Trie
trie是一棵树,他的根是一个空节点init,根到每个结点的路径组成一个单词的前缀。
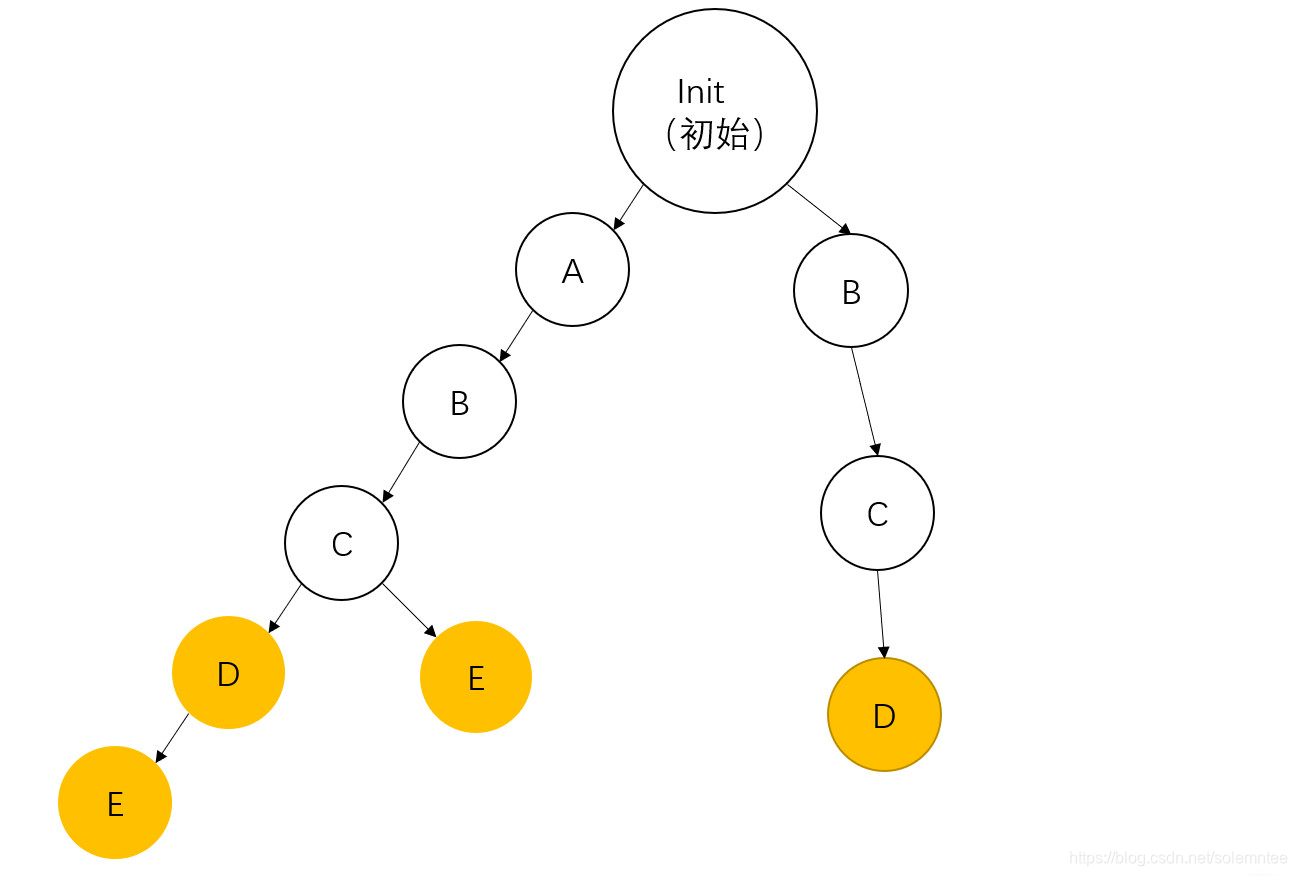
这是一棵由{abcd,abcde,abce,bcd}四个单词组成的字典树,非常直观。黄色结点表示这个字母是某个单词的结尾)。
我们要在这棵树里面查找某个单词,只需要从根开始按位匹配,直到单词结尾再查看一下该位置是否被标记(为黄色)即可。
 (字典树的用途主要是对于源字符很多且有公共前缀的一些字符串建树,在查询时可以快速判断目标是否存在于源字典里)
(字典树的用途主要是对于源字符很多且有公共前缀的一些字符串建树,在查询时可以快速判断目标是否存在于源字典里)
一般的,字典树结点有vis和num两个子属性。vis[t-‘a’]数组表示他儿子t的位置,如果vis[t-‘a’]=0就表示没有t这个儿子;num表示以当前节点为结尾的单词个数。
struct
{
ll vis[26];
ll num;
}trie[maxn];
字典树的常见功能有插入和查找
ll tot=0;
void insert(string s)插入一个单词
{
int now=0;
for(auto x:s)按位遍历字典树
{
now表示当前位置(初始值为0就是init结点),x表示下一个字母
if(trie[now].vis[x-'a'])now=trie[now].vis[x-'a'];如果树上有这个字母就往下走
else如果树上没有这个字母
{
trie[now].vis[x-'a']=++tot;就在末尾建立一个结点,将vis指针指向这个节点
now=trie[now].vis[x-'a'];
初始化这个节点
rep(i,0,25)trie[now].vis[i]=0;
trie[now].num=0;
}
}
当退出循环的时候now位于这个单词末尾
trie[now].num++;将以该字母结尾的单词个数+1
}
看懂了插入的话查找就是小意思了。
ll find(string s)
{
int now=0;
for(auto x:s)
{
if(trie[now].vis[x-'a'])now=trie[now].vis[x-'a'];
else return 0;
}
return trie[now].num;
}
综上,所以我们学会了字典树。
kmp
推荐博客
next数组的本质是:最长公共前缀后缀,当串失配之后从最长公共前缀后一位开始匹配。
char a[maxn];
ll kmp[maxn];
scanf("%s",a+1);
ll lena=strlen(a+1),j=0;
rep(i,2,lena)
{
while(j>0&&a[j+1]!=a[i])j=kmp[j];
if(a[j+1]==a[i])j++;
kmp[i]=j;
}
Aho-Corasick automaton
推荐博客
ac自动机可以计算多个短串在一个长串中分别出现的次数。
流程是先用n个短串建trie,然后用长串在trie上按位匹配,当失配后跳至树上某个位置(失配前缀的能在trie上找到的最长后缀)继续匹配的算法。
核心是要预处理处这个跳的位置,也就是fail数组。
妙在fail可以dp求出
t r i e [ t r i e [ u ] . v i s [ i ] ] . f a i l = t r i e [ t r i e [ u ] . f a i l ] . v i s [ i ] trie[trie[u].vis[i]].fail=trie[trie[u].fail].vis[i] trie[trie[u].vis[i]].fail=trie[trie[u].fail].vis[i]
所以就 O ( m ) O(m) O(m)处理出了 f a i l fail fail
void getfail()
{
queue<ll>q;
rep(i,0,25)
{
if(trie[0].vis[i]!=0)
{
trie[trie[0].vis[i]].fail=0;
q.push(trie[0].vis[i]);
}
}
while(!q.empty())
{
ll p=q.front();
q.pop();
rep(i,0,25)
{
ll to=trie[p].vis[i],fail=trie[p].fail;
if(to==0)trie[p].vis[i]=trie[fail].vis[i];
else
{
trie[to].fail=trie[fail].vis[i];
q.push(to);
}
}
}
}
牛妹的考验
给出 n 个单词,每个单词有一个权值val,构造一个长度为L的串,求最大权值,计算权值时包含关系也要计算。即: abc的val为2,ab值为1,构造一个串abc的值为 2+1=3
在trie上dp,dp[i][j]表示长度为i的,以j位置结尾的串的最大值~
manacher
for(int i=1;i<=2*len;i++)
{
if(mx>i)p[i]=min(p[2*id-i],mx-i);
else p[i]=0;
while(s[i+p[i]+1]==s[i-p[i]-1])++p[i];
if(id+p[i]>mx)
{
mx=id+p[i];
id=i;
}
}