文章目录
0. 神经元的工作方式
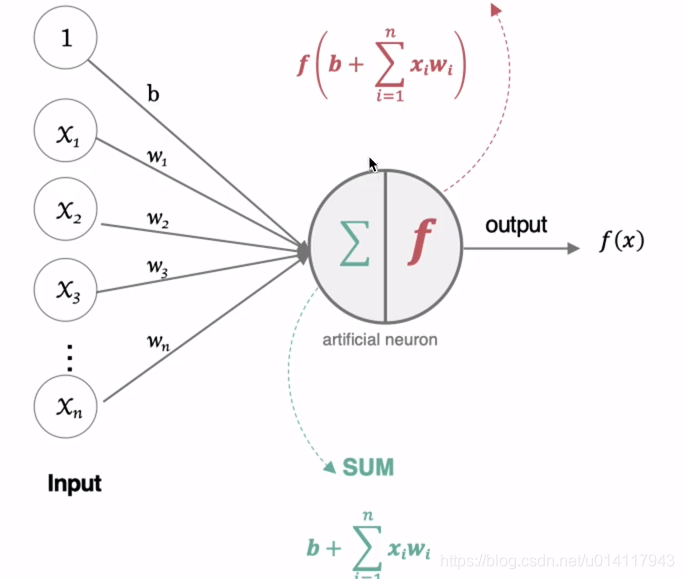
牵扯出两个问题,一个是权值如何初始化,二是激活函数如何选择或者设定。
1. 激活函数
激活函数:向网络中引入非线性因素,才可以拟合非线性数据。
1.1 sigmoid
1.2 tanh
1.3 relu
1.4 leakyrelu
1.5 softmax
1.6 其他激活函数
softmax用在多分类过程中,将多分类的结果以概率的方式展示出来。
将网络输出的logits通过softmax函数,就映射成了0到1之间的值,而这些值的累加和为1(满足概率的性质)。
1.7 如何选择激活函数
隐藏层
- 优先选择relu
- 如果relu效果不好,可以尝试leaky relu
- 如果使用了relu,需要注意一下“dead relu”问题,避免出现大的梯度从而导致过多的神经元死亡。
- 不要使用sigmoid,可以尝试tanh。
输出层
- 二分类问题选择sigmoid
- 多分类问题选择softmax
- 回归问题选择identity
2. 参数初始化
- 偏置可以直接初始化为0。
- 权重初始化比较重要。
2.1 随机初始化
很少使用
2.2 标准初始化
2.3 Xavier(Glorot)初始化
- 现阶段使用比较多
基本思想:各层的激活值和梯度的方差在传播过程中保持一致,也叫Glorot初始化。在tf.keras中有两种实现方法:
- 正态化Xavier初始化
# 实例化
init = tf.initializers.glorot_normal()
# 采样得到权重值
values = init(shape=(9, 1))
print(values)
结果:
tf.Tensor(
[[-0.31431448]
[-0.41750777]
[-0.15744446]
[-0.08545057]
[-0.8899493 ]
[ 0.56381005]
[-0.49195307]
[-0.5516487 ]
[-0.40066674]], shape=(9, 1), dtype=float32)
- 标准化Xavier初始化
# 实例化
init = tf.initializers.glorot_unnormal() // 区别在这
# 采样得到权重值
values = init(shape=(9, 1))
print(values)
结果:
tf.Tensor(
[[ 0.20395625]
[ 0.22338384]
[ 0.2141344 ]
[ 0.44250667]
[-0.23224455]
[-0.57786965]
[ 0.37278986]
[-0.51715434]
[-0.6112636 ]], shape=(9, 1), dtype=float32)
2.4 He初始化
- 出自何恺明
基本思想:正向传播时没激活值方差保持不变,反向传播时,关于状态值的梯度的方差保持不变。在tf.keras中有两种实现方法:
- 正态化He初始化
# 实例化
init = tf.initializers.he_normal()
# 采样得到权重值
values = init(shape=(9, 1))
print(values)
结果:
tf.Tensor(
[[-0.05249792]
[-0.65136284]
[ 0.673169 ]
[-0.4934218 ]
[-0.81981057]
[-0.11099399]
[-0.05204036]
[ 0.00710088]
[-0.01671317]], shape=(9, 1), dtype=float32)
- 标准化He初始化
# 实例化
init = tf.initializers.he_unnormal() // 区别在这
# 采样得到权重值
values = init(shape=(9, 1))
print(values)
结果:
tf.Tensor(
[[ 0.50093305]
[-0.32057783]
[-0.64743155]
[-0.29729575]
[ 0.6857146 ]
[ 0.14684016]
[-0.16848183]
[-0.25743085]
[-0.11090642]], shape=(9, 1), dtype=float32)