题目:Learning Spatial Attention for FaceSuper-Resolution
中文:学习空间注意力以实现人脸超分辨率

摘要
- 常规图像超分辨率技术在应用**【缺点】
低分辨率面部图像时难以恢复详细的面部结构。通过与其他任务(例如人脸解析和界标预测)共同训练,针对人脸图像量身定制的最新基于深度学习的方法已经实现了改进的性能。但是,多任务学习需要额外的手动标记数据。此外,大多数现有的工作扫描仅产生相对低分辨率的面部图像(例如128×128),因此其应用受到限制。在本文中,我们介绍了一种基于我们新提出的面部注意单元(FAU)的新颖的空间注意力残留网络(SPARNet)**,用于面部超分辨率。具体而言,我们向普通残差块引入了空间注意机制。这使卷积层能够自适应引导与关键脸部结构有关的特征,并较少关注那些特征较少的区域。这使得训练更加有效,因为关键的面部结构仅占面部图像的一小部分。注意力图的可视化表明,即使对于分辨率很低的面孔(例如16×16),我们的空间注意力网络也可以很好地捕获关键的面孔结构。对各种指标(包括PSNR,SSIM,身份相似性和标志性检测)的定量比较证明了我们的方法优于当前技术水平。我们进一步使用名为SPARNetHD的多尺度鉴别器扩展SPARNet,以产生高分辨率结果(即512×512)。我们表明,经过合成数据训练的SPARNetHD不仅可以为合成退化的人脸图像生成高质量和高分辨率的输出,而且还显示出对现实世界中低质量人脸图像的良好概括能力。可以在上找到代码。术语-面部超分辨率,空间注意力,生成对抗网络
背景:1、常规图像超分辨率技术在应用,低分辨率面部图像时难以恢复详细的面部结构。
2、大多数现有的工作仅产生相对低分辨率的面部图像。
方法:向普通残差块引入了空间注意机制。使卷积层能够自适应引导与关键脸部结构有关的特征,并较少关注那些特征较少的区域,使训练更有效。
结论:对各种指标(包括PSNR,SSIM,身份相似性和标志性检测)的定量比较证明了我们的方法优于当前技术水平。
https://github.com/chaofengc/Face-SPARNet

图 1:SPARNetHD产生的超分辨率结果是1927年苏威会议上玛丽·居里的旧照片。请放大以查看详细信息
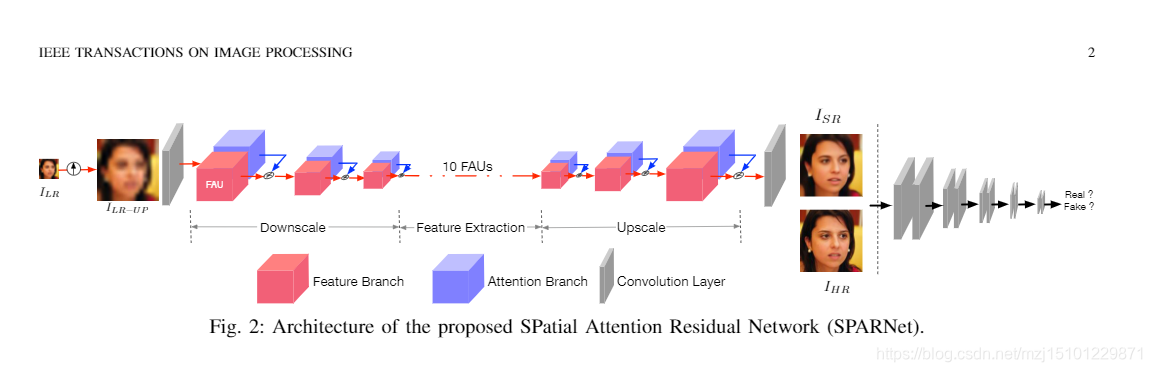
图 2:拟议的空间注意力剩余网络(SPARNet)的体系结构
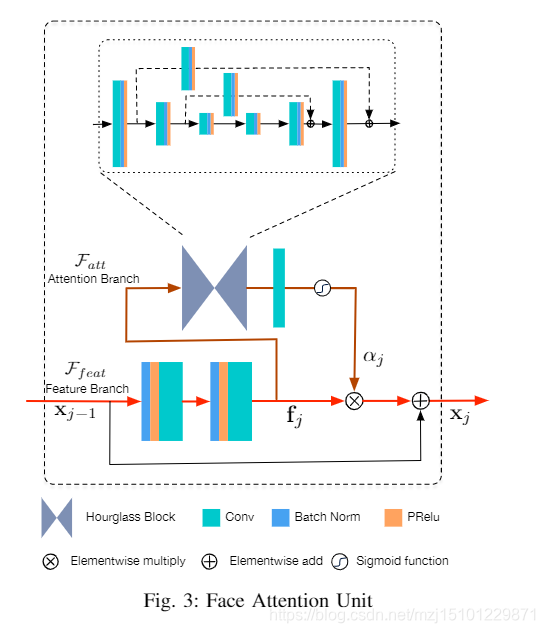
图3:面部注意单元
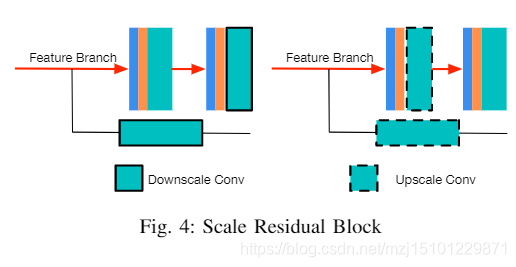
图 4:尺度残差块
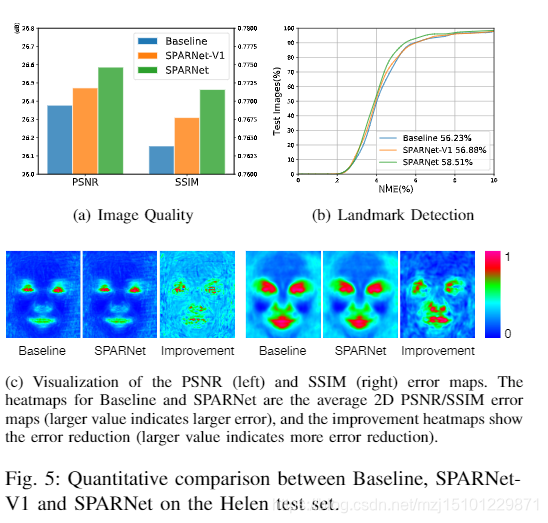
(c)可视化PSNR(左)和SSIM(右)错误图。 Baseline和SPARNet的热图是平均2D PSNR / SSIM误差图(值越大表示误差越大),改进的热图表明误差减小(值越大表示误差减少更多)
图5:在海伦测试集中对Baseline,SPARNet-V1和SPARNet进行定量比较
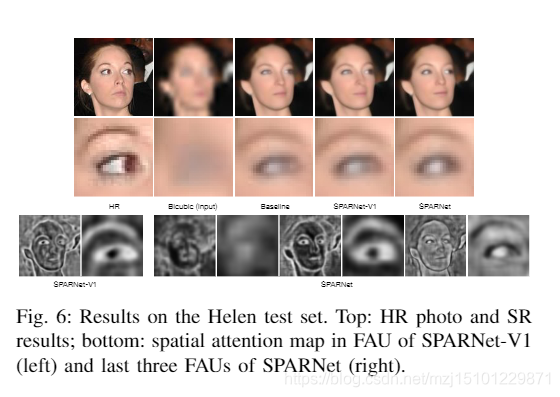
图6:海伦测试仪上的结果。页首:HR照片和SRresults;底部:SPARNet-V1的FAU中的空间关注图(左)和SPARNet的后三个FAU(右)
图7:SPARNet-VN和SPARNet-SM在Helen测试集的消融研究。我们在训练SPARNet-VN时将M设置为4,对于SPARNet-SM则将N设置为16
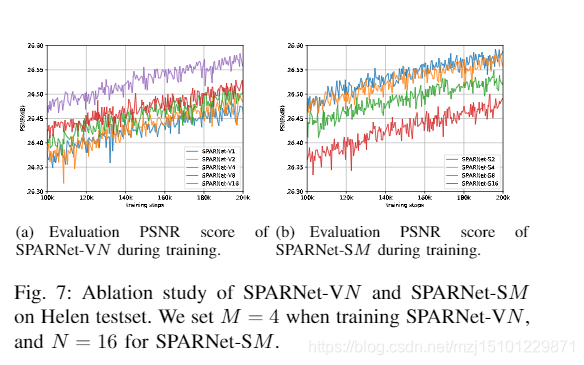
- 什么是消融研究,为什么要进行消融研究

图8:与最先进方法的定性比较。输入分辨率为16×16,放大倍数为8×
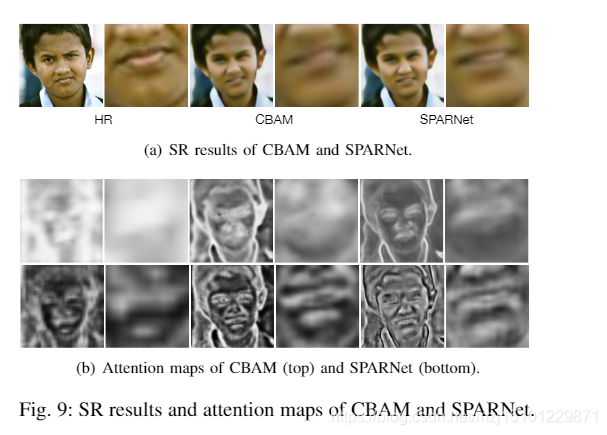
图9:CBAM和SPARNet的SR结果和关注图
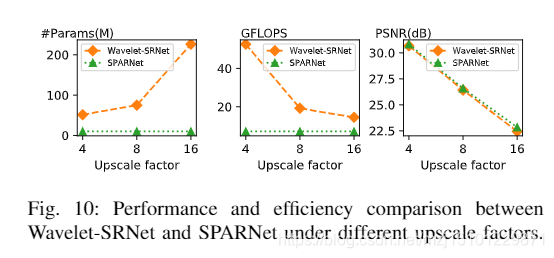
图10:在不同的高档因素下,Wavelet-SRNet和SPARNet的性能和效率比较
图11:在DICNet提供的Helen测试数据集上,PFSRNet,DICNet和SPARNet之间的视觉比较。所有结果均由CelebA训练的公共模型生成。 PFSRNet对于未对齐的测试面会产生不良结果。 SPARNet产生比DICNet更好的关键面部组件,尤其是在眼睛中
图12:在合成数据集CelebAHQ-Test(第一行)和实际数据seesCelebA-TestN(第二行)上对SPARNetHD中使用的损耗进行消融研究。更好地放大以查看细节
图13:在合成数据集CelebAHQ-Test上,由SPARNetHD和其他方法产生的结果之间的视觉比较。更好地放大以查看细节
图14:SPARNetHD和其他方法在真实LR数据集CelebA-TestN上产生的结果之间的视觉比较。更好地放大以查看细节
图15:SPARNetHD和GFRNet产生的结果之间的视觉比较。更好地放大以查看细节





引言
- 人脸超分辨率(SR),也称为人脸幻觉,是指从相应的低分辨率(LR)输入生成高分辨率(HR)人脸图像。由于存在许多低分辨率的人脸图像(例如,人脸监控视频)和人脸分析算法(例如,人脸识别)在此类图像上的效果通常较差,因此人们对人脸SR的兴趣日益浓厚。与一般的人像SR不同,人脸SR放置了重点恢复关键脸部结构(即脸部组成部分的形状和脸部轮廓)。这些结构仅占图像的一小部分,但由于它们显示较大的像素变化,因此通常更难恢复。
- 训练具有均等加权像素的常用均方误差(MSE)损失的深度神经网络在恢复这些“稀疏”结构方面并非十分有效。以前的工作[1],[2],[3]提出合并其他任务,例如面部分析和界标检测,以协助面部SR网络的训练。 [1],[3]也使用预测人脸先验来帮助人脸SR。尽管通过这些附加任务进行联合训练有助于增强关键面部结构的重要性,但存在两个主要缺点,即(1)
需要付出额外努力才能为附加任务标记数据,以及(2)从LR输入本身预测面部也本身一个困难的问题。 - 另一方面,如果我们将人脸图像细分为许多小区域,并将每个区域视为一个个体样本,则包含关键脸部结构的区域(称为困难区域)和不包含关键脸部结构的区域(称为容易区域)之间的不平衡分布。将类似于对象检测中前景样本与背景样本之间的不平衡。这表明我们可以在对象检测中采用类似于引导或在线硬示例挖掘(OHEM)[4]的技术来解决我们的人脸SR问题。
- 在本文中,我们介绍了经过精心设计的FaceAttention单元(FAU),以构造用于人脸SR的空间注意力残留网络(SPARNet)。
关键思想是使用2D空间注意力图来引导与关键脸部结构相关的特征。空间注意图不是硬选择,而是给特征图的每个空间位置分配介于0和1之间的分数。这允许通过梯度下降来学习空间注意力图的预测。网络的不同FAU中的空间注意图可以学习集中于不同的面部结构。 - 比如说
较深的注意图层中的贴图更多地关注诸如眼睛和嘴巴等粗糙结构,而较浅层中的贴图则更关注诸如头发的详细纹理。考虑到大多数现有的面部SR方法只能产生128×128的输出,我们进一步扩展了SPARNet(称为SPARNetHD)以生成高分辨率输出(即512×512)。具体来说,我们将SPARNet的输出分辨率从128×128扩大到512×512,并采用类似于Pix2PixHD [5]的多尺度鉴别器损耗来生成更逼真的纹理。实验表明,使用合成的LR数据训练的SPARNetHD在自然LR输入的情况下非常健壮,而没有建议的空间注意机制的模型会产生不希望的伪像。我们在图1的一张旧照片上显示了SPARNetHD的示例结果。我们可以看到SPARNetHD可以很好地还原关键面组件,还可以生成高分辨率和逼真的纹理。 - 本文的主要贡献可以归纳如下:
- 1)我们提出了一种有效的人脸超分辨率框架SPARNet。在不依赖任何额外监督的情况下(例如,人脸解析地图和地标),它可以在各种指标(包括PSNR,SSIM,身份相似性和地标检测)上实现最先进的性能。
- 2)我们证明了
拟议的FAU,作为SPARNet的基本构建模块,可以引导关键的面部结构(即面部组成和面部轮廓),并显着改善面部超分辨率的性能。 - 3)通过在SPARNet中重复FAU,可以使不同FAU中的空间注意力图学习重点关注
- 4)我们引入了SPARNetHD来生成高分辨率的人脸图像(即512×512),并且使用合成数据训练的模型在自然LR图像上也能很好地工作。
结论
- 我们提出了一种用于极低分辨率人脸超分辨率的空间注意力残留网络(SPAR-Net)。 SPARNet是由堆叠的面部注意单元(FAU)组成的,它通过空间注意分支扩展了普通残差块。空间注意机制使网络可以在特征较少的区域上无注意。这使得SPARNet的培训更加有效。与各种度量标准进行的广泛实验说明了SPARNet与当前最新技术相比的优势。我们通过更多通道数量和多尺度辨别器将SPARNet扩展到SPARNetHD。在合成数据集上训练的SPARNetHD能够为LR面部图像生成逼真的高分辨率输出(即512×512),与其他方法进行定量和定性比较表明,所提出的空间关注机制有利于恢复LR面部图像的纹理细节。我们还证明了SPARNetHD可以很好地推广到现实世界中的LR人脸,使其高度实用且适用。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ - 文章提供了其他实验的代码:
- 面部对齐方法:
https://github.com/1adrianb/face-alignment - 人脸识别方法:
https://github.com/clcarwin/sphereface_pytorch - Progressive Face Super-Resolution via Attention to Facial Landmark论文代码:
https://github.com/DeokyunKim/Progressive-Face-Super-Resolution - Deep Iterative Collaboration for Face Super-Resolution论文代码:
https://github.com/Maclory/Deep-Iterative-Collaboration(DIC) - [ ]