实践目的
通过操作一个开源例子,学习大数据的架构 及基本的使用,各种概念。不涉及自编码与创新。
环境搭建
需要建立 hadoop,hbase ,spark 等大数据环境
在10.30.2.5上建立六个docker , 分别对应 s141~s146 分别用于装大数据环境,具体操作步骤 参考本人
hadoop-spark
https://blog.csdn.net/dualvencsdn/article/details/112007643?spm=1001.2014.3001.5501
habase
https://blog.csdn.net/dualvencsdn/article/details/112905925?spm=1001.2014.3001.5501
学会操作hbase
https://blog.csdn.net/dualvencsdn/article/details/113309385?spm=1001.2014.3001.5501
flume初步学习与使用
https://blog.csdn.net/qq_1018944104/article/details/85462011
/usr/local/flume/do.sh
kafka与zookeeper的使用与编程
成果展现
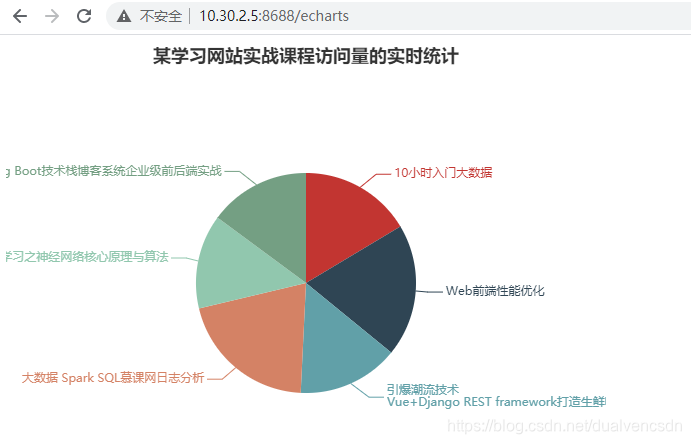

操作记录

/home/dualven/docker/*.jar
start.sh -->start dockers
appendHost.sh-> add host ip for six hosts
seeMessage.sh ->see the message consumed by kafka

docker exec -it centos1122 bash
cd /usr/local/
see readme.txt
代码
https://codechina.csdn.net/dualvenorg/sparkstreaming.git