YARN资源分配 :
本篇要解决的问题:
- Container是以什么形式运行的?是单独的JVM进程吗?
- YARN的vcore和本机的CPU核数关系?每个Container能够使用的物理内存和虚拟内存是多少?
- 一个NodeManager可以分配多少个Container?
- 一个Container可以分配的最小内存是多少?最大内存内存是多少?以及最小、最大的VCore是多少?
- 当将Spark程序部署在YARN上, AM与Driver的关系是什么?
- Spark on YARN,一个Container可以运行几个executor?executor设置的内存和container的关系是什么?
YARN资源管理简述
分布式应用在YARN中的执行流程
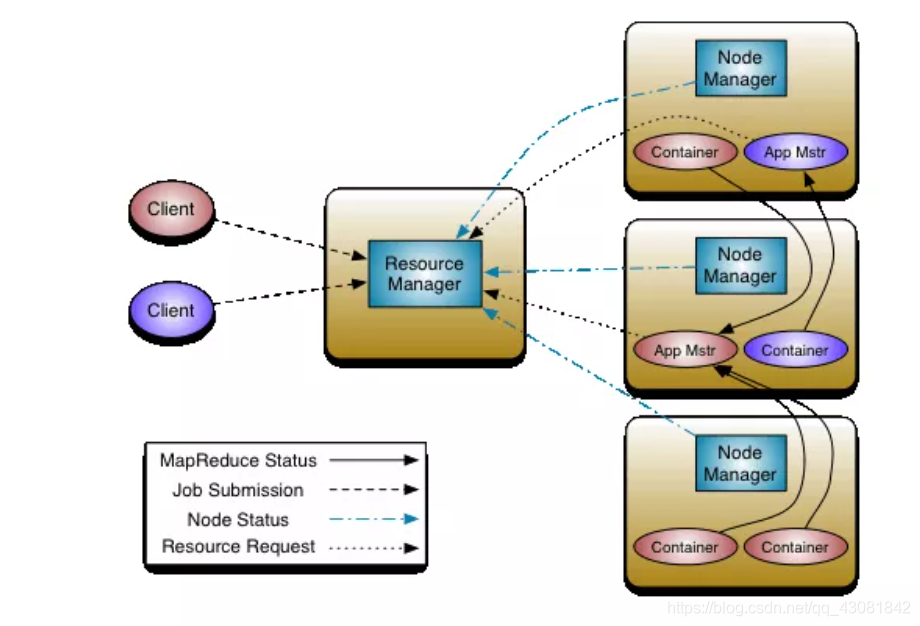
这张图是YARN的经典任务执行流程图。可以发现上图中有5类角色:
- Client
- Resource Manager
- Node Manager
- Application Master
- Container
先简单来梳理提交任务的流程。
- 要将应用程序(MapReduce/Spark/Flink)程序运行在YARN集群上,先得有一个用于将任务提交到作业的客户端,也就是client。它向Resource Manager(RM)发起请求,RM会为提交的作业生成一个JOB ID。此时,JOB的状态是:NEW
- 客户端继续将JOB的详细信息提交给RM,RM将作业的详细信息保存。此时,JOB的状态是:SUBMIT
- RM继续将作业信息提交给scheduler(调度器),调度器会检查client的权限,并检查要运行Application Master(AM)对应的queue(默认:default queue)是否有足够的资源。此时,JOB的状态是ACCEPT。
- 接下来RM开始为要运行AM的Container资源,并在Container上启动AM。此时,JOB的状态是RUNNING
- AM启动成功后,开始与RM协调,并向RM申请要运行程序的资源,并定期检查状态。
- 如果JOB按照预期完成。此时,JOB的状态为FINISHED。如果运行过程中出现故障,此时,JOB的状态为FAILED。如果客户端主动kill掉作业,此时,JOB的状态为KILLED。
YARN集群资源管理
集群总计资源
要想知道YARN集群上一共有多少资源很容易,我们通过YARN的web ui就可以直接查看到。
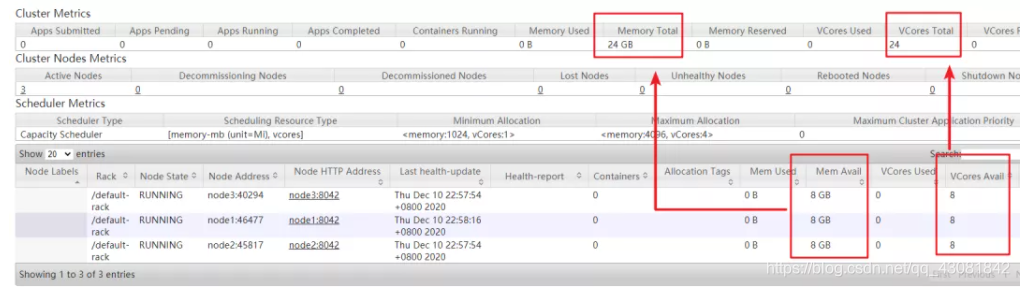
通过查看Cluster Metrics,可以看到总共的内存为24GB、虚拟CPU核为24个。我们也可以看到每个NodeManager的资源。很明显,YARN集群中总共能使用的内存就是每个NodeManager的可用内存加载一起,VCORE也是一样。
NodeManager总计资源
NodeManager的可用内存、可用CPU分别是8G、和8Core。这个资源和Linux系统是不一致的。我们通过free -g来查看下Linux操作系统的总计内存、和CPU核。
>第一个节点(总计内存是10G,空闲的是8G)
>第二个节点(总计内存是7G,空闲是不到6G)
>第三个节点(和第二个节点一样)
这说明 NodeManager的可用内存和操作系统总计内存是没有直接关系的!
NodeManager的可用内存是如何确定的呢?
在yarn-default.xml中有一项配置为:yarn.nodemanager.resource.memory-mb,它的默认值为:-1(hadoop 3.1.4)。我们来看下Hadoop官方解释:
这个配置是表示NodeManager总共能够使用的物理内存,这也是可以给container使用的物理内存。如果配置为-1,且yarn.nodemanager.resource.detect-hardware-capabilities配置为true,那么它会根据操作的物理内存自动计算。而yarn.nodemanager.resource.detect-hardware-capabilities默认为false,所以,此处默认NodeManager就是8G。这就是解释了为什么每个NM的可用内存是8G。
还有一个重要的配置:yarn.nodemanager.vmem-pmem-ratio,它的默认配置是2.1
这个配置是针对NodeManager上的container,如果说某个Container的物理内存不足时,可以使用虚拟内存,能够使用的虚拟内存默认为物理内存的2.1倍。
针对虚拟CPU核数,也有一个配置yarn.nodemanager.resource.cpu-vcores配置,它的默认配置也为-1。看一下Hadoop官方的解释:与内存类似,它也有一个默认值:就是8。
这就解释了为什么每个NodeManager的总计资源是8G和8个虚拟CPU核了。
scheduler调度资源
通过YARN的webui,点击scheduler,我们可以看到的调度策略、最小和最大资源分配。
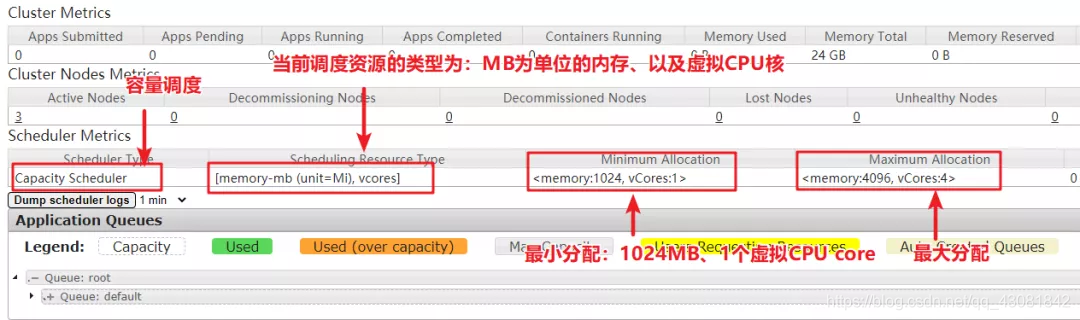
- 通过web ui,我们可以看到当前YARN的调度策略为容量调度。调度资源的单位是基于MB的内存、和Vcore(虚拟CPU核)。最小的一次资源分配是:1024M(1G)和1个VCORE。最大的一次分配是:4096M(4G)和4个VCORE。注意:内存资源和VCORE都是以Container承载的。
yarn.scheduler.minimum-allocation-mb
默认值:1024
说明:该配置表示每个容器的最小分配。因为RM是使用scheduler来进行资源调度的,如果请求的资源小于1G,也会设置为1G。这表示,如果我们请求一个256M的container,也会分配1G。
yarn.scheduler.maximum-allocation-mb
默认值:8192
说明:最大分配的内存,如果比这个内存高,就会抛出InvalidResourceRequestException异常。这里也就意味着,最大请求的内存不要超过8G。上述截图显示是4G,是因为我在yarn-site.xml中配置了最大分配4G。
yarn.scheduler.minimum-allocation-vcores
默认值:1
说明:同内存的最小分配
yarn.scheduler.maximum-allocation-vcores
默认值:4
说明:同内存的最大分配
Container总计资源
- 在YARN中,资源都是通过Container来进行调度的,程序也是运行在Container中。Container能够使用的最大资源,是由scheduler决定的。’
- 如果按照Hadoop默认配置,一个container最多能够申请8G的内存、4个虚拟核。例如:我们请求一个Container,内存为3G、VCORE为2,是OK的。考虑一个问题:如果当前NM机器上剩余可用内存不到3G,怎么办?此时,就会使用虚拟内存。
- 不过,虚拟内存,最多为内存的2.1倍,如果物理内存 + 虚拟内存仍然不足3G,将会给container分配资源失败。
- 根据上述分析,如果我们申请的container内存为1G、1个VCORE。那么NodeManager最多可以运行8个Container。如果我们申请的container内存为4G、4个vcore,那么NodeManager最多可以运行2个Container。
Container是一个JVM进程吗?
- 这个问题估计有很多天天在使用Hadoop的人都不一定知道。当向RM请求资源后,会在NodeManager上创建Container。问题是:Container是不是有自己独立运行的JVM进程呢?还是说,NodeManager上可以运行多个Container?Container和JVM的关系是什么?
- 此处,明确一下,每一个Container就是一个独立的JVM实例。(此处,咱们不讨论Uber模式)。每一个任务都是在Container中独立运行,例如:MapTask、ReduceTask。当scheduler调度时,它会根据任务运行需要来申请Container,而每个任务其实就是一个独立的JVM。
- 为了验证此观点,我们来跑一个MapReduce程序。然后我们在一个NodeManager上使用JPS查看一下进程:(这是我处理过的,不然太长了,我们主要是看一下内存使用量就可以了)
- 我们看到了有MRAppMaster、YarnChild这样的一些Java进程。这就表示,每一个Container都是一个独立运行的JVM,它们彼此之间是独立的
Spark on YARN资源管理
- 通常,生产环境中,我们是把Spark程序在YARN中执行。而Spark程序在YARN中运行有两种模式,一种是Cluster模式、一种是Client模式。这两种模式的关键区别就在于Spark的driver是运行在什么地方。如果运行模式是Cluster模式,Driver运行在Application Master里面的。如果是Client模式,Driver就运行在提交spark程序的地方。Spark Driver是需要不断与任务运行的Container交互的,所以运行Driver的client是必须在网络中可用的,知道应用程序结束
- 这两幅图描述得很清楚。
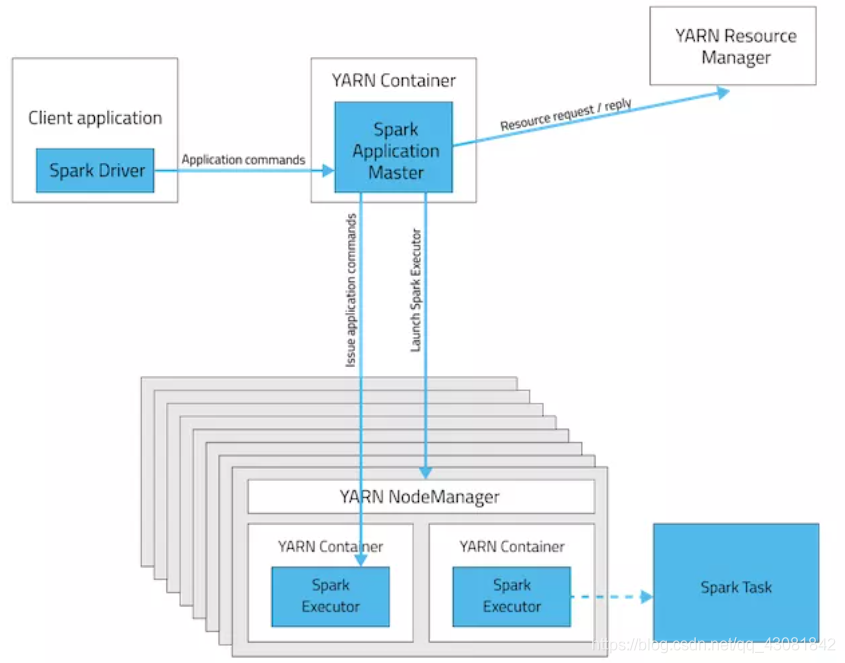

留意一下Driver的位置。
- 通过上面的分析,我们可以明确,如果是Client模式,Driver和ApplicationMaster运行在不同的地方。ApplicationMaster运行在Container中,而Driver运行在提交任务的client所在的机器上。
- 因为如果是Standalone集群,整个资源管理、任务执行是由Master和Worker来完成的。而当运行在YARN的时候,就没有这两个概念了。资源管理遵循YARN的资源调度方式。之前在Standalone集群种类,一个worker上可以运行多个executor,现在对应的就是一个NodeManager上可以运行多个container,executor的数量跟container是一致的。可以直接把executor理解为container。
我们再来看看spark-submit的一些参数配置。
- 配置选项中,有一个是公共配置,还有一些针对spark-submit运行在不同的集群,参数是不一样的。
公共的配置:
- -driver-memory、–executor-memory,这是我们可以指定spark driver以及executor运行所需的配置。executor其实就是指定container的内存,而driver如果是cluster模式,就是application master的内置,否则就是client运行的那台机器上申请的内存。
- 如果运行在Cluster模式,可以指定driver所需的cpu core。
- 如果运行在Spark Standalone,–total-executor-cores表示一共要运行多少个executor。
- 如果运行在Standalone集群或者YARN集群,–executor-cores表示每个executor所需的cpu core。
- 如果运行在yum上,–num-executors表示要启动多少个executor,其实就是要启动多少个container。
Flink on YARN资源管理
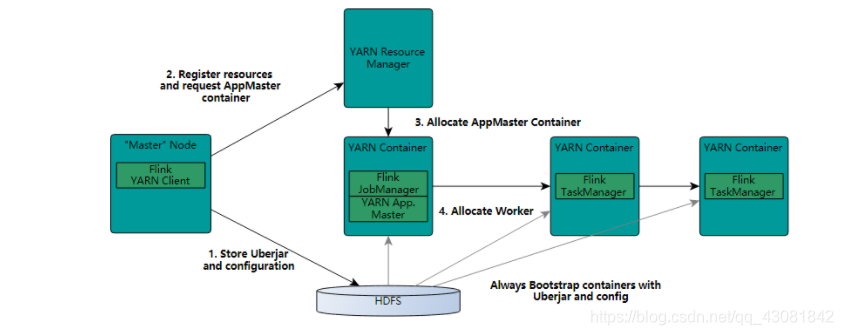
- Flink在YARN上也有两种模式:一种是yarn-session、还有一个是yarn-per-job。YARN session模式比较有意思,相当于在YARN集群中基于Container运行一套Flink集群。
- Container有JobManager角色、还有TaskManager角色。然后客户端可以不断地往这套运行在YARN上的Flink Cluster提交作业。
- 上面这个命令表示,在YARN上分配4个Container,每个Container上运行TaskManager,每个TaskManager对应8个vcore,每个TaskManager 32个G。这就要求YARN上scheduler分配Container最大内存要很大,否则根本无法分配这么大的内存。这种模式比较适合做一些交互性地测试。
- 第二种模式yarn-per-job,相当于就是单个JOB提交的模式。同样,在YARN中也有JobManager和TaskManager的概念,只不过当前是针对一个JOB,启动则两个角色。JobManager运行在Application Master上,负责资源的申请。
- 上述命令表示,运行两个TaskManager(即2个Container),job manager所在的container是1G内存、Task Manager所在的Container是3G内存、每个TaskManager使用3个vcore。
总结
如果你认真看完了,很轻易地就能回答下面的问题:
- Container是以什么形式运行的?是单独的JVM进程吗?
是的,每一个Container就是一个单独的JVM进程。
- YARN的vcore和本机的CPU核数关系?
没关系。默认都是手动在yarn-default.xml中配置的,默认每个NodeManager是8个vcore,所有的NodeManager上的vcore加在一起就是整个YARN所有的vcore。
- 每个Container能够使用的物理内存和虚拟内存是多少?
scheduler分配给container多少内存就是最大能够使用的物理内存,但如果超出该物理内存,可以使用虚拟内存。虚拟内存默认是物理内存的2.1倍。
- 一个NodeManager可以分配多少个Container?
这个得看Container的内存大小和vcore数量。用NM上最大的可用Mem和Vcore相除就知道了。
- 一个Container可以分配的最小内存是多少?最大内存内存是多少?以及最小、最大的VCore是多少?
根据scheduler分配的最小/最大内存、最小/最大vcore来定。
- 当将Spark程序部署在YARN上, AM与Driver的关系是什么?
有两种模式,cluster模式,Driver就运行在AM上。如果是client模式,没关系。
- Spark on YARN,一个Container可以运行几个executor?executor设置的内存和container的关系是什么?
一个container对应一个executor。executor设置的内存就是AM申请的container内存,如果container最小分配单位是1G,而executor设置的内置是512M,按照container最小单位分配。