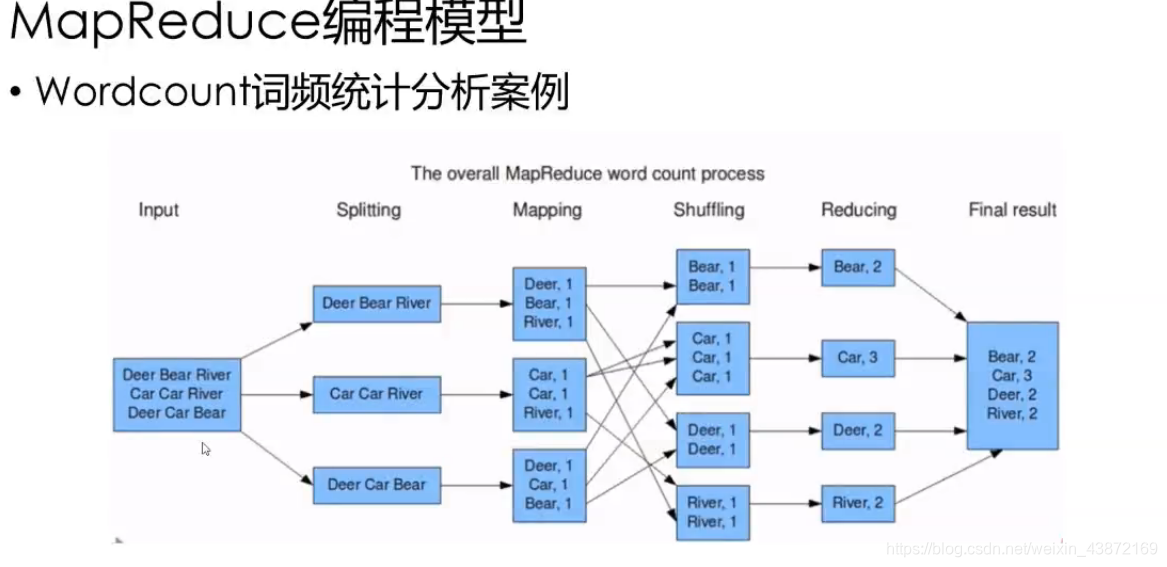
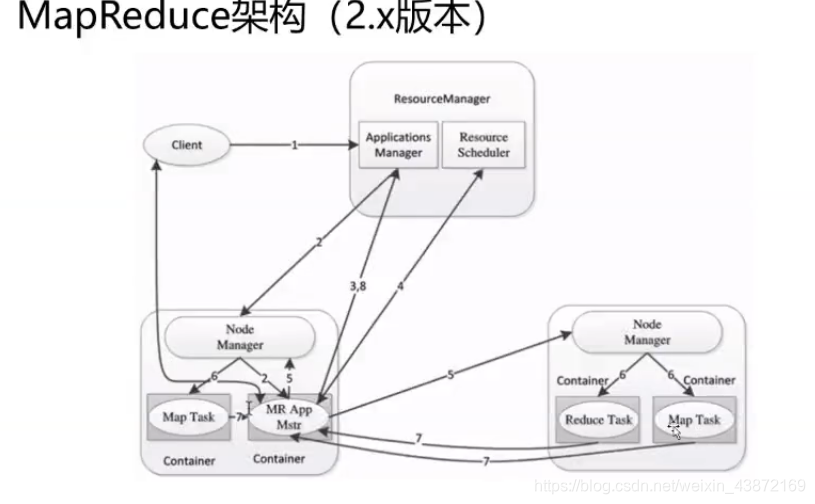
MapReduce编程之工作流程:
1.将作业拆分为Map阶段和Reduce阶段
2.Map阶段:Map Tasks
3.Reduce 阶段:Reduce Tasks



WordCount案例:统计文件中每个单词出现的次数
工作中很多场景都是源于这个案例
需求:1. 文件小的情况,shell脚本就可以解决
例如
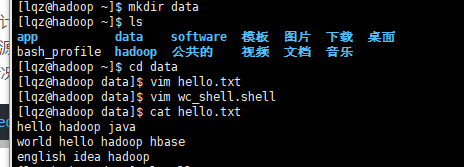
编写一个shell脚本,代码如下就可进行wordcount计算
cat hello.txt |sed 's/[,.:/!?]/ /g' |awk '{for(i=1;i<=NF;i++)array[$i]++;}END{for(i in array) print i,array[i]}'
权限不够要加执行权限!
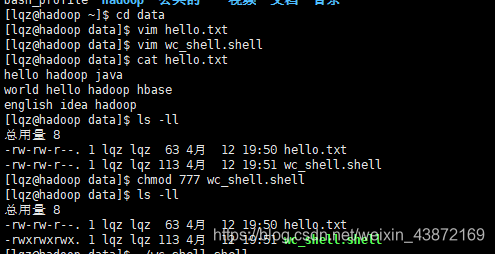
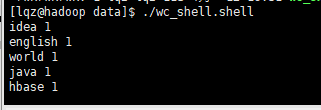
2.如果文件内容很大,1GB,1TB等许多大文件,就需要mapreduce分布式计算框架了,例如歌曲top100,热点等等
数据处理形式

MapReduce的处理用Writable进行处理封装
intput和output的形式都是kv键值对
k是偏移量,v是数值,例如input中,<k1,v1>如下所示
第一行:<1,15> 数值包括空格
第二行<16,13>
第三行<29,13>
<k2,v2>表示单词和1
<k3,v3>表示单词和数量
MapReduce处理过程
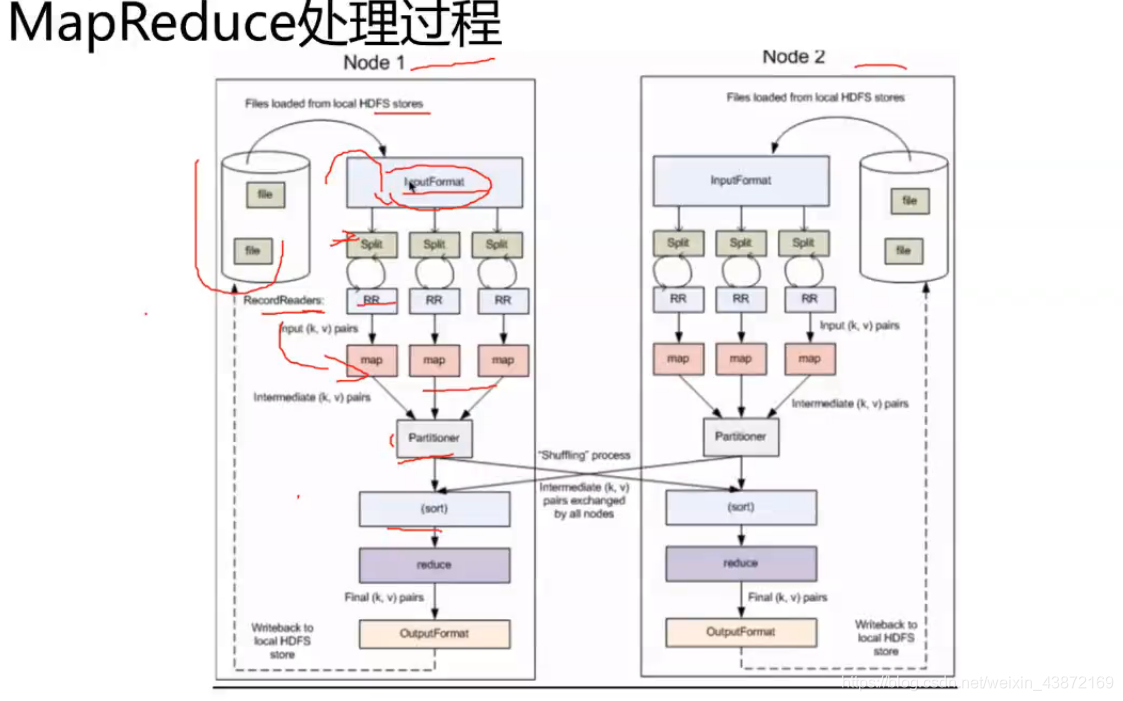
开发用类:
inputformat getsplits()来得到偏移量 RecoredReader()
outputformat getRecordWrite来写出
数据文件是放在HDFS系统上的,以块的形式存储,默认128M
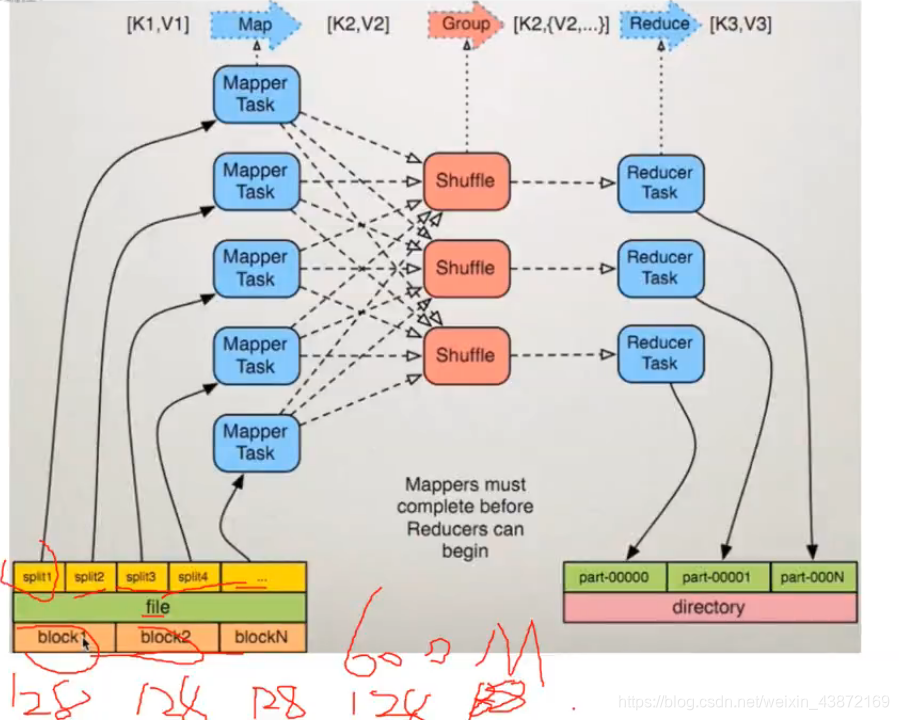
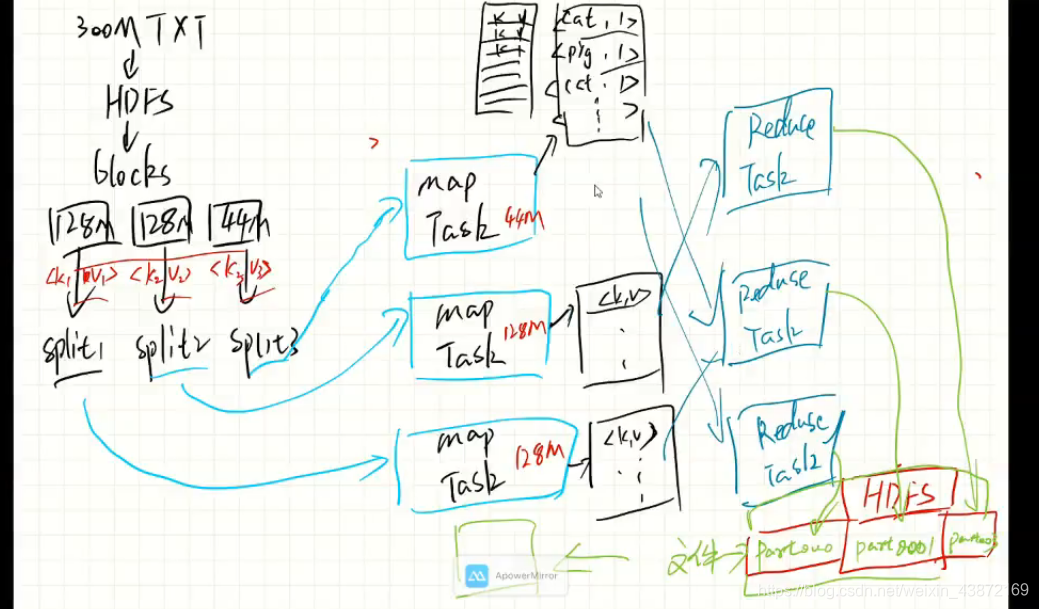
split:是MapReduce作业处理的数据块,是MapReduce中最小的计算单元,默认与block是默认对应的
本地编译步骤
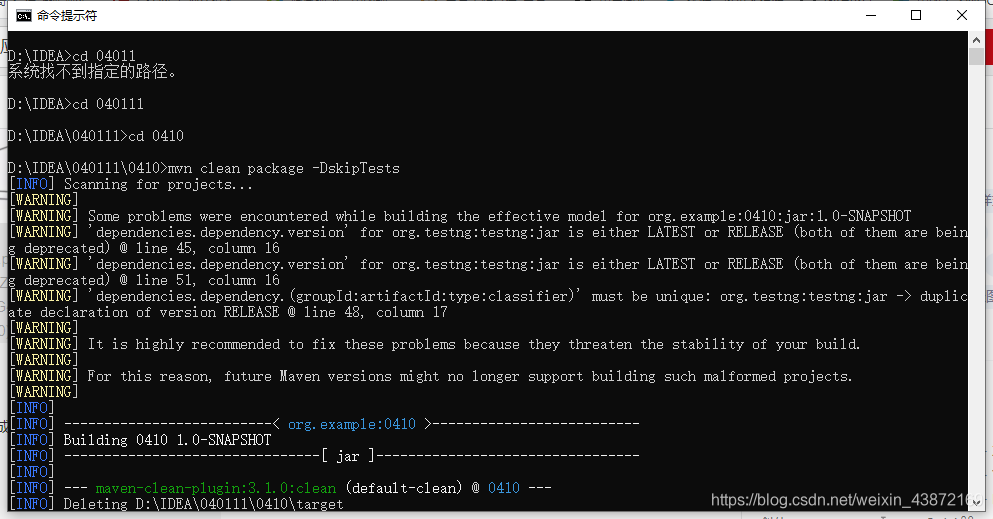
1.控制台切换到项目目录下
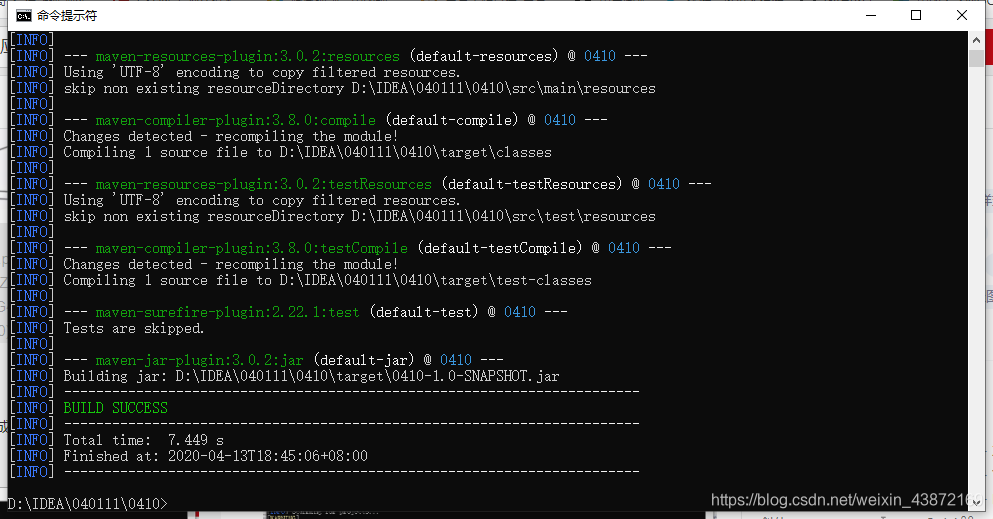
2.使用Maven命令进行编译,最终编译成jar包
命令:mvn clean package -DskipTests
然后上传到服务器上
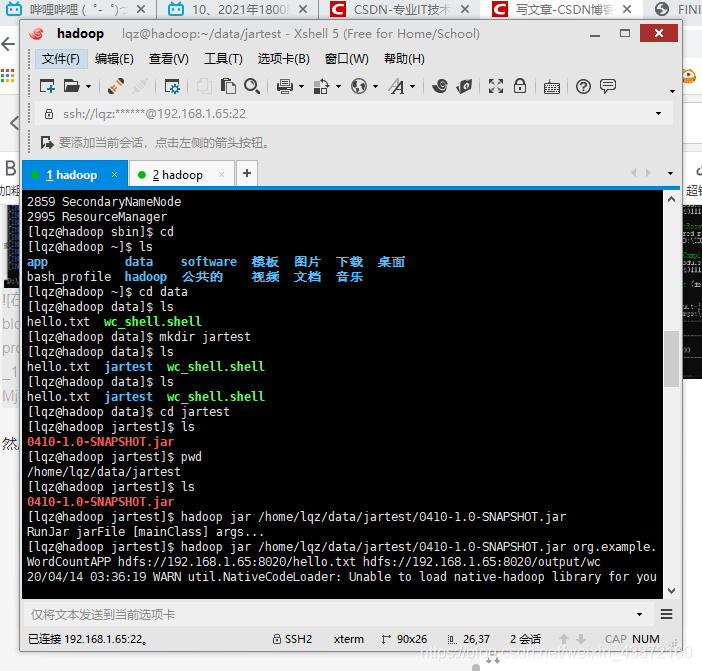
执行命令:
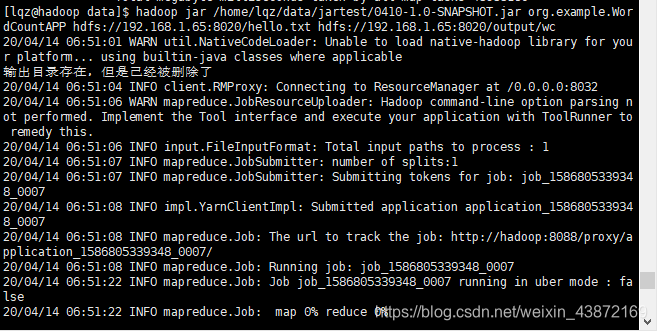
hadoop jar /home/lqz/data/jartest/0410-1.0-SNAPSHOT.jar org.example.
WordCountAPP hdfs://192.168.1.65:8020/hello.txt hdfs://192.168.1.65:8020/output/wc

hadoop fs -cat /output/wc/part-r-00000
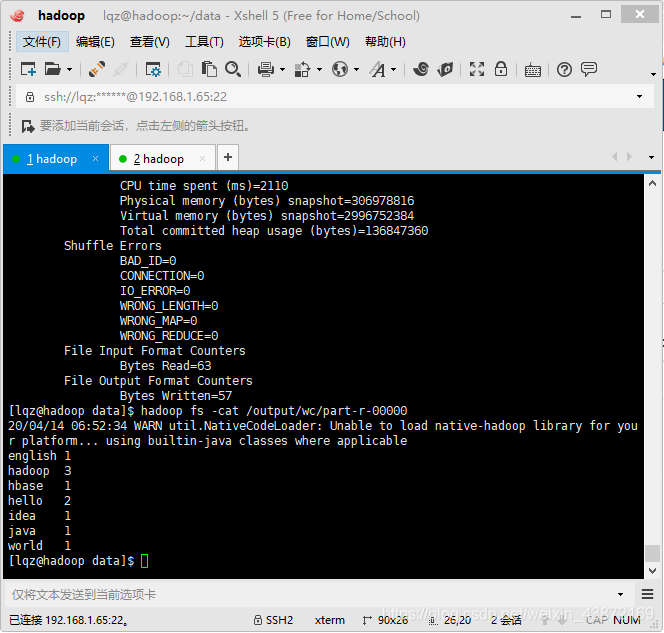
代码如下
package org.example;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* MapReduce 开发WordCount应用程序
* */
public class WordCountAPP {
/**
* map 读取输入的文件
* */
//int String String int
public static class MyMappter extends Mapper<LongWritable,Text,Text,LongWritable>{
LongWritable one = new LongWritable(1);//第一次是1
@Override //相当于输入一行的数据
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
LongWritable one = new LongWritable(1);//第一次是1
//接受一行的数据,转换成字符串
String lines = value.toString();
//拆分
String[] words = lines.split(" ");
//放在contest进行输出
for (String word:words
){
//把map的结果输出
context.write(new Text(word),one); //封装成 cat 1 pig 1
}
}
}
/**
* reduce处理,归并操作
* */
public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
@Override //下面是迭代的lingwritable集合
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum=0;
for (LongWritable value:
values){
//求key出现次数的总和
sum+=value.get();//得到value的值 <cat,1>==>1
}
//把结果输出
context.write(key,new LongWritable(sum));
}
}
/**
* 主方法
* Drive,封装了MapReduce作业的所有信息
* */
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//创建一个连接configuration
Configuration configuration= new Configuration();
//准备工作,清理已经存在的文件
Path outputpath=new Path(args[1]);
FileSystem fileSystem=FileSystem.get(configuration);
if (fileSystem.exists(outputpath)){
fileSystem.delete(outputpath,true);
System.out.println("输出目录存在,但是已经被删除了");
}
//创建一个job
Job job=Job.getInstance(configuration,"wordcount");
//设置处理那个类 告诉job要处理哪个类
job.setJarByClass(WordCountAPP.class);
//作业要处理数据的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));//路径是放到平台的,所以是通过传入参数形式
//map处理的相关参数
job.setMapperClass(MyMappter.class); //找到自己处理的类
job.setMapOutputKeyClass(Text.class);//设置输出的key类型
job.setMapOutputValueClass(LongWritable.class); //设置输出的value
//设置reduce相关参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置combiner 逻辑跟reduce一样
job.setCombinerClass(MyReduce.class);//相当于reduce后再加个reduce
//作业处理完后,数据输出的路径,
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//程序结束后,释放资源
System.exit(job.waitForCompletion(true)?0:1); //wait有两个异长,classnotfound和interrupt
}
}

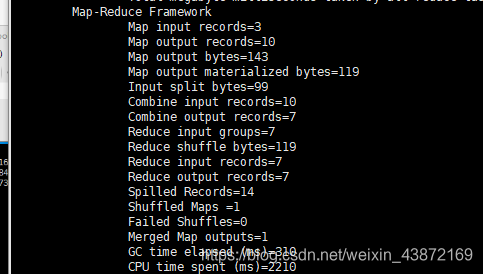
MapReduce编程之Combine
1.本地的reduce
2.减少Map Tasks输出的数据量及数据网络传输量
如图所示:在一台机器上先把重复的加和计算,在分给下一台机器
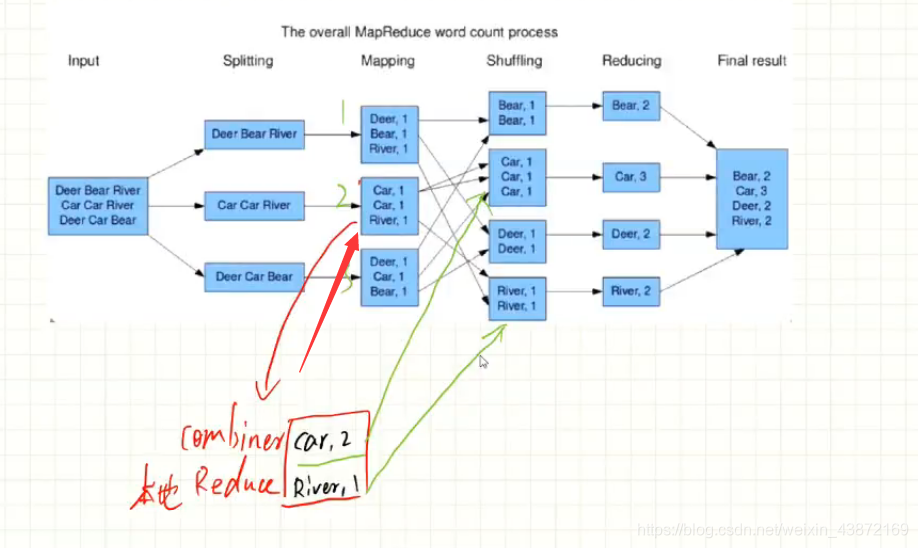
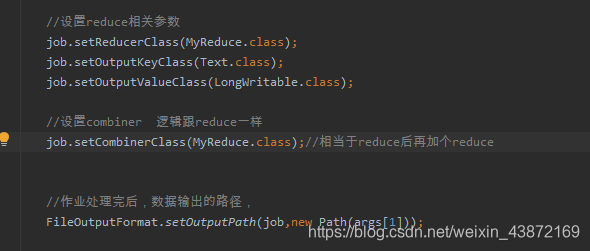
多了combine的操作
Mapreduce编程之partitioner
partitioner决定Map Task输出的数据交由那个Reduce Task处理
默认:分发key的hash值对Reduce Task个数取模

案例