Spark Streaming实战-★★★★★
准备工作
nc命令
- 后续我们要使用SparkStreaming从网络接收一些数据用来做实时计算
- 那么我们可以使用linux-node01上的socket服务给SparkStreaming发数据
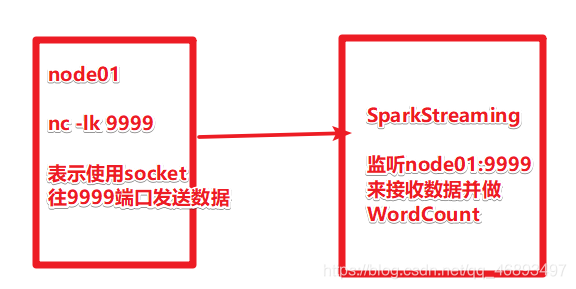
- 如果没有安装nc命令 先执行
yum install -y nc
- 再使用
nc -lk 9999
- 上面的操作经常用来做实时程序测试, 后续可以使用SparkStreaming整合Kafka来接收实时数据
pom.xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
案例1-简单WordCount
package cn.hanjiaxiaozhi.stream
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
import org.apache.spark.{
SparkConf, SparkContext, streaming}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
/**
* Author hanjiaxiaozhi
* Date 2020/7/25 15:37
* Desc 使用SparkStreaming监听node01:9999发送的实时数据并做WordCount
*/
object WordCount1 {
def main(args: Array[String]): Unit = {
//1.准备SparkStreaming执行环境-StreamingContext
//spark.master should be set as local[n], n > 1 in local mode
//如果写的是local[n]在SparkStreaming中,n必须>1,因为需要一个接收,一个计算
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//batchDuration the time interval at which streaming data will be divided into batches
//Seconds(5)表示每隔5s对数据进行一个批次的划分,也就是微批处理的时间划分间隔
val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))
//2.监听node01:9999发送的实时数据
val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//3.实时处理数据并做WordCount
//对DStream进行WordCount的操作其实就是对每5s一个批次的RDD进行WordCount
val wordsDStream: DStream[String] = dataDStream.flatMap(_.split(" "))
val wordAndOneDStream: DStream[(String, Int)] = wordsDStream.map((_,1))
val resultDStream: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_+_)
//4.输出结果到控制台
resultDStream.print()
//5.启动实时程序-等待关闭
ssc.start()
ssc.awaitTermination()
}
}
- 总结:
- 上面的案例1 可以完成简单的WordCount, 但是只能对当前批次的数据进行累计
- 无法将下一批次的数据和之前的历史结果进行累加
- 如前5s发了hello world hello world,那么结果为 hello 2 world 2
- 隔了5s后又发了一次hello world 那么结果为 hello 1 world 1 而不是和之前的累加为 hello 3 world 3
- 所以要来学习案例2使用有状态计算来完成和历史数据的累加
案例2-和历史数据进行累加
package cn.hanjiaxiaozhi.stream
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.{
SparkConf, SparkContext}
/**
* Author hanjiaxiaozhi
* Date 2020/7/25 15:37
* Desc 使用SparkStreaming监听node01:9999发送的实时数据并做WordCount,并将当前批次数据和历史数据进行累加/聚合
*/
object WordCount2 {
def main(args: Array[String]): Unit = {
//1.准备SparkStreaming执行环境-StreamingContext
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))
//The checkpoint directory has not been set. Please set it by StreamingContext.checkpoint().
//注意:如果要进行历史值聚合/累加,那么需要将历史值找个目录存起来,SparkStreaming会自动使用该目录
ssc.checkpoint("./sscckp")//实际中给一个HDFS路径,本地测试给个本地的也行
//2.监听node01:9999发送的实时数据
val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//3.实时处理数据并做WordCount
//对DStream进行WordCount的操作其实就是对每5s一个批次的RDD进行WordCount
val wordsDStream: DStream[String] = dataDStream.flatMap(_.split(" "))
val wordAndOneDStream: DStream[(String, Int)] = wordsDStream.map((_,1))
//val resultDStream: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_+_)
//================================有状态计算===========================================
//我们需要对wordAndOneDStream中的每一条数据(单词,1),要和之前上一批次的历史聚合结果进行累加
//那么某一个单词/key的数据第一次进来,历史值应该是0
///也就是按照单词的key和key对应的历史值聚合/累加
//所以可以使用SparkStreaming提供的updateStateByKey
//updateFunc: (Seq[V], Option[S]) => Option[S]
//定义一个函数updateFunc,完成当前批次的(单词,1)和历史值进行累加/聚合
//currentValues:Seq[Int]表示当前批次的数据,如发送了两次hello,那么就是(hello,1) (hello,1),byKey之后就是[1,1]
//historyValue:Option[Int]表示当前key的历史值,历史值如果没有就是0
//返回值: 当前批次的数据 + 历史值
val updateFunc = (currentValues:Seq[Int],historyValue:Option[Int])=>{
//getOrElse(0)表示如果有则返回历史值,如果没有则返回0
val currentResult: Int = currentValues.sum + historyValue.getOrElse(0)
//Some表示有值,是返回类型Option的子类型
Some(currentResult)
}
val resultDStream: DStream[(String, Int)] = wordAndOneDStream.updateStateByKey(updateFunc)
//4.输出结果到控制台
resultDStream.print()
//5.启动实时程序-等待关闭
ssc.start()
ssc.awaitTermination()
}
}
案例3-扩展-重启后的状态恢复
package cn.hanjiaxiaozhi.stream
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.{
SparkConf, SparkContext}
/**
* Author hanjiaxiaozhi
* Date 2020/7/25 15:37
* Desc 使用SparkStreaming监听node01:9999发送的实时数据并做WordCount,并将当前批次数据和历史数据进行累加/聚合,然后再完成重启之后的状态恢复
*/
object WordCount3 {
val chkpath = "./sscckp"
def createFunction():StreamingContext={
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))
ssc.checkpoint(chkpath)//实际中给一个HDFS路径,本地测试给个本地的也行
//监听node01:9999发送的实时数据
val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//实时处理数据并做WordCount
//对DStream进行WordCount的操作其实就是对每5s一个批次的RDD进行WordCount
val wordsDStream: DStream[String] = dataDStream.flatMap(_.split(" "))
val wordAndOneDStream: DStream[(String, Int)] = wordsDStream.map((_,1))
// updateFunc: (Seq[V], Option[S]) => Option[S]
//currentValues:Seq[Int]:表示当前批次数据,如输入hello hello ,那么map之后为(hello,1)(hello,1) ,byKey之后为[1,1]
//historyValue:Option[Int]:表示当前key对应的历史值,如果没有则为0
//返回: currentValues值 + historyValue值
val updateFunc = (currentValues:Seq[Int],historyValue:Option[Int])=>{
//getOrElse(0)表示如果有历史值则返回,没有则返回0
val currentResult: Int = currentValues.sum + historyValue.getOrElse(0)
//Option(currentResult)
Some(currentResult)
}
val resultDStream: DStream[(String, Int)] = wordAndOneDStream.updateStateByKey(updateFunc)
//输出结果到控制台
resultDStream.print()
ssc
}
def main(args: Array[String]): Unit = {
//1.使用StreamingContext.getOrCreate,表示如果chkpath有则根据chkpath返回,没有则创建
val ssc: StreamingContext = StreamingContext.getOrCreate(chkpath,createFunction)
//2.启动实时程序-等待关闭
ssc.start()
ssc.awaitTermination()
}
}
案例4-reduceByKeyAndWindow窗口聚合
- 1.需求
- 通过上面的案例我们已经可以对实时数据按照时间批次进行划分,然后计算当前批次的数据或者将当前批次的数据和历史数据/历史状态进行聚合/进行有状态计算
- 但是如果有了新的需求就无法满足了,如
- 每隔5S计算最近10S的数据
- 每隔1分钟计算最近24小时的热搜词汇排行榜…
- 而要完成这些需求就得学习学的API,也就是SparkStreaming提供的窗口操作(和之前的SparkCore的开窗函数不一样)
- 2.窗口函数图解
- 可以完成每隔xx时间计算最近xx时间的数据
- 有两个重要的参数:
- 窗口长度/大小
- 窗口的滑动间隔
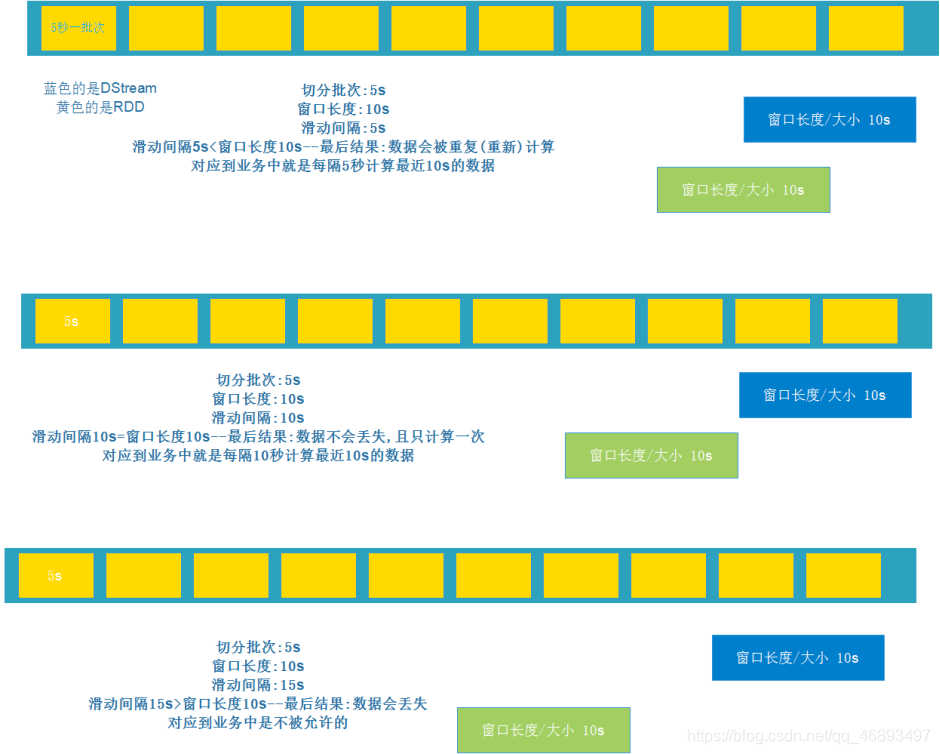
- 3.总结:
- 通过上面的学习我们知道
- 窗口函数可以完成 每隔xx时间( 滑动间隔)计算最近xx时间( 窗口长度/大小)的数据
- 那么就说涉及到2个参数: 窗口长度/大小, 滑动间隔
- 而窗口长度/大小, 滑动间隔之间的大小关系有3种:
- 滑动间隔5<窗口长度/大小10 , 每隔5s计算最近10s的数据, ok,用的较多,大部分都是这种情况
- 滑动间隔10=窗口长度/大小10 每隔10s计算最近10s的数据, ok,但是用的少
- 滑动间隔15=窗口长度/大小10 每隔15s计算最近10s的数据, 不行,中间会有5s的数据丢失
- 4.代码演示
- 每隔5S计算最近10S的数据的WordCount
package cn.hanjiaxiaozhi.stream
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{
Minutes, Seconds, StreamingContext}
import org.apache.spark.{
SparkConf, SparkContext}
/**
* Author hanjiaxiaozhi
* Date 2020/7/25 15:37
* Desc 使用SparkStreaming监听node01:9999发送的实时数据并做WordCount,每隔5S计算最近10S的数据的WordCount
*/
object WordCount4 {
def main(args: Array[String]): Unit = {
//1.准备环境
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))//每隔5s对数据划分一个批次,形成一个个的RDD
//2.监听node01:9999端口的数据
val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//3.处理数据做WordCount
val wordsDStream: DStream[String] = dataDStream.flatMap(_.split(" "))
val wordAndOneDStream: DStream[(String, Int)] = wordsDStream.map((_,1))
//val resultDStream: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_+_)
/* 使用reduceByKeyAndWindow完成每隔5S(滑动间隔)计算最近10S(窗口大小)的数据
* @param windowDuration 窗口大小
* @param slideDuration 滑动间隔
* must be a multiple of this DStream's batching interval
* 必须是微批划分时间间隔的整数倍
*/
val resultDStream: DStream[(String, Int)] = wordAndOneDStream.reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Seconds(10),Seconds(5))
//以后公司中做业务开发根据需求设置参数大小进行统计即可
//如:每隔1分钟(滑动间隔),计算最近1小时(窗口大小)的各个广告位的点击量(后可能要做广告位分时定价)
//wordAndOneDStream.reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Minutes(60),Minutes(1))
//4.输出结果
resultDStream.print()
//5.启动并等待结束
ssc.start()
ssc.awaitTermination()
}
}
案例5-新闻热搜排行榜
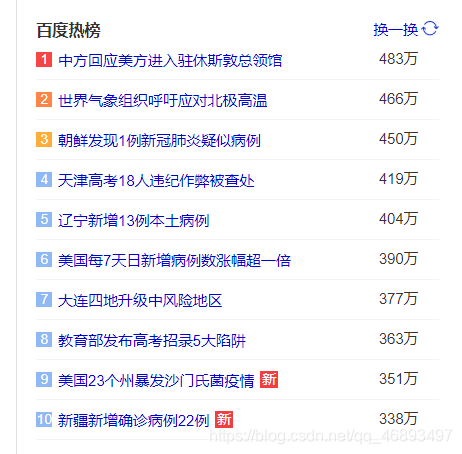
-
每隔5S计算最近10S的热搜词汇排行榜…
-
或者实际中每隔10分钟计算最近24小时的热搜词汇排行榜…
-
其他的:
-
每隔xx时间统计最近xx时间的数据(订单/搜索/…)
-
如:每隔1分钟(滑动间隔),计算最近1小时(窗口大小)的各个广告位的点击量(后可能要做广告位分时定价)
-
wordAndOneDStream.reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Minutes(60),Minutes(1))
-
代码实现
package cn.hanjiaxiaozhi.stream
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{
DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{
Seconds, StreamingContext}
import org.apache.spark.{
SparkConf, SparkContext, rdd}
/**
* Author hanjiaxiaozhi
* Date 2020/7/25 15:37
* Desc 使用SparkStreaming监听node01:9999发送的实时数据并做WordCount,每隔5S计算最近10S的热搜词汇排行榜
*/
object WordCount5 {
def main(args: Array[String]): Unit = {
//1.准备环境
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))//每隔5s对数据划分一个批次,形成一个个的RDD
//2.监听node01:9999端口的数据
val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//3.处理数据做WordCount
val wordsDStream: DStream[String] = dataDStream.flatMap(_.split(" "))
val wordAndOneDStream: DStream[(String, Int)] = wordsDStream.map((_,1))
/* 使用reduceByKeyAndWindow完成每隔5S计算最近10S的热搜词汇排行榜
* @param windowDuration 窗口大小
* @param slideDuration 滑动间隔
* must be a multiple of this DStream's batching interval
* 必须是微批划分时间间隔的整数倍
*/
//每隔5S计算最近10S的热搜词汇排行榜
val wordAndCountDStream: DStream[(String, Int)] = wordAndOneDStream.reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Seconds(10),Seconds(5))
//注意上面的wordAndCountDStream只是每隔5S计算最近10S的WordCount,还没有排序
//接下来要对上面的数据进行排序,但是DStream没有排序方法
//而我们要对DStream中的RDD中的数据进行排序,所以将对DStream的排序转换为对里面的RDD中的数据进行排序
//所以接下来可以调用一个transform方法,表示作用于DStream中的各个RDD,可以是任意的操作,从而返回一个新的RDD
val sortedDStream: DStream[(String, Int)] = wordAndCountDStream.transform(rdd => {
//排序
val sortedRDD: RDD[(String, Int)] = rdd.sortBy(_._2, false) //_._2表示按照单词数量进行排序,false表示逆序
//取排好序的前N个词汇
println("====top3热搜词-start====")
sortedRDD.take(3).foreach(println)
println("====top3热搜词-end====")
sortedRDD
})
//4.输出结果
sortedDStream.print()//这句不能省略,因为需要Output/Action操作 // No output operations registered, so nothing to execute
//5.启动并等待结束
ssc.start()
ssc.awaitTermination()
}
}
/*
中方回应美方进入驻休斯敦总领馆 中方回应美方进入驻休斯敦总领馆 中方回应美方进入驻休斯敦总领馆 中方回应美方进入驻休斯敦总领馆
世界气象组织呼吁应对北极高温 世界气象组织呼吁应对北极高温
朝鲜发现1例新冠肺炎疑似病例 朝鲜发现1例新冠肺炎疑似病例 朝鲜发现1例新冠肺炎疑似病例 朝鲜发现1例新冠肺炎疑似病例 朝鲜发现1例新冠肺炎疑似病例
天津高考18人违纪作弊被查处
辽宁新增13例本土病例
*/