Vector & ArrayList & LinkedList 详细分析
Ⅰ从面试出发
这篇文章我们先从一个面试问题出发,然后逐步详细分析这三个集合类的原理。
Q: 请你谈一谈,Vector, ArrayList, LinkedList 有什么区别?
下面的答案源引自极客时间,杨晓峰《Java核心技术面试精讲》。
A:
这三者都是实现集合框架中的 List,也就是所谓的有序集合,因此具体功能也比较近似,比如都提供按照位置进行定位、添加或者删除的操作,都提供迭代器以遍历其内容等。但因为具体的设计区别,在行为、性能、线程安全等方面,表现又有很大不同。
Vector是 Java 早期提供的线程安全的动态数组,如果不需要线程安全,并不建议选择,毕竟同步是有额外开销的。Vector 内部是使用对象数组来保存数据,可以根据需要自动的增加容量,当数组已满时,会创建新的数组,并拷贝原有数组数据。
ArrayList 是应用更加广泛的动态数组实现,它本身不是线程安全的,所以性能要好很多。与 Vector 近似,ArrayList 也是可以根据需要调整容量,不过两者的调整逻辑有所区别,Vector 在扩容时会提高 1 倍,而 ArrayList 则是增加 50%。
LinkedList 顾名思义是 Java 提供的双向链表,所以它不需要像上面两种那样调整容量,它也不是线程安全的。
从这个问答入手,这篇文章会延伸开三个方向。首先自然是牵扯到的数据结构与算法,其次就是 Java 集合框架的设计结构,最后是源码分析。
Ⅱ 相关数据结构与算法
Vector 和 ArrayList 都是用数组实现的,LinkedList是用链表实现的,关于基础的数据结构我不再赘述,想对这两个数据结构有进一步了解的同学可以跳转去看我下面的文章。
【数据结构与算法】->数据结构->链表->LRU缓存淘汰算法的实现
关于数组和链表。一定要明确它们的几个基础操作的时间复杂度,比如Access, Insert, Delet。
到这里自然是少不了基础的算法,基本的排序一定要清楚,特别是 O(nlogn) 的三个(堆排序,归并排序,快排),这三个排序不仅要很熟练地写出来,而且很多力扣题都可以用到这三种排序的思想,几个线性排序算其实用的也不多,不过在我刷力扣的时候也碰到了几个要用计数排序和桶排序思想的题,所以九种排序方法尽量还是要能熟练地写出来,最重点的就是 nlogn 的三个。
【数据结构与算法】->算法->排序(一)->冒泡排序&插入排序&选择排序
【数据结构与算法】->算法->排序(二)->归并排序&快速排序
【数据结构与算法】->算法->排序(三)->线性排序->桶排序&计数排序&基数排序
【数据结构与算法】->数据结构->堆(上)->详解堆&堆排序
排序除了要考虑到时间复杂度以外,还要清楚哪些排序是稳定的,哪些是不稳定的(快排,堆排,希尔,选择)。有篇文章整理的十大经典排序也非常好,大家可以看看。
关于排序这里再补充一点,就是我很多小伙伴去面试都被问到了大规模数据外部排序的问题。主要就是归并,快排这样的可以分割文件的算法,关于这部分内容我会再整理一篇文章出来。
其实数组的排序相对容易,链表的操作有时候会非常麻烦,力扣上有道关于链表的题非常好,我也是放在这里。
LRU Cache也算是链表的一个经典应用,要实现起来有两个思路,一个是手动实现一个双向链表 + HashMap,一个就是直接 extends 一个 LinkedHashMap 然后重写一个删除的方法就好了,这里我还是建议自己手动实现一个双向链表,可以向面试官体现自己的基本功。
还有一道题是 #155 最小栈,这道题基本思路就是建立一个普通数据栈,一个最小值的栈,然后两个栈一起配合完成最小栈的功能。但是这道题还有一个思路非常巧妙,就是实现了一个链表,通过维护这个链表就可以实现了,并不需要两个容器。所以说链表在实际应用中是非常灵活的,大家一定不要被限制了想象力。如果这道题用链表的方式实现的话,我相信面试官也会眼前一亮的。
代码我贴在下方。
private Node head;
public MinStack() {
}
public void push(int x) {
if (this.head == null) {
this.head = new Node(x, x);
} else {
this.head = new Node(x, Math.min(head.min, x), head);
}
}
public void pop() {
head = head.next;
}
public int top() {
return this.head.val;
}
public int getMin() {
return this.head.min;
}
class Node {
int val;
int min;
Node next;
public Node(int val, int min) {
this.val = val;
this.min = min;
this.next = null;
}
public Node(int val, int min, Node next) {
this.val = val;
this.min = min;
this.next = next;
}
}
在我还很菜的时候我做了一个链表的几道题的整理,当时以为拿下这几道题链表就OK了,没想到在后面的刷题中我被屡屡再教育,现在终于可以不随意被链表凌辱了。我还是先把我之前整理的链表的题放上来,后续我有时间的话一定会更新,因为链表的世界还非常非常大,这几道题绝对是不够的,但是帮助大家理解链表的几个操作是差不多的。
之前我做了一个社群分享,分享了我对链表的一些思考,也讲解了一道链表做插入排序的题,有兴趣的同学可以跳转再去看看。主要是因为指针是个比较麻烦的东西,有时候做出来的操作对不熟悉的人来说像是魔法一样,所以还是要勤于练习。
像链表其实可以扩展的内容很多,比如链表的一个优化,跳表是如何实现的,原理是什么。虽然应该不会有面试官让你手写一个跳表,不过基本的原理还是要清楚的。
由于数组和链表是最基础的数据结构,所以牵扯到的东西并不多,后续看到相关的我会再整理上来。
Ⅲ Java 集合框架设计结构
这里需要对 Java 的集合框架设计结构有个大致的印象,借杨老师的图一用。

这个图中并没有把 Map 加入,因为虽然在通常概念中会把 Map 当作集合框架的一部分,但是实际上它并不是真正的集合(Collections)。为避免混淆,JUC (java.util.concurrent)的容器也没有被放入,JUC 在后续的整理中我会单独列一篇文章。
可以看到,集合类的根是 Collection 接口,然后从 Collection 分支出了三大类,List, Set,Queue。由于这篇文章主要是分析 ArrayList 和 LinkedList,不再对其他的多做赘述,大家大概清楚这个体系结构就可以。需要注意的一点是 TreeSet 和 HashSet 都是继承了 HashMap,虽然名义上是 Set,但是内部还是用散列表实现的。
Ⅳ 源码分析
① ArrayList
首先来看 ArrayList,一个数据结构最基本的操作就是增删改查,ArrayList 作为一个数组的封装类,其实也没有什么独特的操作,比较简单。我们就着重看一下这几个基础的功能。
首先我们来看增添元素。就是数组的惯常操作,在数组的末尾添加数据并将尾部指针向后挪动一个,对应着 size++,这个size显然也是统计数组中元素个数的。

先忽略第一行的方法,再看一下指定下标的添加。

指定下标那显然要先检查下标合不合法,从第一行的方法名称上我们就可以知道这就是检查下标是否越界的。
紧接着我们又看到了第二行这个出现过一次的方法,执行完这个方法之后还是数组的惯常操作,先将要插入的下标的后面的元素整体后移,然后再将元素插入到对应的下标中。System.arraycopy() 就是从哪个数组,从哪里开始复制,复制到哪个数组,从哪里开始粘贴,复制的总长度是多少。
从这里也可以看到,数组的插入数据会牵扯到很多数据的迁移,这是非常耗费时间的。
现在我们来看看执行插入操作前执行的这个函数。
ensureCapacityInternal(size + 1);
从名字大概就可以猜到,这大概就是个计算数组容量够不够的方法。

可以看到,add方法调用了上面的那个方法ensureCapacityInternal(),传递的参数是size + 1,也就是要确保将要添加的元素是有空间可以添加的。
ensureCapacityInternal()方法又调用了下面的ensureExplicitCapacity() 方法,我们再看一下下面这个方法。
这个modCount++其实是记录一下操作数,并不是重点,我们可以直接看下面的if块,看这个意思大概就可以猜到这是判断现在的空间大小够不够,如果不够就进行 grow() 扩容。确保插入之前数组的大小是足够的。
我们先来看一下这个grow() 方法,

可以看到我圈起来的这行,看变量名就很清楚了,新空间的大小是旧空间大小的1.5倍,也就是增加了 %50 的空间。
对比一下Vector的扩容:

capacityIncrement是可以设置的,默认是0,由此可以看到Vector的默认扩容是就是两倍。
我们知道数组和链表最大的一个区别就是数组是固定长度的,而链表的长度是不固定的,可以随时增加。而由于数组的内存空间是连续的,所以每次都要初始化一个固定长度的连续空间。
在操作ArrayList时,我们可以随意增加数据,好像这是一个无限长的数组一样。实质上,ArrayList 就是封装起来了数组的扩容过程,当原先申请的空间不够了,就再申请一个更大的,从而时操作这个类的用户不需要去想数组大小的事情,这就是OOP封装的力量。我们在写面向对象的程序的时候,要尽量摒弃面向过程的思考习惯。
在ArrayList的扩容里,我们还可以看到一个方法。

这个方法显然是要计算数组现在的容量大小的。

可以看到这个方法要先检查要判断空容量大小的这个数组是不是等于DEFAULTCAPACITY_EMPTY_ELEMENTDATA,如果相等,这个数组的容量就是DEFAULT_CAPACITY 和传进来的需要的数组大小取最大值。
先来看DEFAULTCAPACITY_EMPTY_ELEMENTDATA。

显然它就是个空数组,那它在什么时候调用呢?

这就是我们用无参构造写一个ArrayList之后,会生成一个空数组,这是自然的,很好理解。

那DEFAULT_CAPACITY 就是默认的初始数组容量的大小,是10,所以才有上面那个方法的比较。
所以我们可以看到,如果初始化的时候没有注明容量大小,就会默认是10,之后数据量如果超过10的时候,就会执行grow() 方法,重新申请一个更大的数组,一般来说是1.5倍。如果数据量又超了,又要执行一次这个 O(n) 的操作。这也是很多数据结构封装类的默认设置,因此在确定数据量大小的前提下,尽量初始化容量大小,这样会避免很多无意义且浪费时间的扩容操作。 大家如果用了阿里巴巴的编程规范插件,就可以看到有时候它就会提示你把容量大小写上,这是一个很好的习惯。同样的比如HashMap的初始大小就是16。
关于ArrayList的删除操作,也有个值得注意的地方。


我们知道ArrayList是有泛型的,再删除时可以不按下标删,比如下面重载后的方法,就是直接删除指定的元素。而普通的删除是按照传进去的 int类型的下标删除。
所以这里一定要注意,如果你的 list 里封装的是 Integer类型的数据,在方法调用的时候是会自动拆箱的,你可能想删除的是一个Integer的对象,最后却是按照下标删除的。
ArrayList没有太多需要注意的地方,就分析到这里吧。
② LinkedList
我们先来看一个普通的LinkedList是怎么实现的。在力扣里随便找个链表题,就能看到一个几乎都一样的模板

这就是Java里链表的一个结点的基本结构,通过next成员(也就是指针)连接在一起,这就形成了一个链表。
好,那我们再来看看LinkedList。
看源码的时候首先先打开结构图,大致看一下这个类里都有什么方法,或者内部类。

首先映入眼帘的就是一个 Node 内部类。

果然随便一看就知道了,Node就是链表中一个结点的定义。不同于我们一开始给出的例子,它除了有next成员之外,还有prev成员,这就很清晰了,这个链表一定是一个双向链表。

再滑到上面一看成员,它不仅是个双向链表,还有头结点和尾结点,显然就是既可以从头部增删结点,也可以从尾部增删结点。所以这也是LinkedList比普通的链表效率的优化之处。
还是一样的,我们只关注几个基本的操作。
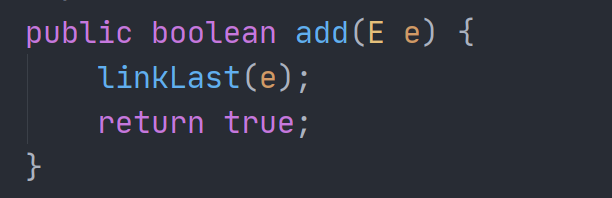
可以看到,当没有指明要插入的方向的时候,链表默认实现的是插入到尾部。

这几行代码也是链表的常规操作,首先判断尾部的结点是否为空,如果是空的话,就将新的结点设置为首结点,否则就将新结点插在原来的尾结点的后面,并将新的结点设置成为尾结点。
那我们再来看看删除操作。
/**
* Removes the first occurrence of the specified element from this list,
* if it is present. If this list does not contain the element, it is
* unchanged. More formally, removes the element with the lowest index
* {@code i} such that
* <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>
* (if such an element exists). Returns {@code true} if this list
* contained the specified element (or equivalently, if this list
* changed as a result of the call).
*
* @param o element to be removed from this list, if present
* @return {@code true} if this list contained the specified element
*/
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
删除的方法我们从变量名拿不准到底是删的元素第一次出现的结点还是最后一次,这时候就要看一下注释了。其实源码中写的英语都不难,如果遇到困难就看一下翻译,这样对具体的功能也有个了解。可以看到,这里实现的是要删除元素第一次出现的结点。
这里有个很细节的地方,我觉得一般人敲代码是很难想到这里的,就是对要删除的对象为null时的处理。

源码里还做了一遍检测,如果链表中有结点的值就是null,那就会删除那个结点。这样检查完之后,确认确实没有这个结点,才会返回false,这种细节就是我们需要学习的地方。
大致扫了一下LinkedList中的方法

可以看到,LinkedList提供的接口又有offer(),又有push(),还有peekFirst()指类的,经常练习数据结构的朋友一定对这些接口很熟悉,正是因为这些接口,像Stack, Queue, Dequeue这些数据结构都可以被LinkedList所实现,回想ArrayList也是同样的。这恰好就说明了所有的高级数据结构,本质上都是链表和数组,只是在对它们进行了不同方式的优化和再实现,因为内存就是一维的,你要么申请连续的内存空间,那就是一个数组的数据结构,要么申请不连续的,那就是个链表的数据结构。清楚了这些共性,我们才能戒掉对高级数据结构的恐惧,无非链表、数组而已。
Ⅴ 总结
最后我再对这三个类做一个总结。
Vector、ArrayList、LinkedList均为线型的数据结构,但是从实现方式与应用场景中又存在差别。
1、底层实现方式
ArrayList内部用数组来实现;LinkedList内部采用双向链表实现;Vector内部用数组实现。
2、读写机制
ArrayList在执行插入元素是超过当前数组预定义的最大值时,数组需要扩容,扩容过程需要调用底层System.arraycopy()方法进行大量的数组复制操作;在删除元素时并不会减少数组的容量(如果需要缩小数组容量,可以调用trimToSize()方法);在查找元素时要遍历数组,对于非null的元素采取equals的方式寻找。
LinkedList在插入元素时,须创建一个新的Entry对象,并更新相应元素的前后元素的引用;在查找元素时,需遍历链表;在删除元素时,要遍历链表,找到要删除的元素,然后从链表上将此元素删除即可。
Vector与ArrayList仅在插入元素时容量扩充机制不一致。对于Vector,默认创建一个大小为10的Object数组,并将capacityIncrement设置为0;当插入元素数组大小不够时,如果capacityIncrement大于0,则将Object数组的大小扩大为现有size+capacityIncrement;如果capacityIncrement<=0,则将Object数组的大小扩大为现有大小的2倍。
3、读写效率
ArrayList对元素的增加和删除都会引起数组的内存分配空间动态发生变化。因此,对其进行插入和删除速度较慢,但检索速度很快。
LinkedList由于基于链表方式存放数据,增加和删除元素的速度较快,但是检索速度较慢。
4、线程安全性
ArrayList、LinkedList为非线程安全;Vector是基于synchronized实现的线程安全的ArrayList。
需要注意的是:单线程应尽量使用ArrayList,Vector因为同步会有性能损耗;即使在多线程环境下,我们可以利用Collections这个类中为我们提供的synchronizedList(List list)方法返回一个线程安全的同步列表对象。