BiSeNet
本文出自华中科技大学、北京大学名下,于2018年ECCV发表。
引言
丰富的空间信息和足够大的感知域是语义分割任务所必须的两个点。然而现在的方法并不能得到很好的效果。在本篇论文中,使用新颖的双向分割网络(Bilateral segmentation Network)就能解决这个困境。首先,设计一个小步长的空间路径来保留空间信息并且产生高分辨率的特征,设计一个快速下采样的上下文路径获取足够大的接受域。在这两个路径的顶部,我们设计了一个新的特征融合模块来更好的结合有效的特征。这个结构有效的平衡处理速度和模型的分割效率之间的关系。特别说明:对于2048和1024的输入,使用Titan XP的NVIDIA处理器,在Cityscapes数据集上实现了68.4%的 Mean IOU,105FPS,在表现不下降的前提下,比现有的模型都快!
简介
语义分割的研究是计算机视觉中的一项基本任务,它相当于给每个像素分配语义标签。 可广泛应用于增强现实设备,自主驾驶,视频监控等领域。 这些应用对快速交互或响应的高效推理速度有很高的要求。
模型一类
对于实时分割任务,处理速度是一个很关键的步骤和要求,所以在此之前的模型中有这样几种现象:1、对图像进行resize以减少计算代价。2、对网络的通道数进行调整,从而减少参数、减少计算量提升效率。3、Enet直接将模型的最后一步下采样舍弃,从而大大减少计算代价。第一种会破坏图像的空间信息,使得边界预测无法进行。第二种办法会减少模型的空间信息学习度。最后一种干脆,但是对于大的目标对象,模型的接受域太小!
具体见图一(a)!!
模型二类
在这里重点指出了U-shape Structure的优点,能够增加空间分辨率并且填补更多的细节。缺点:计算量大、下采样过程中的信息损失并不能通过简单的skip connnection来进行恢复。如图一(b)!
本文提出的模型
BiSeNet的两部分:Spatial Path、Context Path。
两个部分分别针对空间信息和感受野而设计。对于Spatial Path而言,我们只堆叠了三个卷积层来获取原图像1/8 大小的特征图,在这个特种图例包含了充足的空间细节。而对于Context Path,我们在Xception分离卷积的基础上增加了一个平均池化层,这样就能得到更大的感受野,在图一(c)种有详细的结构!
在保持效率的前提下最求更好的结果,本文研究了两种Path的融合以及最终预测结果的改进并分别提出了Feture Fusion Module和Attention Refinement Module模块。这两个模块对于提高模型的分割准确度可以起到很好的作用!

本文所作贡献
1、提出了一个新的模型 BiSeNet
2、提出了两个特殊的模块 FFM ARM
3、模型的泛化性能好,在三个数据集上取得了非常好的结果,并且速度很快!
相关工作
上下文信息
本文种提到了空间金字塔池化使用不同大小的卷积核来提取图像的上下文信息,然后使用全局平均池化来获取自适应的上下文信息感受野。如DFN利用全局平均池化,来对整个全局的上下文信息进行编码。
注意力机制
注意力机制能够使用高水平的信息来引导前馈神经网络,在文献[7]中,卷积神经网络的注意力主要依靠输入图片的scale来进行控制,而在文献[13]中,则依靠通道注意力机制来是被任务并且取得了最好的效果,在DFN中,全局上下文作为注意力并以此为特征!
网络细节

前面的网络基本架构是非常的清楚明了的,这里重点描述一下这两个FFM和ARM的组成以及它所用的基本块!
ARM
前面来的信息通过一个全连接层+ 1*1的Conv + BN层 + sigmoid层 然后输出与原输入通过一个Mul模块得到最终的输出!
FFM
这个模块有两个输入,将两个输出进行连接,再通过一个标准块(卷积+BN+ReLU)得到输入一号,然后将其输入到一个 全局平均池化+11卷积 + ReLU层 + 11的卷积层 +sigmoid 层得到输出一号,然后将它与输入一号放入Mul块中,得到输出二号,最后将输出二号与输入一号进行add操作得到最后的输出!
这两个模块还是非常有借鉴意义的,其中MUL是借鉴SEnet中的模块,有想要了解的读者可以看一看相关论文!
损失函数

实验结果
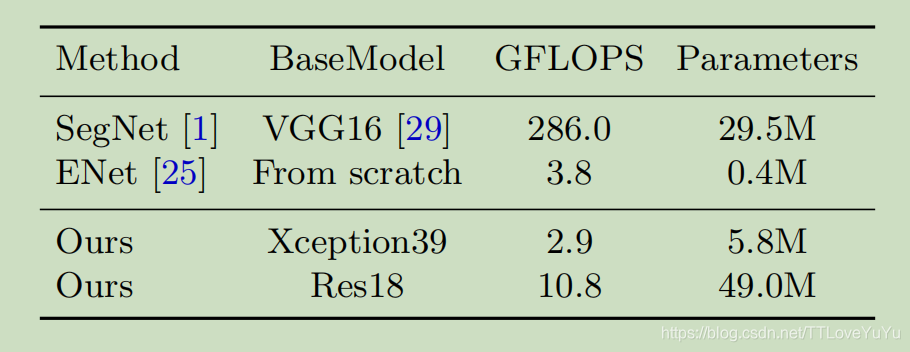
这是模型的参数与其他模型以及主干变化的比较。
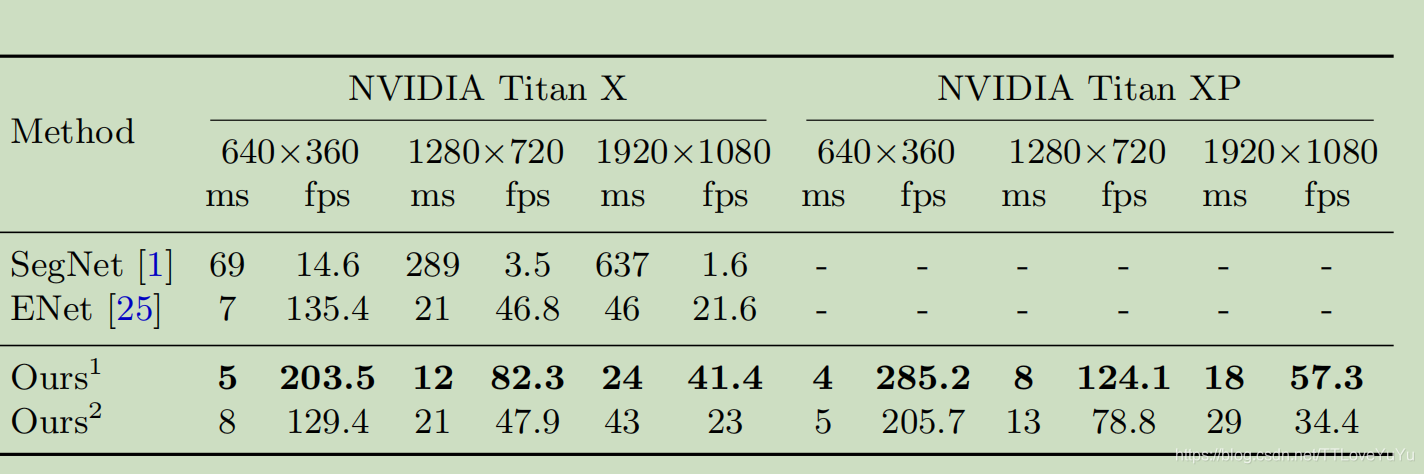
模型之间的处理速度对比。
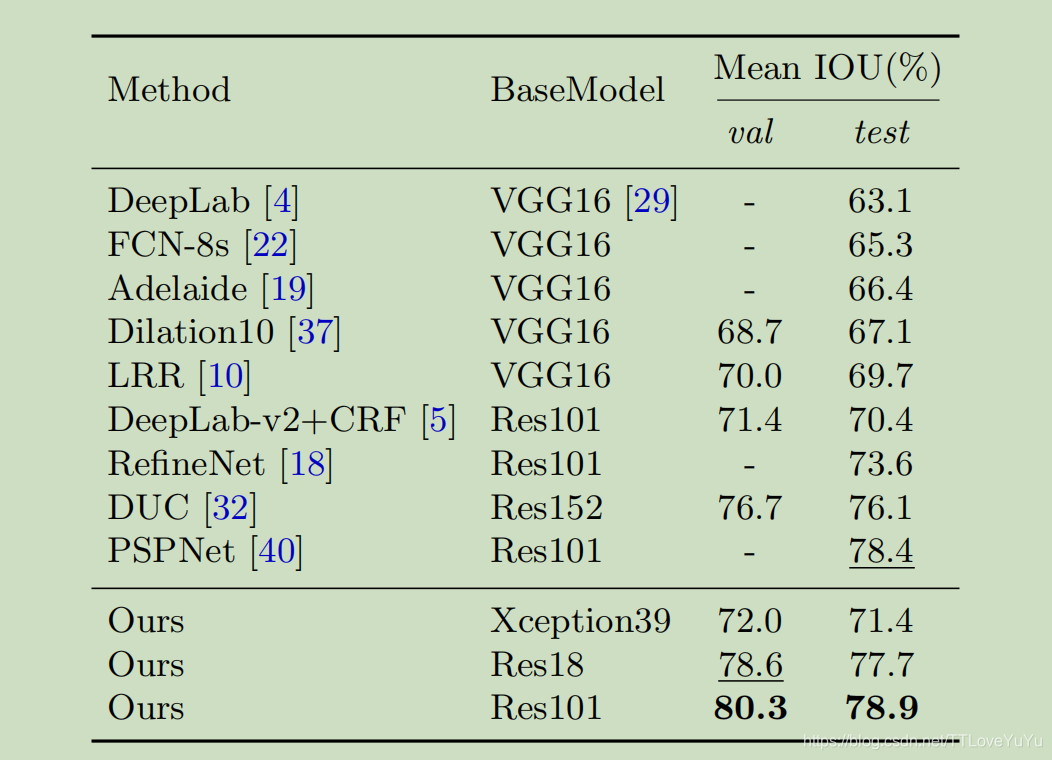
模型在Cityscape数据集上的成绩!
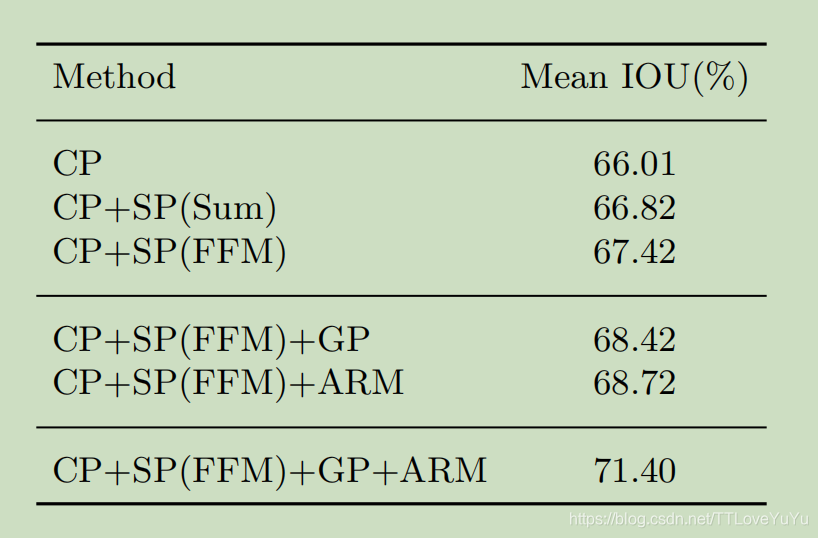
各个模块的消融实验,能够证明它们每一个以及组合确实是有效果的!