学习过程跟进黑皮书《数据结构与算法分析》,主要代码大致与树种例程相同,若有疏漏或错误,请务必提醒我,我会尽力修正。
二项队列Binomial Queue:(以下不只是简介,还包括了一些个人理解,如果您学习过程遇到什么麻烦,不妨先看看)
根据书上的描述,似乎是左式堆的一种改良版。虽然左式堆和斜堆每次操作都花费logN时间,且有效支持了插入、合并与最小值出堆,但其每次操作花费常数平均时间来支持插入。而在二项队列中。每次操作的最坏情况运行时间为logN,而插入操作平均花费常数时间。这算是在一定程度上优化了斜堆。
其结构就如名字一样,是“二项”。我们可以将其简单理解为“上项”和“下项”(这只是为了方便理解罢了,实际运用中自然不存在这种称呼,但我总要找个名字给它,不然描述起来还挺费劲的)。实际的样子当您看到图片的时候就能明白,我为什么要那样称呼它们了。
并且,二项队列的样子也特殊一点。它是一种被称之为“森林”的结构,形象的说,它包括了许多中不同高度的二叉树(但每一种高度的树只有一颗,一旦出现两颗同样高度,它们就会被立刻合并成新的高度,这也是特色之一)。并且,它也有最小堆的特性,关键字的数值随高度递减,每一个根节点的值都比子树中任何一个节点的关键字小。
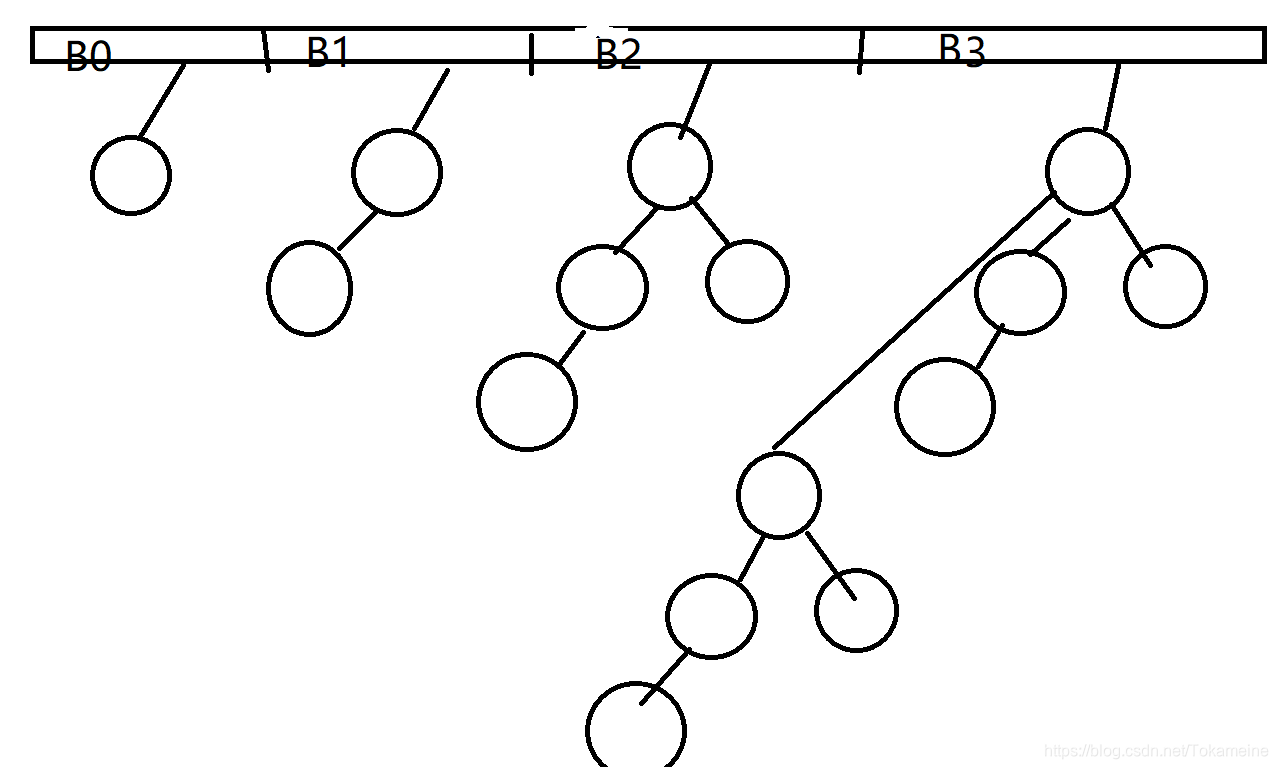
如图,这便算是一个简单的二项队列结构。上面是一个数组,数组中存放有指针。而下面的则是许多的树(剥去数组,你看到的才是真正的二项队结构,数组只是从计算机中实现的一种方法罢了。并且,B3中的那颗树和我们实际实现的有些不同,具体的情况后面会写。但目前,权且当它就长这个样吧(或许这才是本该有的结构,但计算机不方便这样做,所以之后会有另外一个实现的样子))
//-------------声明部分---------------//
typedef struct BinNode* Position;//位置指针
typedef struct BinNode* BinTree;//树指针
typedef struct Collection* BinQueue;//队列指针
#define MaxTrees 5 //数组的长度,也同时规定了二叉树的高度
#define Capacity ((1<<MaxTrees)-1)//容量是2^0+2^1+......+2^(MAXTREES-1)
BinQueue Initialize(void);//建立空队列
BinTree CombineTrees(BinTree T1, BinTree T2);//合并高度相同的树
BinQueue Merge(BinQueue H1, BinQueue H2);//合并两个队列
int DeleteMin(BinQueue H);
void Insert(int X, BinQueue H);
int IsEmpty(BinQueue H);
struct BinNode //树节点
{
int Key;
Position LeftChild;
Position NextSibling;
};
struct Collection //森林
{
int CurrentSize; //已容纳量
BinTree TheTrees[MaxTrees];//容纳二叉树的数组
};
//-------------声明部分---------------//因为书上没有说明一些变量的作用,所以我自己绕了一会,在这里顺便说明一下吧:
CurrentSize:已容纳量。指的是整个队列的节点数。比方说上图中的的容纳量就是15(对应总共15个节点)。
Capacity:队列容量。指的是一个二项队列结构最高能容纳的节点数。比方说上图的队列容量就是(B3——15)(也因为我画的不太好,所以B3看起来高度不像3,但会意一下就行,实在不行去找找其他大佬的图也行)。(但写法是一个等比数列求和结果,很明显,每个高度的节点数是等比增加的)
LeftChild/NextSibling:连接指针。这个东西具体到后面看见实际的图片时,自然会懂。
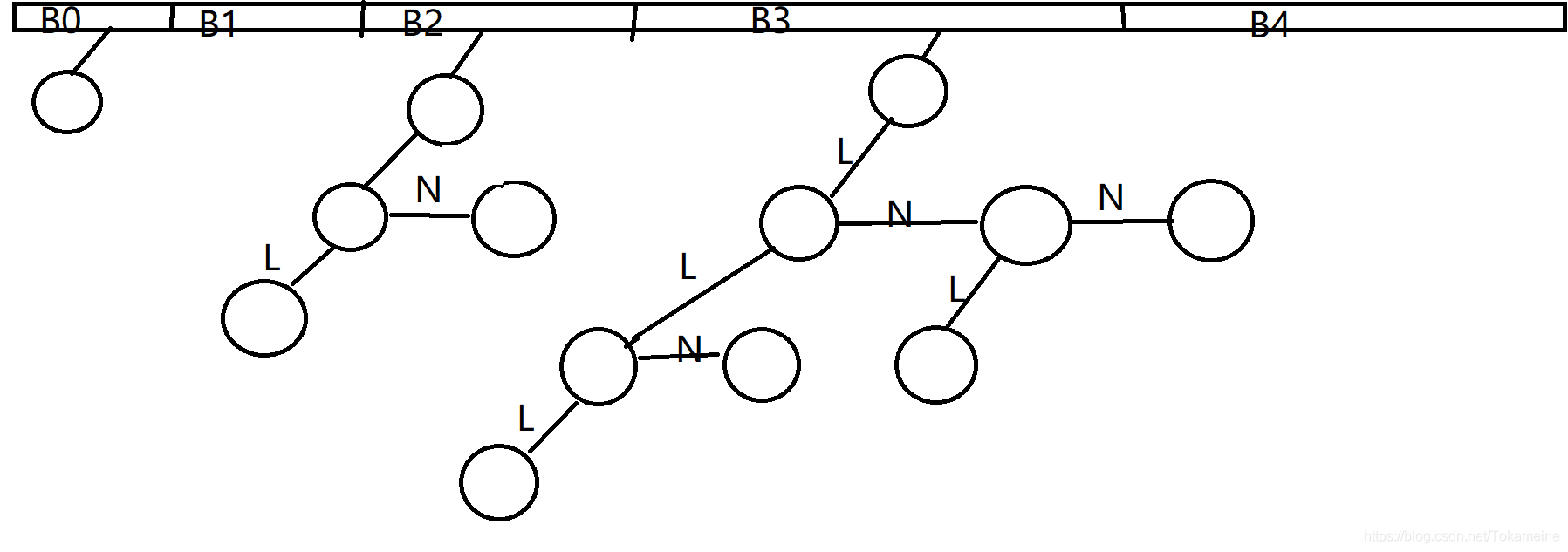
这幅图为实际做出的结构,以下说明的时候请经常对照以方便理解。高度相同的节点我已经尽量画在同一水平线了,也如您所见,B1没有节点,B3的高度确实是3(建立在B0处的节点高度设定为0的基础上)。
关于LeftChild和NextSibling指针已经标出(取首字母表示)。
建立队列Initialize:
BinQueue Initialize(void)
{
BinQueue H = new Collection;
for (int i = 0; i < MaxTrees; i++)
H->TheTrees[i] = NULL;
H->CurrentSize = 0;
return H;
}没什么好说的,但因为书上没有,加上我当时不太明白几个参数的作用,所以绕了好一会,贴在这里以防万一。(至少如果不明白CurrentSize是什么,就没办法让它等于0了......)
插入节点Insert:
void Insert(int X, BinQueue H)
{
BinQueue temp = initialize();
temp->CurrentSize = 1;
temp->TheTrees[0] = new BinNode;
temp->TheTrees[0]->Key = X;
temp->TheTrees[0]->LeftChild = NULL;
temp->TheTrees[0]->NextSibling = NULL;
Merge(H, temp);
delete temp;
}从这个函数可以看出,所谓的插入节点,实际上是将新节点当作了一个只有B0结构的二项队列,然后将其合并。目前,我们只需要将Merge函数视作一个合并二项队列的函数即可,关于这个函数会在下面讲到。
最小值出队DeleteMin:
int DeleteMin(BinQueue H)
{
int i, j;
int MinTree;
BinQueue DeleteQueue;
Position DeleteTree, OldRoot;
int MinItem;//ElementType
if (IsEmpty(H))
return NULL;
MinItem=INFINITY;
for (i = 0; i < MaxTrees; i++)
{
if (H->TheTrees[i] && H->TheTrees[i]->Key < MinItem)
{
MinItem = H->TheTrees[i]->Key;
MinTree = i;
}
}
DeleteTree = H->TheTrees[MinTree];
OldRoot = DeleteTree;
DeleteTree = DeleteTree->LeftChild;
delete OldRoot;
DeleteQueue = initialize();
DeleteQueue->CurrentSize = (1 << MinTree) - 1;
for (j = MinTree - 1; j >= 0; j--)
{
DeleteQueue->TheTrees[j] = DeleteTree;
DeleteTree = DeleteTree->NextSibling;
DeleteQueue->TheTrees[j]->NextSibling = NULL;
}
H->TheTrees[MinTree] = NULL;
H->CurrentSize -= (DeleteQueue->CurrentSize + 1);
Merge(H, DeleteQueue);
return MinItem;
}
函数本身不算难,但有些冗长。姑且做些说明,但自己写出来是最有效的理解方式。
①一系列将要用到的声明。其中MinItem是将要出堆的Key(因为我设定的Key是int类型),再将MinItem设定为无限大(Infinity)。
②遍历队列数组,选出队列中最小的关键字节点。用MinTree标记其对应的索引,MinItem拷贝其数值。
③将标记好的最小值节点拷贝到DeleteTree与OldRoot,再把DeleteTree指向其左儿子。删除最小值节点。
④将刚才拷贝的左儿子新建到另外一个队列里,设定好相关的数值,最后把两个队列合并。
值得注意的是,for循环是将失去了根节点的堆重新整合到新队列中。这个操作看起来有些抽象,但实际上是可行的。不妨带入B3节点来试探一下,删去了根节点后,它被拆分成了B0,B1,B2三棵树进入新队列了。最开始的那幅图其实很好的说明了问题,那张图的B3有这明显的复制粘贴B2的痕迹,但事实就如描述一样,它们真的就是像复制粘贴一样的结构。所有你可以试着去拆分一下,Bk去掉根节点必然会变成B0,B1,B2......Bk-1颗树。
以及另外一个注意点:
H->CurrentSize -= (DeleteQueue->CurrentSize + 1);
其实不太必要在这个地方纠结太久,但以防万一还是说明一下。这行代码减去的数量将在Merge函数中补齐,先后的总节点数差距确实是 1 ,可以自行验证一下。如果缺乏这条函数,Merge将会导致CurrentSize与实际不符。(之所以减去那个量,是因为Merge会补回DeleteQueue->CurrentSize的数量,和这段语句正好相差 1 )
合并队列Merge:
BinTree CombineTrees(BinTree T1,BinTree T2)
{
if (T1->Key > T2->Key)
return CombineTrees(T2, T1);
T2->NextSibling = T1->LeftChild;
T1->LeftChild = T2;
return T1;
}
BinQueue Merge(BinQueue H1,BinQueue H2)
{
BinTree T1, T2, Carry = NULL;
int i,j;
if (H1->CurrentSize + H2->CurrentSize > Capacity)
exit;
H1->CurrentSize += H2->CurrentSize;
for (i = 0, j = 1; j <= H1->CurrentSize; i++, j *= 2)
{
T1 = H1->TheTrees[i]; T2 = H2->TheTrees[i];
switch(!!T1+2*!!T2+4*!!Carry)
{
case 0://No tree
case 1://only h1
break;
case 2://only h2
H1->TheTrees[i] = T2;
H2->TheTrees[i] = NULL;
break;
case 4://only carry
H1->TheTrees[i] = Carry;
Carry = NULL;
break;
case 3://h1 and h2
Carry = CombineTrees(T1, T2);
break;
case 5://h1 and carry
Carry = CombineTrees(T1,Carry);
H1->TheTrees[i] = NULL;
break;
case 6://h2 and carry
Carry = CombineTrees(T2,Carry);
H2->TheTrees[i] = NULL;
break;
case 7://h1 and h2 and carry
H1->TheTrees[i] = Carry;
Carry = CombineTrees(T1,T2);
H2->TheTrees[i] = NULL;
break;
}
}
return H1;
}
最后是关键性的函数,Merge。这个例程还需要用到CombineTrees函数,用于合并高度相同的树。
函数本身并不是很复杂,用了一个switch来判断情况,这个方式相当有趣,是很值得学习的一种想法。(!!符号似乎是用来判断存在性的(我不太清楚这样描述对不对,所有用“似乎”),若值存在且非0,则返回1,否则返回0)。
以及比较有趣的是for循环的判断条件 j<=H1->CurrentSize 和 j*=2
看起来有些抽象,解释起来也是。
现在的H1->CurrentSize已经是合并结束后的总节点数量了,而这个数量直接关系到for循环需要抵达哪一个高度的数组格。(比如说,我的数组最高能到B20,但现在根本没有那么多树需要存放,最高的树高度只到B5,那如果全都扫一遍,岂不是浪费了很多时间?)
所有才有 j*=2这个条件来制约。如您所见,每个高度的节点数实际上是固定的 2^Bk(2的Bk次方,k指高度,如B0,B1等)。这就涉及到了一些数学关系,所有我就不写这了。只需要捋一捋,我想很快就会发现这神奇的操作(如果最高到B5,那这个for循环进行4次之后,它的 j 就会超出范围导致for循环终止)。
流程其实没必要细讲了,函数写的很清楚了,注释也有,笔记的目的已经达成了,那就到这吧。