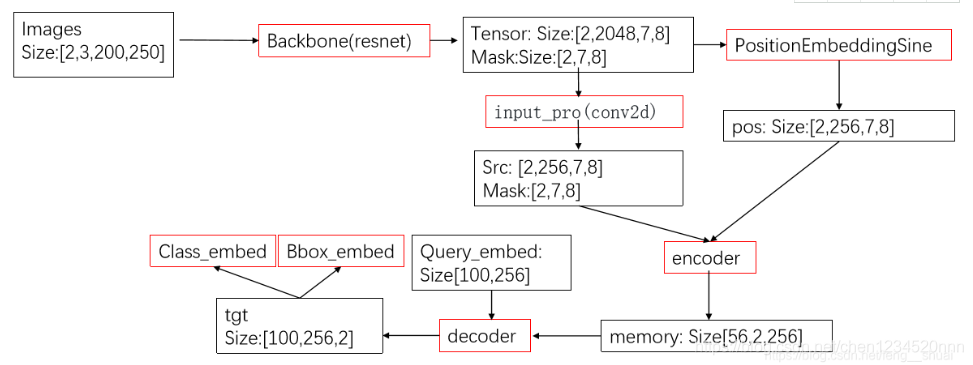
![]()
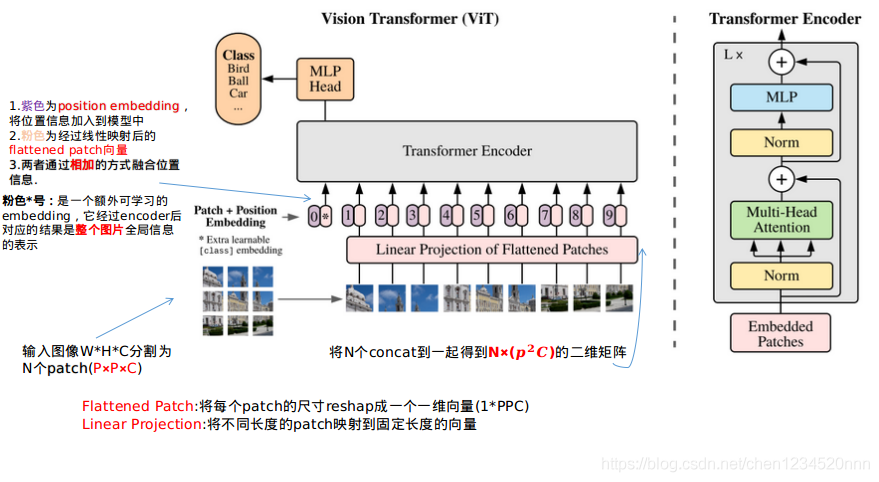
:是图像分割出的N个patch embedding,尺寸维度
。(该步即是将图像分割为N个patch)
E:是线性映射矩阵,维度为;上面的
右乘线性矩阵E,就将
都固定成D维向量。(该步即是将每个patch embedding线性映射到固定维度)
:是Learnable embedding,也是一个D维向量,它和
concat就得到了(1+N)×D维矩阵。(该步是加上一个可学习的embedding表示全局图像信息)
:是(1+N)个D维position embedding,position embedding相加上面的结果,即得到了encoder的原始输入
。(该步是给embedding加上位置信息)
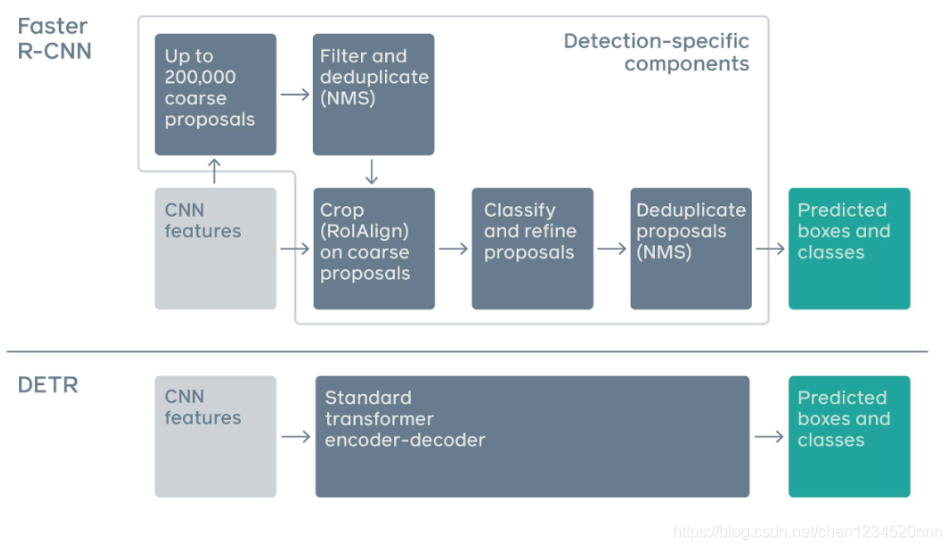
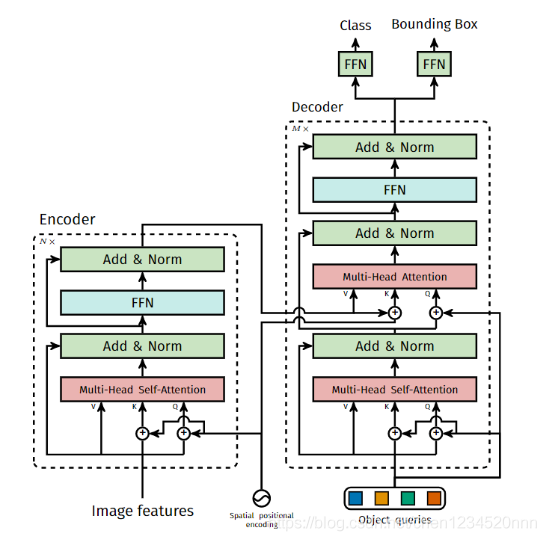
DETR 对目标和全局图像背景的关系作出推理,从而直接并行输出最终的预测集
Encoder最后得到的结果是对N个物体编码后的特征
DETR Decoder的结构也与Transformer类似,每个Decoder有两个输入:一个是Object Query(或者是上一个Decoder的输出),另一个是Encoder的结果,区别在于这里是并行解码N个object。与原始的transformer不同的地方在于decoder每一层都输出结果,计算loss。另外一个与Transformer不同的地方是,DETR的Decoder和encoder一样也加入了可学习的positional embedding,其功能类似于anchor。最后一个Decoder后面接了两个FFN,分别预测检测框及其类别。